Il confronto dei dati in SQL è un'attività comune che ogni sviluppatore di database incontra occasionalmente. Fortunatamente, il confronto dei dati è disponibile in un'ampia varietà di formati come confronto letterale, confronto booleano, ecc.
Tuttavia, uno degli scenari di confronto dei dati reali che potresti incontrare è il confronto tra due tabelle. Svolge un ruolo cruciale in attività quali la convalida dei dati, l'identificazione degli errori, la duplicazione o la garanzia dell'integrità dei dati.
In questo tutorial esploreremo tutti i vari metodi e tecniche che possiamo utilizzare per confrontare due tabelle di database in SQL.
Impostazione dei dati di esempio
Prima di approfondire ciascuno dei metodi, impostiamo una configurazione dei dati di base a scopo dimostrativo.
Abbiamo due tabelle con dati di esempio come mostrato nell'esempio.
Tabella di esempio 1:
Di seguito sono riportate le query per creare la prima tabella e inserire i dati di esempio nella tabella:
CREA TABELLA campione_tb1 (
Employee_id INT CHIAVE PRIMARIA AUTO_INCREMENT,
nome VARCHAR ( cinquanta ) ,
cognome VARCHAR ( cinquanta ) ,
dipartimento VARCHAR ( cinquanta ) ,
stipendio DECIMALE ( 10 , 2 )
) ;
INSERISCI IN sample_tb1 ( nome, cognome, dipartimento, stipendio )
VALORI
( 'Penelope' , 'Caccia' , 'risorse umane' , 55000,00 ) ,
( 'Matteo' , 'Gabbia' , 'ESSO' , 60000,00 ) ,
( 'Jeniffer' , 'Davis' , 'Finanza' , 50000,00 ) ,
( 'Kirsten' , 'Fawcet' , 'ESSO' , 62000,00 ) ,
( 'Cameron' , 'Costner' , 'Finanza' , 48000,00 ) ;
Questo dovrebbe creare una nuova tabella chiamata 'sample_tb1' con varie informazioni come nomi, dipartimento e stipendio.
La tabella risultante è la seguente:

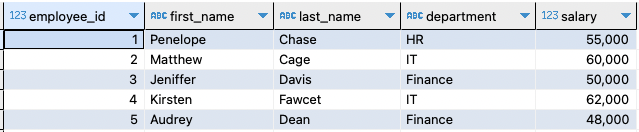
Tabella di esempio 2:
Procediamo e creiamo due tabelle di esempio. Supponiamo che questa sia una copia di backup della prima tabella. Possiamo creare la tabella e inserire dati di esempio come mostrato di seguito:
CREA TABELLA campione_tb2 (Employee_id INT CHIAVE PRIMARIA AUTO_INCREMENT,
nome VARCHAR ( cinquanta ) ,
cognome VARCHAR ( cinquanta ) ,
dipartimento VARCHAR ( cinquanta ) ,
stipendio DECIMALE ( 10 , 2 )
) ;
INSERISCI IN sample_tb2 ( nome, cognome, dipartimento, stipendio )
VALORI
( 'Penelope' , 'Caccia' , 'risorse umane' , 55000,00 ) ,
( 'Matteo' , 'Gabbia' , 'ESSO' , 60000,00 ) ,
( 'Jeniffer' , 'Davis' , 'Finanza' , 50000,00 ) ,
( 'Kirsten' , 'Fawcet' , 'ESSO' , 62000,00 ) ,
( 'Audrey' , 'Decano' , 'Finanza' , 48000,00 ) ;
Questo dovrebbe creare una tabella e inserire i dati di esempio come specificato nella query precedente. La tabella risultante è la seguente:
Confronta due tabelle utilizzando Except
Uno dei modi più comuni per confrontare due tabelle in SQL è utilizzare l'operatore EXCEPT. Ciò trova le righe che esistono nella prima tabella ma non nella seconda tabella.
Possiamo usarlo per eseguire un confronto con le tabelle di esempio come segue:
SELEZIONARE *DA campione_tb1
TRANNE
SELEZIONARE *
DA campione_tb2;
In questo esempio, l'operatore EXCEPT restituisce tutte le righe distinte della prima query (sample_tb1) che non compaiono nella seconda query (sample_tb2).
Confronta due tabelle utilizzando l'Unione
Il secondo metodo che possiamo utilizzare è l'operatore UNION insieme alla clausola GROUP BY. Ciò aiuta a identificare i record presenti in una tabella, non nell'altra, preservando i record duplicati.
Prendi la query mostrata di seguito:
SELEZIONAREID Dipendente,
nome di battesimo,
cognome,
Dipartimento,
stipendio
DA
(
SELEZIONARE
ID Dipendente,
nome di battesimo,
cognome,
Dipartimento,
stipendio
DA
campione_tb1
UNIONE TUTTI
SELEZIONARE
ID Dipendente,
nome di battesimo,
cognome,
Dipartimento,
stipendio
DA
campione_tb2
) AS dati_combinati
RAGGRUPPA PER
ID Dipendente,
nome di battesimo,
cognome,
Dipartimento,
stipendio
AVENDO
CONTARE ( * ) = 1 ;
Nell'esempio fornito, utilizziamo l'operatore UNION ALL per combinare i dati di entrambe le tabelle mantenendo i duplicati.
Utilizziamo quindi la clausola GROUP BY per raggruppare i dati combinati in base a tutte le colonne. Infine, utilizziamo la clausola HAVING per garantire che vengano selezionati solo i record con un conteggio pari a uno (senza duplicati).
Produzione:

Questo metodo è un po' più complesso ma fornisce informazioni molto migliori quando si ottengono i dati effettivi mancanti in entrambe le tabelle.
Confronta due tabelle utilizzando INNER JOIN
Se ci hai pensato, perché non utilizzare un INNER JOIN? Saresti perfetto. Possiamo utilizzare un INNER JOIN per confrontare le tabelle e trovare i record comuni.
Prendiamo ad esempio la seguente query:
SELEZIONAREcampione_tb1. *
DA
campione_tb1
INNER JOIN sample_tb2 ATTIVO
campione_tb1.employee_id = campione_tb2.employee_id;
In questo esempio utilizziamo un SQL INNER JOIN per trovare i record esistenti in entrambe le tabelle in base a una determinata colonna. Sebbene funzioni, a volte può essere fuorviante poiché non si è sicuri se i dati siano effettivamente mancanti o presenti in entrambe le tabelle o solo in una.
Conclusione
In questo tutorial abbiamo appreso tutti i metodi e le tecniche che possiamo utilizzare per confrontare due tabelle in SQL.