- Non sovrascrive i dati recuperati ma colma le lacune in caso di ripristino iterativo. Tuttavia, può essere troncato se allo strumento viene richiesto di farlo in modo esplicito.
- Recupera i dati in un singolo file da più file o blocchi.
- Supporta più tipi di interfacce di dispositivi come unità SATA, ATA, SCSI, MFM, dischi floppy e schede SD.
In questa guida esplorerò questo strumento di recupero dati incredibilmente utile. Discuterò anche del processo di installazione e di come utilizzarlo per ripristinare un dispositivo a blocchi o una partizione.
- Installazione di ddrescue
- Comprendere le nozioni di base
- Considerazioni importanti
- Utilizzando ddrescue
- Recupero del blocco danneggiato
- Ripristinare il file immagine in un nuovo blocco
- Recupero del blocco su un altro blocco
- Recupero di dati specifici dai file di immagine recuperati
- Funzionalità avanzate
- Come funziona ddrescue
- Conclusione
Nota: Sto utilizzando la distribuzione Linux (Ubuntu 22.04) per le istruzioni contenute in questa guida. Il processo di installazione dell'utilità ddrescue potrebbe differire, ma le istruzioni saranno le stesse per tutte le distribuzioni Linux.
Installazione di ddrescue
Per installare ddrescue su Linux, in particolare Ubuntu e i suoi sapori o Basato su Debian distribuzioni, utilizzare:
sudo adatto installare gddrescue
Per installarlo REHL , Fedora , E CentOS , abilitare prima il CALDO (Pacchetti extra per Enterprise Linux).
sudo gnam installa rilascio caldo
Il comando precedente è per le versioni più recenti della rispettiva distribuzione.
Quindi eseguire il comando seguente per installare ddrescue:
sudo gnam installa ddrescuePer distribuzioni Linux basate su Arch come Arch-Linux E Manjaro , utilizzare il comando indicato di seguito per installare l'utilità di ripristino ddrescue.
sudo pacman -S ddrescue
Dato che utilizzo Ubuntu 22.04, utilizzerò il gestore pacchetti APT per installarlo.
Comprendere le nozioni di base
Prima di utilizzare lo strumento ddrescue per ripristinare i dati, consiglierei agli utenti che sono nuovi al processo di ripristino di comprendere alcune convenzioni di denominazione di Linux.
Linux riconosce i blocchi (dispositivi) come file e li inserisce nel file /dev directory. Per elencare i file nella directory /dev, utilizzare il file ls /dev comando.
IL dischi fissi (blocchi di archiviazione) sono rappresentati con SD seguito da alfabeti; nel caso di più dispositivi di archiviazione i file verranno rappresentati come /dev/sd UN, /dev/sd B, e così via.
Se il dispositivo di archiviazione ha partizioni , allora saranno rappresentati da un numero con il rispettivo nome del file dell'unità, come /dev/sda 1 , /dev/sda 2 , e così via.
Per elencare tutti i blocchi e gli altri dispositivi collegati al sistema, utilizzare il blocco elenco lsblk comando:
lsblk 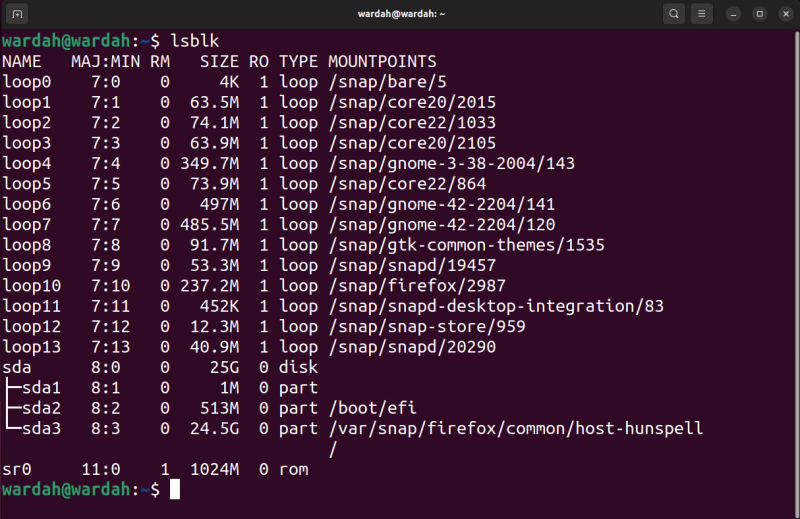
Il comando ddrescue può ripristinare l'intero blocco (contenente MBR e partizioni) o anche una partizione. D'altra parte, se è necessario ripristinare solo file specifici da una partizione specifica, è meglio ripristinare la partizione anziché l'intero blocco.
Considerazioni importanti
Prima di utilizzare l'utilità ddrescue, è necessario considerare alcuni punti chiave:
- Non tentare di ripristinare un blocco montato, il blocco non dovrebbe essere nemmeno in modalità di sola lettura.
- Non tentare di riparare un blocco con errori I/O.
- Il sistema può modificare i nomi dei dispositivi di input e output al riavvio. Assicurarsi che i nomi dei dispositivi siano corretti prima di iniziare il processo di copia.
- Se si utilizza un blocco separato come dispositivo di output, tutti i dati presenti sul dispositivo verranno sovrascritti.
Utilizzando ddrescue
Dopo aver installato l'utilità ddrescue e compreso le convenzioni di denominazione, il passaggio successivo consiste nell'identificare il disco guasto e ripristinarlo utilizzando lo strumento ddrescue.
Recupero del blocco danneggiato
Il primo esempio comprenderà il processo di ripristino dell'intero blocco. Innanzitutto, elenca i blocchi utilizzando il file lsblk comando:
lsblk -O NOME, TAGLIA, TIPO FIL -O flag viene utilizzato per specificare quale tipo di informazioni (campi) deve essere restituito dal comando. Ho menzionato il NOME , MISURARE , E FSTYPE o tipo di file system.
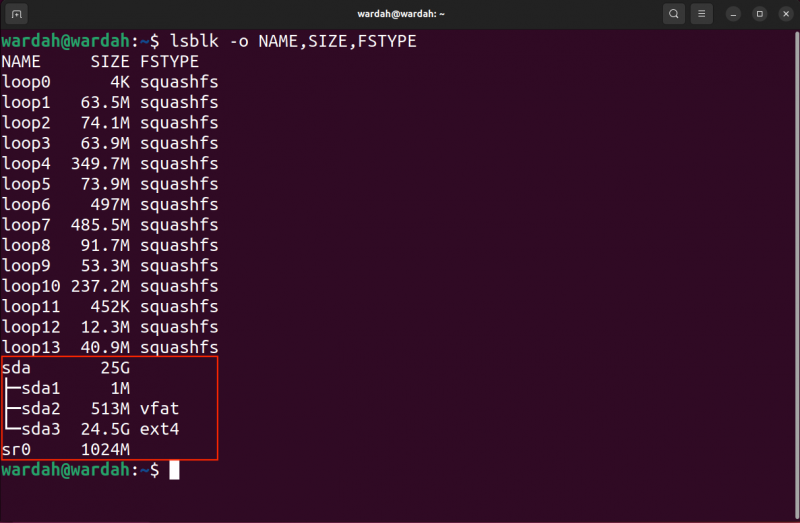
Ora puoi identificare il blocco di destinazione, la partizione e la posizione in cui salvare il file immagine salvato.
Un'altra cosa importante da notare è che su Linux il nome del blocco viene assegnato dinamicamente all'avvio e dopo il riavvio i nomi dei blocchi potrebbero cambiare. Quindi, fai attenzione mentre annoti i nomi dei blocchi.
Ora utilizza la seguente sintassi per salvare il blocco come file immagine con un file di registro nella directory principale.
sudo ddrescue -D -rX / dev / [ bloccare ] [ sentiero / nome ] .img [ nome_filelog ] .tronco d'alberoNota: Sostituire [bloccare] , [percorso/nome] del file immagine e [nome_filelog] con i nomi preferiti di conseguenza.
In questo esempio, sto recuperando il file /dev/sda nella directory principale con il nome del file immagine recupero.img . Il file di registro, noto anche come file di mappa, è essenziale se si desidera riprendere il ripristino in qualsiasi momento.
sudo ddrescue -D -r2 / dev / sda2 ripristino.img ripristino.logNel comando precedente vengono utilizzati due flag importanti.
| D | –indiretto | Viene utilizzato per indicare allo strumento di accedere direttamente al disco ignorando la cache del kernel |
| rX | –retry-pass | Viene utilizzato per indicare allo strumento di riprovare il settore danneggiato un numero X di volte |
Eseguendo il comando precedente, noterai due file che appaiono nel browser dei file con i nomi recupero.img E ripristino.log .
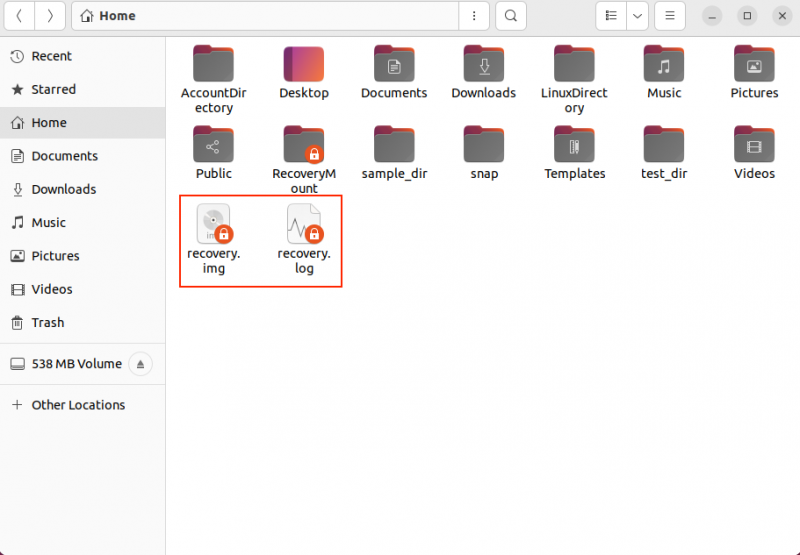
Il tempo di recupero dipende dalla dimensione del blocco di input e dal danno. Se stai recuperando un blocco di grandi dimensioni, ti consiglio di avere un file di registro perché potrebbero essere necessarie diverse ore o addirittura giorni per completare il processo.
L'output del comando precedente è riportato di seguito:
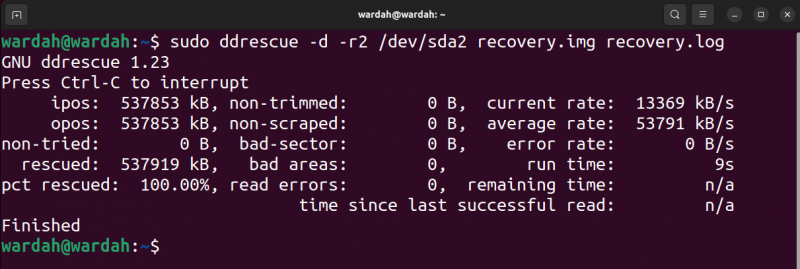
Nell'immagine di output, ipo è la posizione di input del file di input da cui viene iniziata la copia e il file ulcere è la posizione di output sul file di output in cui vengono scritti i dati.
IL non provato è la dimensione del blocco che non è in attesa di essere provata. IL salvato indica la dimensione del blocco recuperato con successo. IL pct salvato indica il recupero riuscito dei dati in percentuale. I termini, non tagliato , non rottamato , settore danneggiato , E zone difettose sono autoesplicativi. comunque, il errori di lettura il termine indica i tentativi di lettura non riusciti in numeri.
IL tempo di esecuzione mostra il tempo impiegato dallo strumento per completare il processo, mentre il tempo rimanente è il tempo rimanente per completare il processo di recupero. L'output sopra mostra il tempo rimanente 0 perché il processo è terminato, leggi l'output nell'immagine seguente di un processo non terminato.
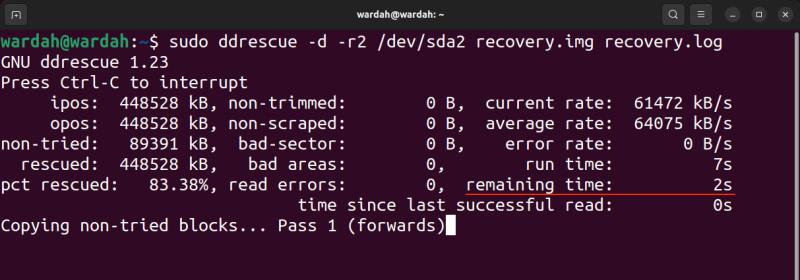
Vediamo cosa otteniamo nel file di log; per aprire il file di registro generato, utilizzare il file vim ripristino.log comando.
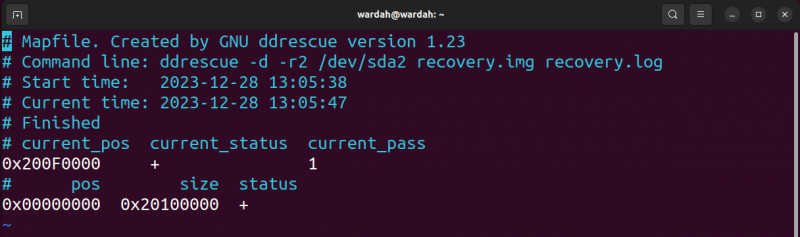
IL stato attuale è + che significa che il processo è terminato, mentre il pos_corrente è la posizione sul blocco.
Un elenco degli stati attuali è riportato nella tabella seguente:
| ? | Copiare |
| * | Rifinitura |
| / | Demolizione |
| – | Nuovo tentativo |
| F | Riempiendo i blocchi specificati |
| G | Generazione del file di registro |
| + | Il processo è terminato |
Al di sotto di questo, il file di registro contiene indicazioni sullo stato dei blocchi precedentemente salvati sotto forma di caratteri elencati di seguito:
| ? | Il blocco non è stato provato |
| * | Il blocco fallito non tagliato |
| / | Il blocco non eliminato non riuscito |
| – | Il blocco del settore danneggiato non è riuscito |
| + | Blocco finito |
Ripristinare il file immagine in un nuovo blocco
Una volta terminato il processo di ripristino e ottenuto il file immagine. Ora potresti volerlo spostare sulla nuova unità da un'unità danneggiata. Per spostare il file immagine in un nuovo blocco, connettere innanzitutto il blocco al sistema e quindi identificare il nome del blocco utilizzando il file lsblk comando.
Supponiamo che lo sia /dev/sdb , utilizzare il comando seguente per copiare l'immagine in un nuovo blocco.
sudo ddrescue -F recupero.img / dev / sdb file di registro.logIL -F flag viene utilizzato per sovrascrivere il nuovo blocco se sono presenti dati. Tieni presente che il nome del file di registro deve essere diverso per mantenerlo separato dal file di registro precedentemente archiviato.
L'operazione di cui sopra può essere eseguita anche utilizzando il gg , un altro potente comando utilizzato per copiare i file.
sudo gg Se =recupero.img Di = / dev / sdbPrima di effettuare un ripristino, tieni presente che il nuovo blocco deve essere abbastanza grande da conservare l'intero blocco recuperato; ad esempio, se il blocco di ripristino è di 5 GB, il nuovo blocco dovrebbe essere maggiore di 5 GB.
Se il file immagine recuperato presenta molti errori, è possibile ripararli utilizzando il file fsck comando su Linux in una certa misura. Mentre su Windows, puoi utilizzare il file CHKDSK O SFC comandi per farlo. Tuttavia, il ripristino dipende dal numero di errori generati dal file danneggiato.
Ora il processo di recupero e ripristino è terminato. Un'altra cosa importante da notare è che puoi recuperare un blocco danneggiato direttamente su un altro blocco, invece di creare un file immagine e poi copiarlo sul nuovo blocco. Bene, nella sezione successiva tratterò questo processo in dettaglio.
Recupero del blocco su un altro blocco
Per ripristinare un blocco direttamente in un nuovo blocco, collegare prima il blocco al sistema e utilizzarlo nuovamente lsblk comando per identificare il nome del blocco. Nomi di blocco errati possono rovinare l'intero processo e potresti perdere dati.
Dopo aver identificato il blocco di origine e quello di destinazione, utilizzare il comando seguente per recuperare il blocco:
sudo ddrescue -D -F -r2 / dev / [ fonte ] / dev / [ destinazione ] backup.logAssumiamo /dev/sdb è il blocco di destinazione, quindi per copiare il file /dev/sda directory nel nuovo blocco utilizzare:
sudo ddrescue -D -F -r2 / dev / sda / dev / sdb backup.logAncora una volta, vedere le considerazioni critiche menzionate nelle sezioni precedenti prima di tentare questo processo.
Recupero di dati specifici dai file di immagine recuperati
In molti casi, lo scopo del ripristino dei dati è trovare file specifici dalle unità danneggiate. Per accedere al file specifico è necessario montare il file immagine. Su Linux, il file immagine recuperato può essere esplorato utilizzando il file montare comando.
Prima di montare il file immagine, crea una cartella o directory in cui desideri estrarre il contenuto del file immagine.
mkdir RecoveryMountSuccessivamente, monta il file immagine utilizzando:
sudo montare -O ripristino del ciclo.img ~ / RecoveryMountIl flag -o indica le opzioni, mentre l'opzione loop viene utilizzata per trattare il file immagine come un dispositivo a blocchi.
Ora hai accesso al contenuto del file immagine, come mostrato nello screenshot seguente.
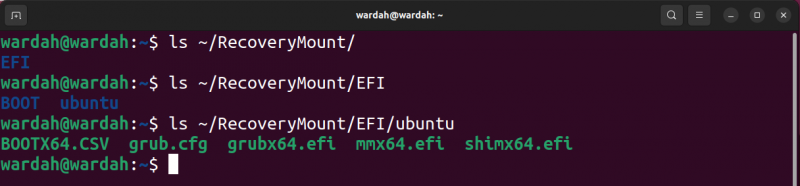
Per smontare il blocco, utilizzare il file smontare comando.
sudo smontare ~ / RecoveryMountFunzionalità avanzate
Per avviare il ripristino da un punto specifico, utilizzare il file -io bandiera o –posizione-input . Dovrebbe essere in byte, per impostazione predefinita lo è 0 byte. Questo è importante per riprendere la copia da un punto specifico. Ad esempio, se desideri iniziare il processo di copia dal punto da 10 GB, utilizza il comando seguente.
sudo ddrescue -i10GiB / dev / sda fileimmagine.img filelog.logPer definire la dimensione massima del dispositivo di input, il -S verrà utilizzata la bandiera IL -S indica la dimensione e può essere utilizzato anche come -misurare in byte. Se lo strumento non riesce a riconoscere la dimensione del file di input, utilizza questa opzione per specificarla.
sudo ddrescue -s10GiB / dev / sda fileimmagine.img filelog.logIL -chiedere può essere molto utile, poiché richiede la conferma dei blocchi di input e output prima di iniziare il processo di copia. Come discusso in precedenza, il sistema assegna dinamicamente i nomi ai blocchi e questi cambiano al riavvio. Quindi, in tal caso, questa opzione può essere utile.
sudo ddrescue --chiedere / dev / sda fileimmagine.img filelog.logInoltre, di seguito è riportato un elenco di alcune altre opzioni:
| -R | -inversione | Per invertire la direzione della copia |
| -Q | -abbastanza | Per sopprimere tutti i messaggi di output |
| -In | –verboso | Per elaborare, tutti i messaggi di output |
| -P | –preallocate | Per preallocare spazio di archiviazione per il file di output |
| -P | –anteprima-dati | Le righe di visualizzazione degli ultimi dati letti per impostazione predefinita sono 3 righe |
Come funziona ddrescue
Il ddrescue utilizza un potente algoritmo di recupero suddiviso in quattro fasi:
1. Copia
2. Rifilatura
3. Raschiatura
4. Nuovo tentativo
L'esecuzione dell'algoritmo ddrescue è mostrata nell'immagine seguente.

Conclusione
IL ddrescue è un potente strumento di recupero utilizzato per recuperare i dati da un'unità danneggiata o guasta su un'altra unità copiando i dati. Può essere installato facilmente su qualsiasi distribuzione Linux con l'aiuto del gestore pacchetti predefinito. Tieni presente l'importante considerazione prima di utilizzare questo strumento menzionato in questa guida. Il processo di copia dei dati è semplice, smonta l'unità e utilizza il comando ddrescue con il nome dell'unità di origine e il nome dell'unità di destinazione. Non dimenticare di utilizzare il file di registro, poiché diventa molto utile per riprendere il processo di ripristino.