Questo articolo discuterà su come utilizzare l'API multi-get di Elasticsearch per recuperare più documenti JSON in base ai loro ID. Inoltre, Elasticsearch consente di utilizzare una singola query get per recuperare i documenti dagli indici utilizzando solo gli ID documento.
Esploriamo.
Richiedi sintassi
Di seguito è riportata la sintassi per l'API multi-get di Elasticsearch:
OTTIENI /_mget
GET /
L'API multi-get supporta più indici che ti consente di recuperare i documenti anche se non si trovano nello stesso indice.
La richiesta supporta i seguenti parametri di percorso:
-
– Il nome dell'indice da cui recuperare i documenti come specificato dai relativi ID.
Puoi anche specificare gli altri parametri della query come mostrato:
- Preferenza – Definisce il nodo o lo shard preferito.
- Tempo reale – Se impostato su true, l'operazione viene eseguita in tempo reale.
- ricaricare – Forza l'operazione per aggiornare gli shard di destinazione prima di recuperare i documenti specificati.
- Instradamento – Un valore utilizzato per instradare le operazioni a uno shard specifico.
- Store_fields – Recupera i campi del documento archiviati in un indice anziché nel documento.
- _fonte – Un valore booleano che definisce se la richiesta deve restituire o meno il campo _source.
La query richiede il corpo, che include i seguenti valori:
- documenti – Specifica i documenti che desideri recuperare. Inoltre, questa sezione supporta i seguenti attributi:
- _id – ID univoco del documento di destinazione.
- _indice – L'indice che contiene il documento di destinazione.
- Instradamento – La chiave per lo shard principale del documento.
- _fonte – Se true, include tutti i campi di origine; in caso contrario, li esclude.
- _campi_memorizzati – I stored_fields che desideri includere.
- ID – Gli ID dei documenti che desideri recuperare.
Esempio 1: recuperare più documenti dallo stesso indice
L'esempio seguente mostra come utilizzare l'API multi-get di Elasticsearch per recuperare i documenti con ID specifici dall'indice Netflix:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: reporting' -H 'Tipo di contenuto: applicazione/json' -d'{
'documenti': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
La richiesta fornita dovrebbe recuperare i documenti con gli ID specificati dall'indice Netflix. L'output risultante è come mostrato:
{'documenti': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_versione': 1,
'_seq_no': 0,
'_termine_primario': 1,
'trovato': vero,
'_fonte': {
'durata': '90 min',
'listed_in': 'Documentari',
'paese': 'Stati Uniti',
'date_added': '25 settembre 2021',
'show_id': 's1',
'regista': 'Kirsten Johnson',
'anno_di_rilascio': 2020,
'valutazione': 'PG-13',
'description': 'Mentre suo padre si avvicina alla fine della sua vita, la regista Kirsten Johnson mette in scena la sua morte in modi fantasiosi e comici per aiutarli entrambi ad affrontare l'inevitabile.',
'tipo': 'Film',
'title': 'Dick Johnson è morto'
}
},
{
'_index': 'netflix',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_versione': 1,
'_seq_no': 12,
'_termine_primario': 1,
'trovato': vero,
'_fonte': {
'paese': 'Germania, Repubblica Ceca',
'show_id': 's13',
'direttore': 'Christian Schwochow',
'anno_di_rilascio': 2021,
'rating': 'TV-MA',
'description': 'Dopo che la maggior parte della sua famiglia è stata uccisa in un attentato terroristico, una giovane donna viene inconsapevolmente attirata a unirsi allo stesso gruppo che l'ha uccisa.',
'tipo': 'Film',
'titolo': 'Io sono Karl',
'durata': '127 min',
'listed_in': 'Drammi, film internazionali',
'cast': 'Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová',
'date_added': '23 settembre 2021'
}
}
]
}
Possiamo anche semplificare la richiesta inserendo gli ID documento in un semplice array come mostrato di seguito:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: reporting' -H 'Tipo di contenuto: applicazione/json' -d'{
'ids': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
La richiesta precedente dovrebbe eseguire un'azione simile.
Esempio 2: recuperare i documenti da più indici
Nell'esempio seguente, la richiesta recupera più documenti da indici diversi, come mostrato:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: reporting' -H 'Tipo di contenuto: applicazione/json' -d'{
'documenti': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': 'disney',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
L'output risultante è come mostrato:

Esempio 3: Escludi campi specifici
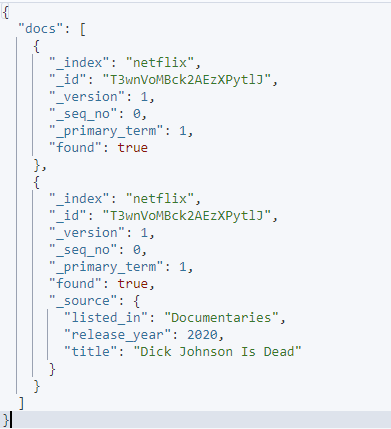
Possiamo escludere campi specifici da una determinata richiesta utilizzando i parametri source_include e source_exclude.
Un esempio è come mostrato:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: reporting' -H 'Tipo di contenuto: applicazione/json' -d'{
'documenti': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': falso
},
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_fonte': {
'include': [ 'listed_in', 'release_year', 'title' ],
'exclude': [ 'descrizione', 'tipo', 'data_aggiunta' ]
}
}
]
}'
La richiesta specificata utilizza l'inclusione e l'esclusione di origine per specificare i campi che desideri recuperare in un determinato documento.
L'output risultante è come mostrato:
Conclusione
In questo post, abbiamo discusso i fondamenti dell'utilizzo dell'API multi-get di Elasticsearch che consente di recuperare più documenti da varie fonti in base ai loro ID. Sentiti libero di esplorare gli altri documenti per ulteriori informazioni.
Buona codifica!