Panda Set_Opzione Metodo
Oggi vedremo come utilizzare la funzione 'pd.set_option()' per visualizzare tutte le colonne nel Dataframe Pandas quando lo si presenta nel tuo strumento Spyder. Per utilizzare 'pd.set_option()', seguiamo la sintassi indicata:

Iniziamo ad apprendere il concetto con l'assistenza dell'implementazione pratica del programma Python.
Esempio: utilizzo del metodo Set_Option di Pandas per visualizzare tutte le colonne
Questa dimostrazione è una guida per visualizzare tutte le colonne in un DataFrame utilizzando Panda 'set_option()'. Chiariremo i dettagli di ogni passaggio per l'implementazione di questo metodo Python.
Il primo requisito per l'implementazione pratica dello script Python è trovare lo strumento migliore per eseguire il programma. Lo strumento che abbiamo utilizzato per la nostra illustrazione è lo strumento 'Spyder'. Abbiamo lanciato lo strumento e abbiamo iniziato a lavorare sullo script Python.
A partire dal codice, inizialmente dobbiamo importare le librerie dei prerequisiti di cui abbiamo bisogno in questo programma. La prima libreria che abbiamo caricato nel nostro file Python è la libreria Pandas poiché le funzioni che utilizziamo qui sono fornite da Pandas. Abbiamo alias questa libreria come 'pd'. La seconda libreria che abbiamo caricato è la libreria NumPy. NumPy (Numerical Python) è un pacchetto di calcolo numerico sviluppato sulla programmazione Python. La sezione Import NumPy del codice indica a Python di integrare il modulo NumPy nel file Python corrente. La parte 'as np' dello script indica quindi a Python di assegnare a NumPy l'abbreviazione 'np'. Ti consente di utilizzare i metodi NumPy inserendo 'np.function_name' invece di NumPy.
Ora iniziamo con il codice principale. L'esigenza principale e fondamentale per il nostro programma è Pandas DataFrame. Quindi, mostriamo tutte le colonne che contiene. Ora sta a te decidere se vuoi creare un DataFrame con valori specificati o se devi importare un file CSV. Quello che abbiamo scelto per questa istanza è la creazione di un DataFrame con valori NaN. Abbiamo invocato il metodo 'pd.DataFrame()' per costruire un DataFrame. Qui, abbiamo fornito due parametri: 'indice' e 'colonne'. L'argomento 'indice' si riferisce alle righe, il che significa che impostiamo le righe per DataFrame.
Abbiamo assegnato il parametro 'index' e la funzione NumPy 'np.arange() con un conteggio del valore di '6'. Genera sei righe per DataFrame. Riempie tutte le voci con valori NaN poiché non gli abbiamo fornito alcun valore. L'argomento 'colonne', come specifica il nome, viene utilizzato per impostare le colonne per il DataFrame. Viene inoltre assegnata la funzione 'np.arange()' con il conteggio del valore '25' per le colonne. Pertanto, costruisce 25 colonne per DataFrame.
Di conseguenza, quando chiamiamo la funzione 'pd.DataFrame()', abbiamo un DataFrame con 25 colonne e 6 righe riempite con valori nulli. Per la necessità di preservare questo DataFrame, ci viene richiesto di costruire un oggetto DataFrame che memorizzi il suo contenuto. Pertanto, abbiamo creato un oggetto DataFrame 'random' e gli abbiamo assegnato il risultato che otteniamo dal metodo 'pd.DataFrame()'. Ora, sicuramente vorrai vedere il DataFrame generato. Python ci fornisce un metodo per visualizzare l'output sullo schermo che è la funzione 'print()'. Abbiamo invocato questo metodo passando l'oggetto DataFrame 'random' come parametro.
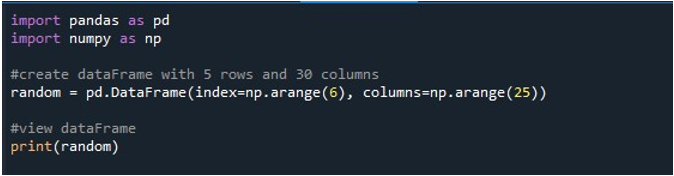
Quando eseguiamo questo frammento di codice, otteniamo il nostro DataFrame con i valori NaN visualizzati sul terminale. Qui possiamo osservare che sono visibili alcune delle prime colonne e solo alcune dalla fine. Tutte le colonne intermedie vengono troncate. Per impostazione predefinita, nasconde alcune righe e colonne per evitare di creare frustrazione per l'utente visualizzando enormi set di dati.
Puoi anche controllare il numero di colonne totali in un DataFrame usando la funzione 'len()' di Pandas. Scrivi la funzione 'len()' sulla console del tuo strumento 'Spyder'. Scrivi il nome di DataFrame tra parentesi con la proprietà '.columns'. Ci restituisce la lunghezza totale delle colonne nel tuo DataFrame.

Restituisce la lunghezza del nostro DataFrame che è 25.
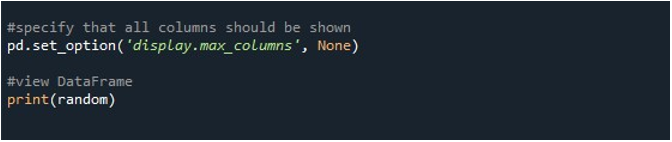
Ora, l'attività successiva e principale è modificare l'opzione predefinita per visualizzare l'output. Potrebbero esserci circostanze in cui si desidera visualizzare l'intero DataFrame sul terminale. A causa dei valori predefiniti, molte voci vengono troncate, causando delusione per l'utente. Imparerai qui come superare questo problema. Pandas ci fornisce una funzione 'pd.set_option()' per modificare le impostazioni di visualizzazione predefinite. Subito dopo aver visualizzato il DataFrame sulla console, invochiamo il metodo 'pd.set_option()'. Specifichiamo il parametro tra parentesi di questa funzione che dobbiamo utilizzare per visualizzare tutte le colonne del DataFrame.
Qui, abbiamo utilizzato 'display.max_columns' per visualizzare il numero massimo di colonne nel nostro DataFrame. Possiamo anche definire il valore per questo parametro, ovvero le colonne massime che si vogliono visualizzare. Noi, d'altra parte, impostiamo 'display.max_columns' su 'None' che mostra tutte le colonne del DataFrame con lunghezza massima. Infine, abbiamo utilizzato la funzione 'print()' per visualizzare il DataFrame risultante con tutte le colonne visibili sul terminale.
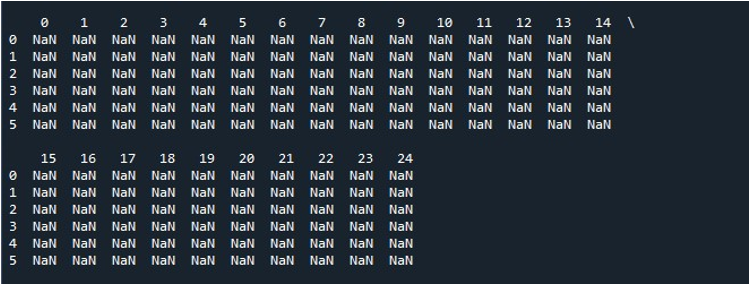
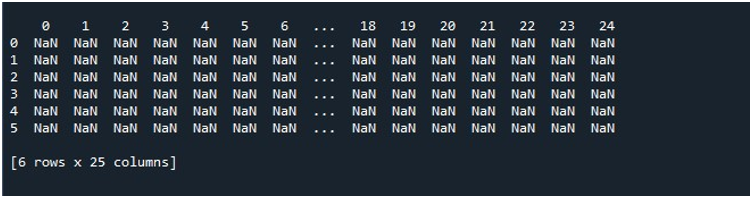
Quando premiamo l'opzione 'Esegui file' sullo strumento 'Spyder', possiamo visualizzare un DataFrame esposto. Questo DataFrame ha sei righe e il numero di colonne che contiene è 25. Non ci sono colonne troncate poiché la funzione 'pd.set_option()' con la lunghezza massima della colonna è ora abilitata.
Possiamo anche ripristinare l'opzione di visualizzazione perché una volta impostata la lunghezza di visualizzazione al massimo, continua a visualizzare i DataFrames con tutte le colonne all'interno di quel particolare file Python. Per questo, utilizziamo i Panda 'pd.reset_option()'. Invochiamo questa funzione e forniamo 'display.max_columns' come parametro di questa funzione.

Questo ci fornisce le impostazioni di visualizzazione iniziali per il DataFrame fornito.
Conclusione
Visualizzare l'output completo sul terminale con un enorme set di dati a volte ci mette nei guai quando le impostazioni predefinite dello strumento sono in contrasto con le esigenze dell'utente. Per risolvere questa battuta d'arresto, Pandas ci fornisce il metodo 'pd.set_option()'. In questa guida all'apprendimento, ti abbiamo presentato questo metodo e la necessità di utilizzarlo. Abbiamo dimostrato l'argomento con i codici di esempio Python praticamente compilati ed eseguiti. Abbiamo reso i risultati dell'illustrazione realizzata su “Spyder”. Abbiamo spiegato come visualizzare tutte le colonne del DataFrame sulla console modificando le impostazioni predefinite e ripristinando tutte le impostazioni iniziali. Prestare un'attenzione completamente focalizzata all'implementazione pratica del modulo ti consente di utilizzarlo ogni volta che incontri tali problemi.