Questo post ti farà conoscere il modo giusto per decodificare le stringhe con entità HTML speciali.
Qual è il modo giusto per decodificare una stringa che contiene entità HTML speciali?
Per decodificare una stringa che contiene speciali entità HTML, utilizzare i seguenti metodi:
Metodo 1: decodificare una stringa che contiene entità HTML speciali utilizzando l'elemento 'textarea'.
Usa l'HTML ' ” per decodificare una stringa che contiene entità HTML speciali. Prende una stringa con speciali entità HTML usando il ' innerHTML ' proprietà. Il browser decodifica automaticamente le entità nella textarea e fornisce il semplice testo in chiaro. Per recuperare la stringa decodificata, utilizzare il ' valore ' proprietà.
Esempio
Crea una variabile ' codificatoStringa ” che memorizza una stringa contenente entità HTML speciali al suo interno:
cost codificatoStringa = '<div>Benvenuto in Linuxhint!</div>' ;
Stampa la stringa codificata sulla console:
consolare. tronco d'albero ( 'Stringa codificata: ' + codificatoStringa ) ;Crea un elemento HTML ' area di testo ' usando il ' creaElemento() ' metodo:
cost area di testo = documento. createElement ( 'area di testo' ) ;
Passa la stringa codificata alla textarea usando il ' innerHTML ' proprietà:
area di testo. innerHTML = codificatoStringa ;Ora, ottieni la stringa decodificata usando ' valore ” attributo della textarea e memorizzarlo in una variabile “ decodedString ”:
cost decodedString = area di testo. valore ;Infine, visualizza la stringa decodificata sulla console utilizzando il ' console.log() ' metodo:
consolare. tronco d'albero ( 'Stringa decodificata: ' + decodedString ) ;L'output indica che la stringa contenente entità HTML speciali è stata decodificata correttamente:
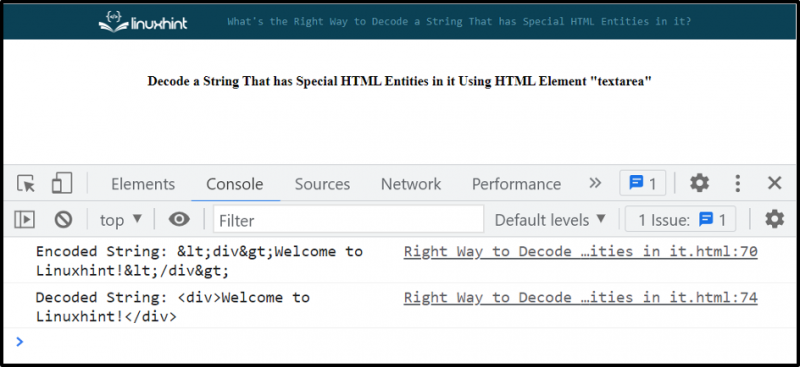
L'approccio di cui sopra è semplice e chiaro ed è adatto a scenari semplici. Se provi a gestire strutture HTML complesse, fallirà. Quindi, per questo, usa il metodo 'parseFromString ()'.
Metodo 2: decodificare una stringa che contiene entità HTML speciali utilizzando il metodo 'parseFromString ()'.
Un altro modo per decodificare una stringa con entità HTML speciali è il ' parseFromString() ' metodo. È un metodo pre-costruito del “ DOMParser oggetto. Aiuta ad analizzare una stringa XML o HTML e quindi creare un nuovo oggetto documento DOM da esso.
Esempio
Innanzitutto, crea un nuovo oggetto di ' DOMParser ' usando il ' nuovo ' parola chiave:
cost analizzatore = nuovo DOMParser ( ) ;Chiama il ' parseFromString() ” metodo e passa i parametri “ stringa codificata ” come struttura HTML complessa, e il “ testo/html ”. Dice al metodo di trattare la stringa codificata come HTML. Usa il ' textContent ” proprietà dell'elemento body per ottenere la stringa decodificata:
cost decodedString = analizzatore. parseFromString ( ` tipo di documento html >< corpo > $ { codificatoStringa } ` , 'testo/html' ) . corpo . textContent ;Stampa la stringa decodificata sulla console:
consolare. tronco d'albero ( 'Stringa decodificata: ' + decodedString ) ;Produzione
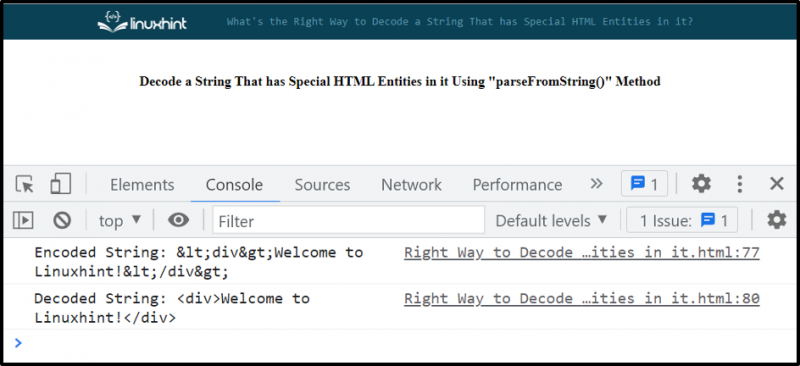
Abbiamo fornito tutte le istruzioni essenziali relative alla decodifica di una stringa con entità HTML speciali.
Conclusione
Per decodificare una stringa che contiene speciali entità HTML, utilizzare l'elemento HTML ' area di testo ' o il
“ parseFromString() ” metodo del “ DOMParser oggetto. L'approccio