I dati vengono raccolti in grandi quantità ogni giorno e la gestione dei big data è il caso d'uso più importante del motore Elasticsearch. I dati vengono archiviati nel database di analisi in tempo reale e l'utente può estrarre i dati per trovare informazioni utili da esso utilizzando query. L'utente può applicare query per trovare dati da più indici e visualizzarli in un singolo bucket dal database relazionale.
Questa guida spiegherà le aggregazioni Elasticsearch con esempi che utilizzano diverse aggregazioni.
Cos'è l'aggregazione Elasticsearch?
In Elasticsearch, l'aggregazione è il processo di combinazione o raggruppamento dei campi per estrarre informazioni dal database relazionale. L'aggregazione in Elasticsearch può essere considerata come il GRUPPO PER CLAUSOLA O AGGREGATO() funzione nel linguaggio SQL.
Come utilizzare l'aggregazione Elasticsearch?
Per utilizzare l'aggregazione in Elasticsearch, l'utente deve avere una conoscenza di base del proprio database. Esploriamo la sintassi e la sua implementazione pratica:
Sintassi
Per trovare i dati dal database, la sintassi dell'aggregazione nel motore Elasticsearch come di seguito:
'aggiungi' : {'nome_dell'aggregazione' : {
'tipo_di_aggregazione' : {
'campo' : 'nome_campo_documento'
}
I frammenti di cui sopra:
-
- Usa il “ agg ” parola chiave che spiega l'utilizzo dell'aggregazione nella query.
- IL nome_di_aggregazione viene impostato dall'utente in base alle informazioni richieste.
- Dopodiché, il tipo_di_aggregazione viene utilizzato per ottenere dati.
- L'ultima riga utilizza il campo parola chiave seguita dal nome dell'attributo del documento.
Esempio 1: aggregazione nei dati campione di Kibana
Questa sezione spiega l'aggregazione con l'aiuto di un esempio utilizzando i dati di esempio di Kibana collegandosi prima ad esso. Dopodiché, vai semplicemente all'interno del ' Strumenti di sviluppo ” cercandolo dalla barra di ricerca e facendo clic su di esso:
Recupera i dati dai dati di esempio
Usa semplicemente il seguente comando per recuperare i dati dal ' kibana_sample_data_logs ” indice sulla console Dev Tools:
OTTENERE / kibana_sample_data_logs / _ricerca
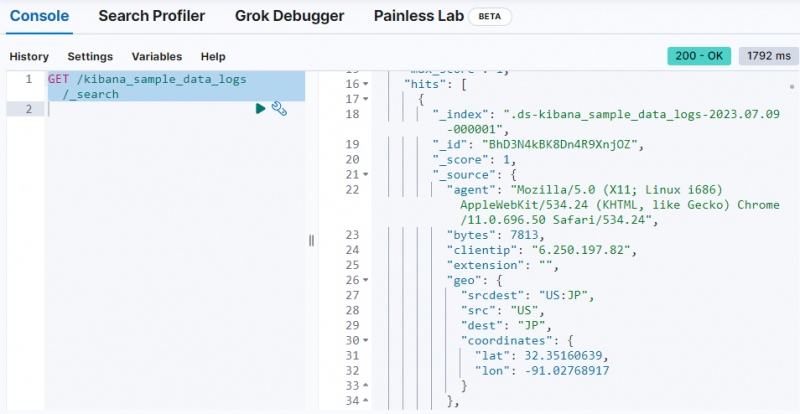
L'output mostra che i dati sono stati recuperati dal ' kibana_sample_data_logs indice.
Il codice seguente usa a OTTENERE richiesta sul “ kibana_sample_data_log ” per cercarlo utilizzando l'aggregazione value_count sul “ clientip ' campo:
OTTENERE / kibana_sample_data_logs / _ricerca{ 'misurare' : 0 ,
'aggiungi' : {
'ip_count' : {
'value_count' : {
'campo' : 'suggerimento cliente'
}
}
}
}
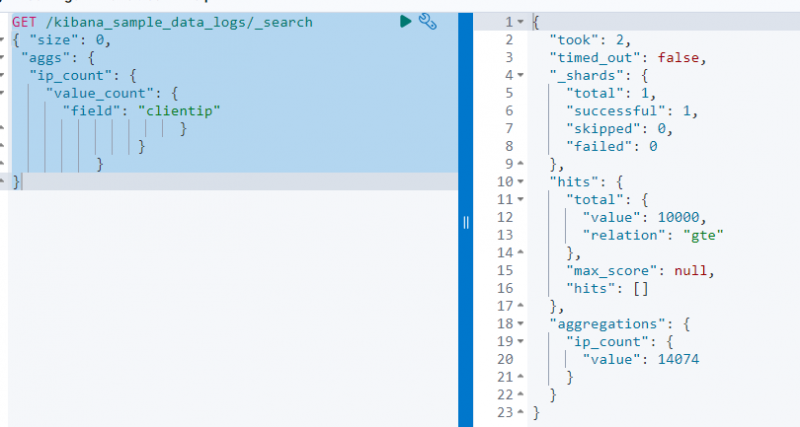
Lo screenshot sopra mostra l'aggregazione sul file clientip campo con il valore 14074 .
Aggregazioni importanti
Alcune delle aggregazioni importanti che vengono utilizzate per trovare i dati in modo efficiente dal database sono menzionate di seguito:
Gli esempi seguenti spiegano le aggregazioni sopra menzionate utilizzando l' OTTENERE richiesta del “ kibana_sample_data_ecommerce indice:
Aggregazione di cardinalità
Il codice seguente utilizza il ' cardinalità ” aggregazione sul “ sku ” dai dati dell'e-commerce. L'esecuzione di questo codice otterrà l'aggregazione a valore singolo per ottenere gli SKU univoci dal database Elasticsearch:
OTTENERE / kibana_sample_data_ecommerce / _ricerca{
'misurare' : 0 ,
'aggiungi' : {
'unique_skus' : {
'cardinalità' : {
'campo' : 'codice'
}
}
}
}
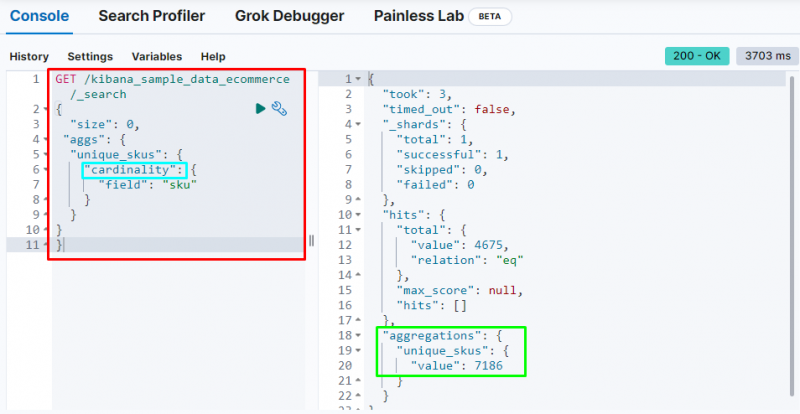
Visualizza il cardinalità aggregazione trovando il 7186 valori dall'indice.
Aggregazione statistiche
Altra importante aggregazione è la “ statistiche ” aggregazione che viene utilizzata per ottenere il “ contare ”, “ min ”, “ max ”, “ media ', E ' somma ' statistiche dal ' quantità totale ' campo:
OTTENERE / kibana_sample_data_ecommerce / _ricerca{
'misurare' : 0 ,
'aggiungi' : {
'quantità_statistiche' : {
'statistiche' : {
'campo' : 'quantità totale'
}
}
}
}
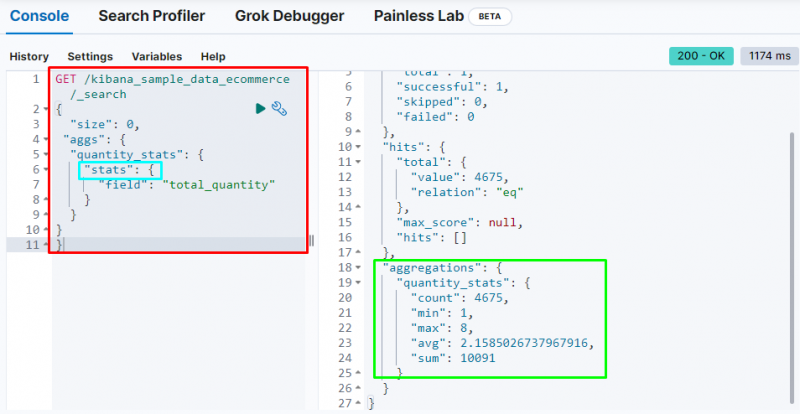
Lo screenshot sopra mostra le statistiche nell'output del ' quantità totale ' campo.
Filtra l'aggregazione
L'aggregazione dei filtri viene utilizzata per filtrare i dati in base a un termine o una frase dal database come li contiene il codice seguente:
OTTENERE / kibana_sample_data_ecommerce / _ricerca{ 'misurare' : 0 ,
'aggiungi' : {
'filtro_aggregazione' : {
'filtro' : {
'termine' : {
'utente' : 'eddie' } } ,
'aggiungi' : {
'prezzo_medio' : {
'medio' : {
'campo' : 'prodotti.prezzo' } }
} } } }
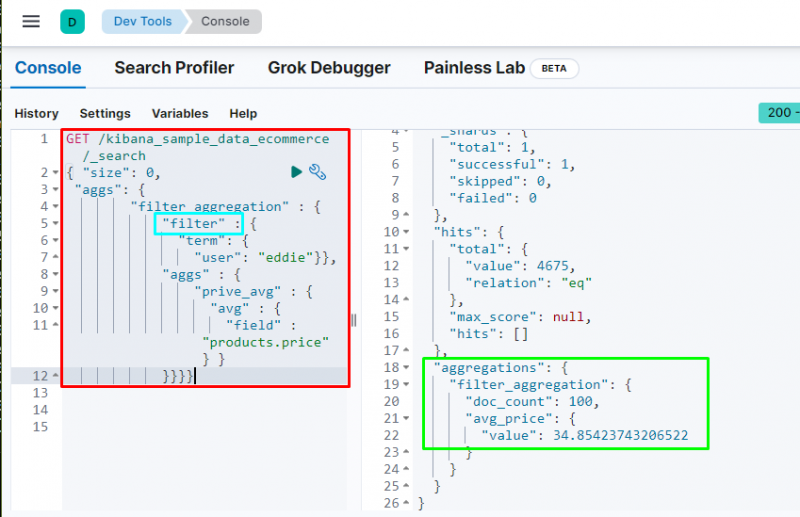
L'esecuzione del codice filtrerà i dati in base al ' eddy ” dell'utente e visualizza il prezzo medio degli articoli acquistati. Lo screenshot sopra mostra che il file utente ha trovato 100 volte dai dati e dal valore del media _ prezzo aggregazione.
Aggregazione dei termini
Il termine aggregazione crea un bucket e archivia i dati dal campo nel bucket e il codice seguente utilizza il ' utente ' campo per memorizzare i suoi dati nel secchio:
OTTENERE / kibana_sample_data_ecommerce / _ricerca{
'misurare' : 0 ,
'aggiungi' : {
'Termine_aggregazione' : {
'termini' : {
'campo' : 'utente'
}
}
}
}
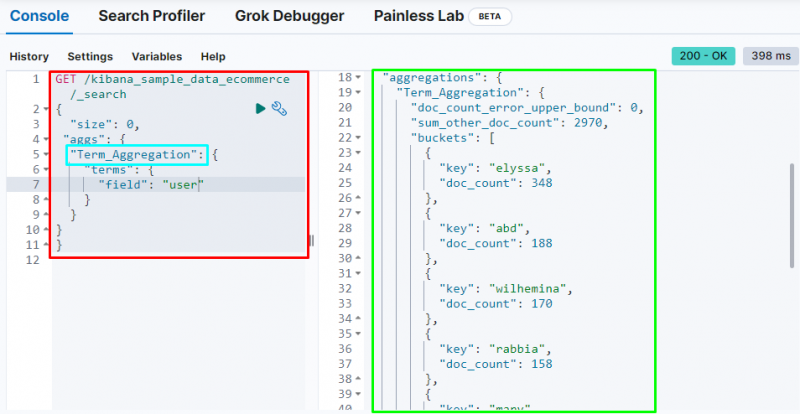
Lo screenshot seguente mostra che il termine aggregazione ha creato bucket per ogni utente e il relativo conteggio dei documenti.
Questo è tutto sull'aggregazione Elasticsearch e su diverse importanti aggregazioni.
Conclusione
In Elasticsearch, l'aggregazione viene utilizzata per ottenere dati dai documenti aggregati e questi documenti vengono estratti da un campo specifico. Ci sono alcune aggregazioni importanti che vengono utilizzate per ottenere informazioni utili dagli indici spiegati. Questa guida ha spiegato l'aggregazione Elasticsearch e dimostrato il processo di utilizzo dell'aggregazione Elasticsearch.