Elasticsearch è una soluzione robusta e apprezzata per archiviare dati ingombranti, non strutturati e semi-strutturali. È puramente un database NoSQL e utilizza un approccio completamente diverso per archiviare, gestire e recuperare i dati. Memorizza i dati in un documento in formato JSON e utilizza le API di riposo per eseguire diverse operazioni sui dati archiviati.
In questo blog dimostreremo:
- Come funziona Elasticsearch per archiviare e cercare dati?
- Cosa sono i documenti Elasticsearch?
- Come archiviare i dati in un documento Elasticsearch?
Come funziona Elasticsearch per archiviare e cercare dati?
Di seguito sono elencati i principali componenti o la gerarchia di Elasticsearch utilizzati per archiviare i dati:
- Documento: Il documento è la parte principale di Elasticsearch che memorizza i dati in formato JSON. Come
- Indici: Gli indici sono indicati come indici. È una raccolta di documenti. Come in SQL, viene definito Database.
- Indici invertiti: Supporta una ricerca full-text molto veloce. Memorizza la parola come indice e il nome del documento come riferimento.
Cosa sono i documenti Elasticsearch?
Il documento Elasticsearch è un'unità di archiviazione di dati in formato JSON. Come nei database relazionali, il documento può essere indicato come una tabella o una riga di un database archiviato in un indice. L'indice può avere più documenti ed è indicato come un database che ha più tabelle. Di solito memorizza una struttura dati complessa e sterilizza i dati in formato JSON.
Inoltre, ogni documento può contenere più campi che sono ' chiave: valore ” coppie per archiviare i dati proprio come una tabella ha più colonne o campi in un database relazionale. Quindi, queste coppie chiave-valore dovrebbero essere indicizzate in modo da determinare la mappatura del documento. La mappatura definisce quindi il tipo di dati del documento in base ai dati del campo come testo, float, punto geografico, ora e molti altri.
Elasticsearch non ci ha mai obbligato a predefinire la struttura del campo dell'indice e i documenti possono avere una struttura del campo diversa in un indice. Tuttavia, se la mappatura del campo è definita per un tipo di dati specifico, tutti i documenti Elasticsearch in un indice devono seguire lo stesso tipo di mappatura. Per verificare il funzionamento del documento per archiviare i dati in Elasticsearch, passare alla sezione successiva.
Come archiviare i dati in un documento Elasticsearch?
Per archiviare i dati in Elasticsearch, l'utente deve prima creare un indice. Quindi, specifica i campi per archiviare i dati nel documento Elasticsearch. Per la dimostrazione, eseguire i passaggi elencati.
Passaggio 1: avviare Elasticsearch
Per eseguire il database o il motore Elasticsearch sul sistema, avviare il terminale di sistema come il prompt dei comandi. Successivamente, visita il ' bidone ” cartella di Elasticsearch attraverso il “ CD comando:
CD C:\Users\Dell\Documents\Elk stack\elasticsearch-8.7.0\bin
Successivamente, esegui il file batch di Elasticsearch per eseguire il database sul sistema:
elasticsearch.bat
Passaggio 2: avviare Kibana
Quindi, esegui Kibana sul sistema. Per farlo, visita il suo “ bidone ” cartella dal prompt dei comandi:
CD C:\Users\Dell\Documents\Elk stack\kibana-8.7.0\bin
Successivamente, esegui il comando seguente per avviare l'esecuzione di Kibana:
kibana.bat
Nota: Se non hai installato e configurato Elasticsearch e Kibana sul sistema, vai ai nostri post e controlla la procedura dettagliata per installarli sul sistema.
Per Elasticsearch, visita il nostro ' Installa e configura Elasticsearch con .zip su Windows ” articolo. Per configurare Kibana su Windows, segui il ' Configura Kibana per Elasticsearch ” articolo.
Passaggio 3: accedi a Kibana
Dopo aver avviato Kibana sul sistema, vai all'indirizzo predefinito di Kibana ' host locale:5601 ' nel browser e fornire le credenziali di accesso di Elasticsearch come ' elastico ” utente e password. Successivamente, premi il ' Login pulsante ':
Passaggio 4: apri lo 'strumento di sviluppo' di Kibana
Successivamente, fai clic su ' Tre barre orizzontali ” icona e apri il Kibana “ Strumento di sviluppo ” per utilizzare le API per archiviare, recuperare e aggiornare i dati:
Passaggio 5: creare l'indice
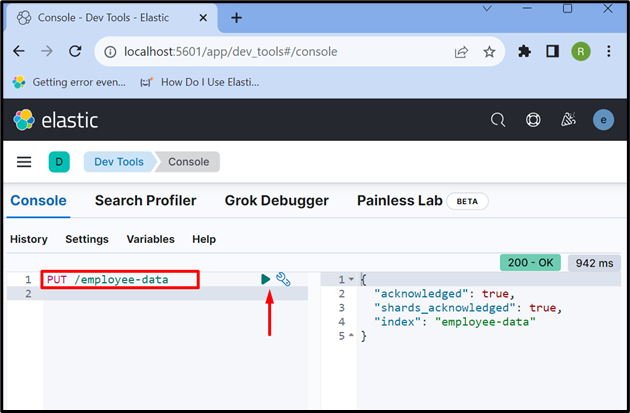
Ora, crea un nuovo indice usando ' PUT /
L'output mostra che ' dati-dipendenti 'l'indice è stato creato con successo:
Passaggio 6: inserire i dati nel documento
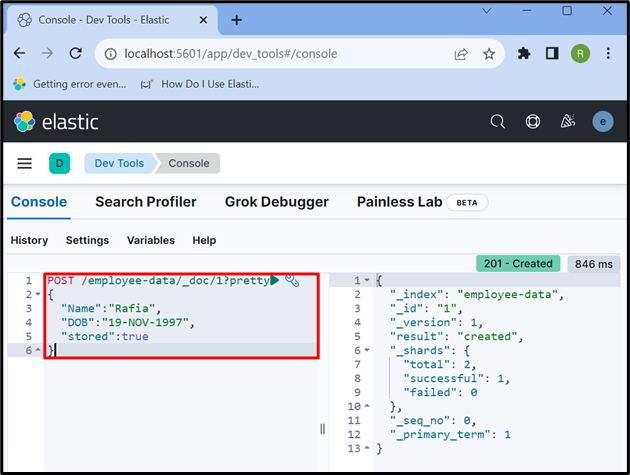
Ora usa il ' INVIARE ” API per archiviare i dati nell'indice. Nella richiesta sottostante, “ dati-dipendenti ” è un indice di Elasticsearch, “ _doc ' viene utilizzato per archiviare i dati nel documento Elasticsearch e ' 1 ” è l'id:
INVIARE / dati-dipendenti / _doc / 1 ?bello{
'Nome' : 'Rafia' ,
'DOB' : '19-NOV-1997' ,
'immagazzinato' :VERO
}
Passaggio 7: recupero dei dati dal documento Elasticsearch
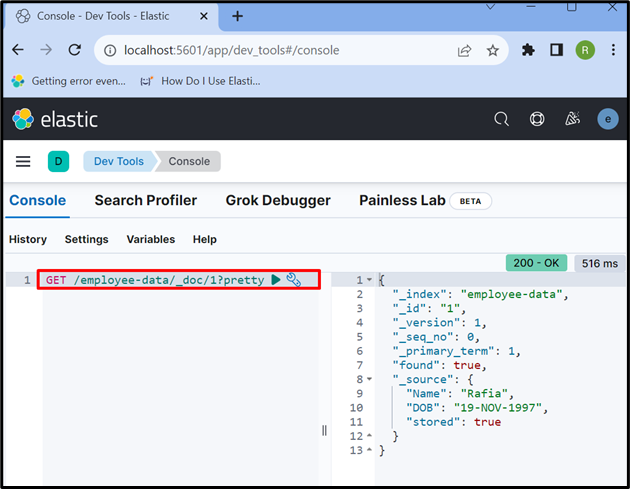
Per accedere ai dati dall'indice o dal documento Elasticsearch, utilizzare il ' OTTENERE ” API come utilizzato di seguito:
OTTENERE / dati-dipendenti / _doc / 1 ?bello
L'output mostra che abbiamo estratto con successo i dati dal documento Elasticsearch con id ' 1 ”:
Questo è tutto sul documento Elasticsearch.
Conclusione
Il documento Elasticsearch viene solitamente utilizzato per archiviare i dati in formato JSON. Come nei database relazionali, il documento può essere definito come una riga memorizzata in un indice. Questi indici possono avere più documenti proprio come i database hanno tabelle diverse. Questi documenti contengono più campi che sono ' chiave: valore ” coppie per memorizzare i dati. Questo articolo ha dimostrato cosa sono i documenti Elasticsearch e come funzionano in Elasticsearch.