Chiglia (Knowledge Extraction based on Evolutionary Learning) è uno strumento software basato su Java specializzato nell'implementazione di algoritmi evolutivi. Poiché è un open source, fornisce un'ampia varietà di algoritmi di scoperta della conoscenza che possono essere utilizzati in esperimenti che alimentano la comunità di data mining e analisi. Fornisce un'interfaccia utente grafica semplice e facile da usare che riduce significativamente la complessità complessiva di questo strumento. La maggior parte degli strumenti simili sul mercato richiede agli utenti di interagire con essi scrivendo il codice mentre Keel rimuove questo requisito fornendo una GUI intuitiva che può essere utilizzata sia dai principianti che dagli esperti.
Keel fornisce un'ampia varietà di diversi algoritmi basati sull'intelligenza computazionale, tra cui classificazione, regressione, estrazione di caratteristiche, analisi dei modelli, clustering e altro ancora. Con i modelli mainstream inseriti direttamente nell'applicazione stessa, Keel è uno strumento molto utile quando si tratta di eseguire analisi esplorative dei dati su set di dati grezzi. La sua semplice interfaccia drag and drop unita alla facilità di utilizzo delle funzionalità consente una sperimentazione di data mining rapida ed efficiente sia per scopi didattici che di ricerca. Strumenti come Keel stanno diventando sempre più popolari a causa del loro approccio semplicistico a pratiche algoritmiche altrimenti complesse.
Installazione
Ci sono due modi principali in cui possiamo installare Chiglia su qualsiasi macchina Linux. Il primo consiste nell'andare al Pagina web della chiglia e scaricando il software da lì. Il secondo, che seguiremo in questa guida all'installazione, richiede di scaricare Keel utilizzando il wget strumento di download disponibile per gli utenti Linux.
1. Iniziamo ottenendo wget sulla nostra macchina Linux.
Eseguire il seguente comando per scaricare il wget utilizzando il file adatto gestore di pacchetti:
$ sudo apt-get install wget
Vedrai un output di terminale simile:
2. Ora che abbiamo il wget tool installato sulla nostra macchina Linux, lo usiamo per scaricare il file Chiglia attrezzo.
Questo è il collegamento che passiamo a wget.
Esegui il seguente comando nel tuo terminale:
$ wget http: // sci2s.ugr.es / chiglia / Software / prototipi / openVersion / Software- 2018 -04-09.zip
Dovresti vedere un output simile sul tuo terminale:
Una volta terminato il download di Keel, possiamo continuare con il resto dell'installazione.
3. Ora estraiamo il file compresso che abbiamo scaricato nel passaggio precedente utilizzando lo strumento Linux Unzip.
Esegui il seguente comando:
$ decomprimere Software- 2018 -04-09.zip
Dovresti vedere un output simile nel terminale:
4. Passare alla cartella Keel eseguendo il seguente comando:
$ CD Software- 2018 -04-09 / documenti / esperimenti / CHIGLIA / dist /
5. Eseguire il seguente comando per avviare l'installazione:
$ Giava -barattolo . / GraphInterKeel.jar
Con questo, Keel dovrebbe essere disponibile per l'uso sulla tua macchina Linux.
Guida utente
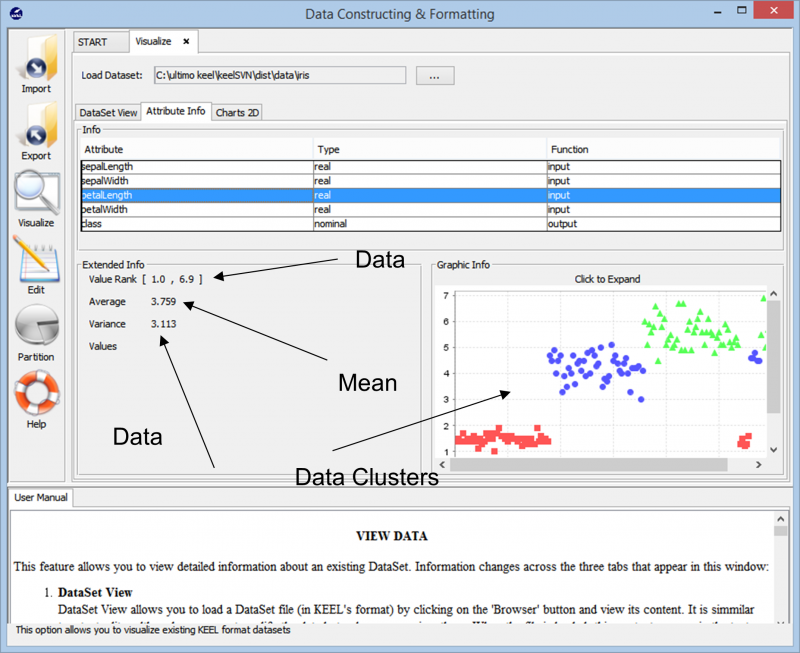
Interagire con il Chiglia l'applicazione è davvero facile e semplice. Iniziamo importando il file Insieme di dati dell'iride nel nostro spazio di lavoro.
Mentre importiamo i dati, lo strumento ci mostra il raggruppamento complessivo del punto dati nel set di dati. Ci mostra anche le diverse classi presenti nel set di dati insieme alle informazioni di base come gli intervalli numerici che coprono questi punti dati e la varianza complessiva e i valori medi che presenta. Queste informazioni consentono agli utenti di comprendere meglio come procedere con la preparazione dei dati per qualsiasi tipo di attività di analisi dei dati.
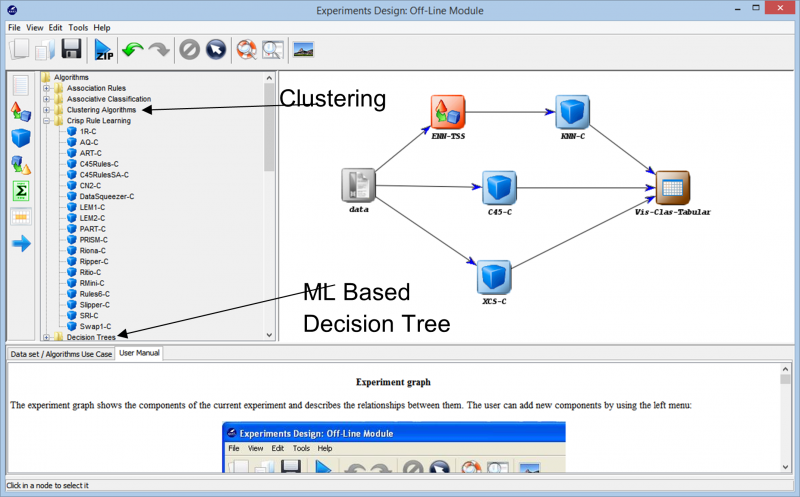
Procedendo ulteriormente nella sperimentazione, ci imbattiamo nelle diverse tecniche che possono essere utilizzate per creare il nostro esperimento su qualsiasi set di dati. I diversi algoritmi di apprendimento che possono essere utilizzati sui nostri dati possono essere visti nell'immagine seguente. A seconda della natura del set di dati e dei requisiti dell'esperimento, è possibile sperimentare diversi algoritmi.
Ad esempio, se stai lavorando con dati senza etichetta e devi trovare somiglianze tra i diversi punti dati nel tuo set di dati, l'utilizzo di un algoritmo di clustering dalle varie opzioni disponibili può aiutarti a comprendere meglio i punti dati. Questo alla fine ti aiuta a etichettare e classificare i punti dati in modo che l'esperimento possa essere costruito utilizzando algoritmi di apprendimento supervisionato più completi.
Conclusione
Il Chiglia piattaforma per l'analisi dei dati è una buona risorsa sia per scopi di ricerca che didattici. La sua interfaccia utente grafica di facile utilizzo aiuta gli utenti a comprendere meglio i requisiti dei dati oltre a fornire riferimenti logici a tecniche e algoritmi utili che aiutano ulteriormente gli utenti nei loro flussi di lavoro. Avere una vasta gamma di algoritmi diversi che rientrano nelle diverse categorie e tecniche algoritmiche consente agli utenti di sperimentare numerose direzioni logiche e confrontare questi risultati in modo da raggiungere la soluzione più ottimale a qualsiasi problema.
L'approccio drag and drop senza codice di Keel al data mining aiuta anche i principianti a lavorare senza sforzo con modelli di intelligenza computazionale completi. Ciò fornisce approfondimenti su set di dati complessi e, di conseguenza, deriva utili inferenze che aiutano a risolvere i problemi del mondo reale.