Questo articolo fornisce agli utenti una comprensione più approfondita per l'implementazione del data warehouse con AWS Redshift.
Cos'è AWS Redshift?
AWS Redshift consente ai suoi utenti di recuperare e manipolare i dati senza tutte le configurazioni di un database tradizionale. Ridimensiona in modo intelligente la capacità in base ai requisiti dell'applicazione, fornisce risposte rapide e precise ed è completamente gestito da AWS. AWS Redshift è ampiamente utilizzato per le sue vaste applicazioni di analisi dei Big Data. Inoltre, segue il modello pay-as-you-use e non comporta costi aggiuntivi quando il magazzino è inattivo:
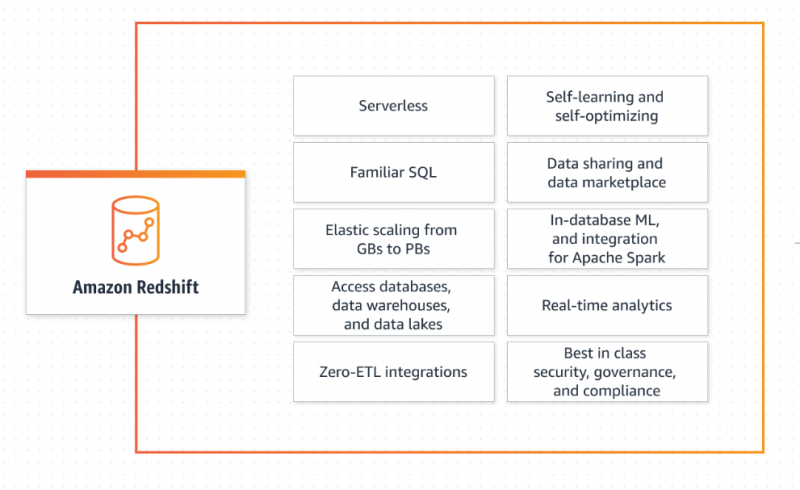
Scopri di più su Redshift facendo riferimento a questo articolo: 'Quali sono i tipi di dati di Amazon Redshift' :
Come implementare il data warehousing con Amazon Redshift?
Amazon Redshift utilizza Standard Query Language (SQL) in diversi magazzini per l'esecuzione delle query. Estrarre i valori massimi monitorando il costo della configurazione manuale di un Data Warehouse è noioso. Pertanto, AWS Redshift accelera in modo accurato e intelligente le tue attività aziendali relative ai dati e ti aiuta ad accelerare i tempi per ottenere informazioni dettagliate sui dati in modo rapido, semplice, affidabile e sicuro. I vantaggi derivanti dall'implementazione del data warehousing con Amazon Redshift sono numerosi:
- Crittografia dei dati
- Ottimizzazione intelligente
- Costo ottimale
- Automatizza le attività ripetitive
- Capacità di scalabilità automatica
- Supporto per varie risorse AWS
Di seguito sono riportati alcuni passaggi in cui possiamo implementare il Data Warehousing con Amazon Redshift:
Passaggio 1: crea un ruolo IAM
Il primo passo per implementare un Data Warehouse su AWS Redshift inizia con la creazione di un ruolo IAM. A questo scopo, cerca e seleziona il ruolo IAM sul file Console di gestione AWS :
Clicca sul “Ruoli” opzione dalla barra laterale del ruolo IAM:
Clicca sul “Crea ruolo” pulsante successivo:
Nel Tipo di entità attendibile sezione, fare clic su “Servizio AWS” mentre stiamo creando questo ruolo IAM per Redshift:
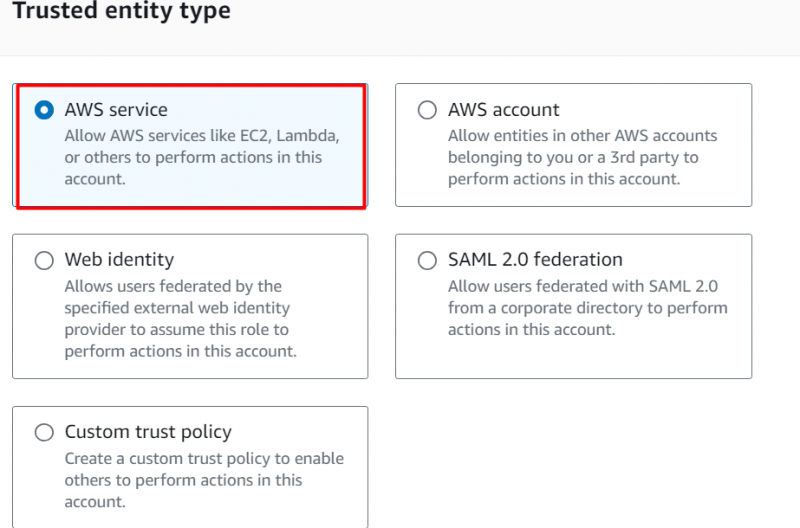
Nel Caso d'uso sezione , Selezionare “Spostamento rosso” nel campo evidenziato e procedere alla selezione della successiva opzione evidenziata. Clicca sul 'Prossimo' pulsante successivamente:
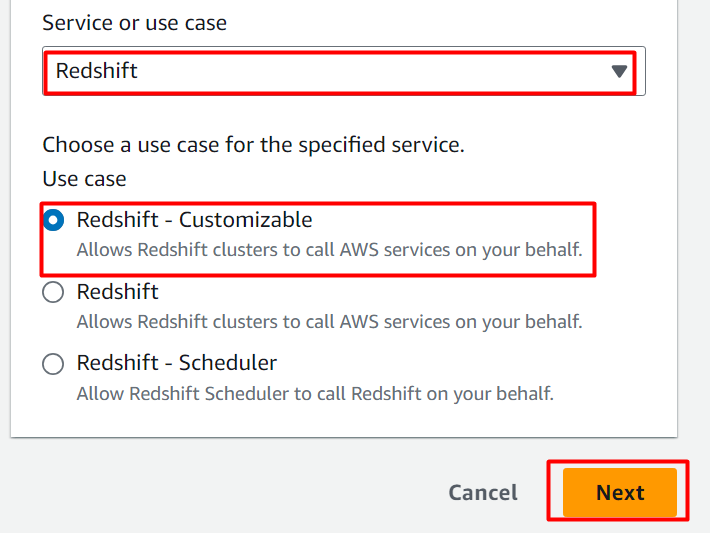
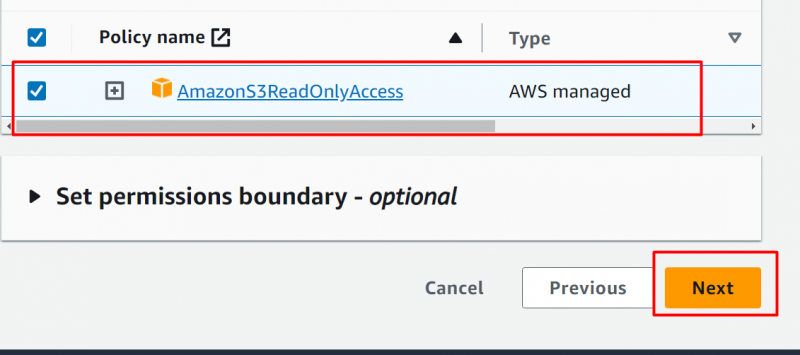
Nel Politica di autorizzazione sezione , cerca e seleziona il “AmazonS3ReadOnlyAccess” opzione. E poi fare clic su 'Prossimo' pulsante successivamente:
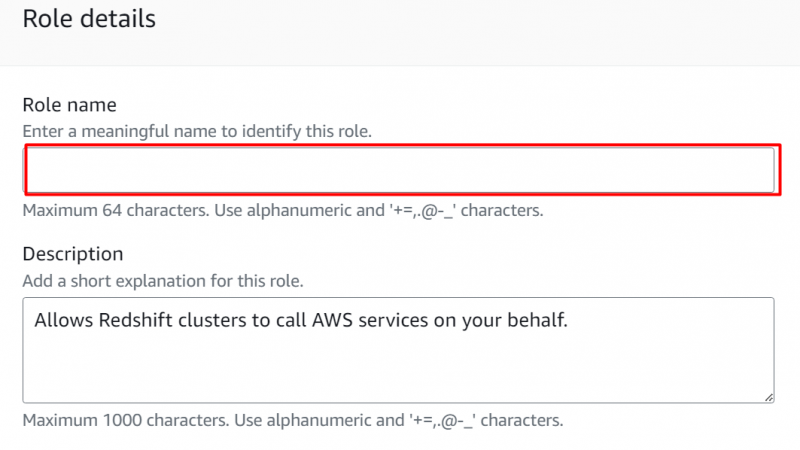
Nel Dettagli del ruolo sezione , fornire il nome per il ruolo:
Tenendo il resto del impostazioni predefinite, clicca sul “Crea ruolo” pulsante nella parte inferiore dell'interfaccia:
Il ruolo è stato con successo creato. Clicca sul “Visualizza ruolo” pulsante:
Nel Visualizza ruolo sezione, copia il file RNA e salvalo nel Blocco note per un utilizzo futuro:
Passaggio 2: crea il cluster Redshift
Nella Console di gestione AWS, cerca e seleziona il file “Spostamento rosso” servizio:
Scorri verso il basso “Spostamento rosso” console principale e fare clic su 'Crea cluster' pulsante:
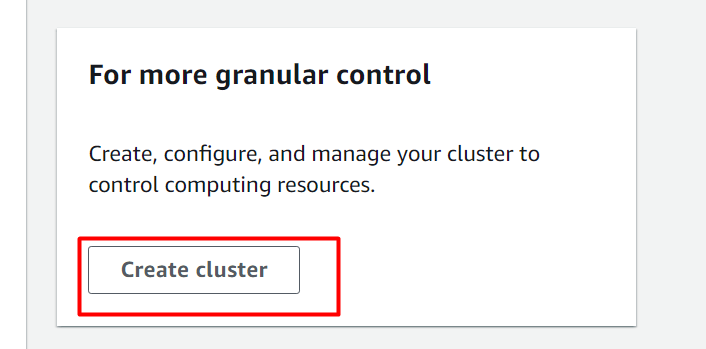
Questo porterà l'utente al file 'Crea cluster' interfaccia. Qui su questa interfaccia, fornisci un nome per il cluster e seleziona il file “dc.2 grande” per il tipo di cluster:
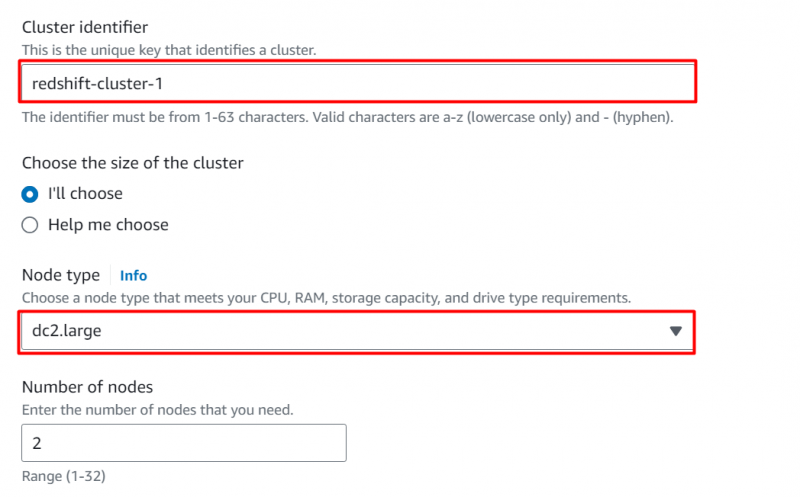
Nel Configurazioni del database sezioni, fornire a nome utente E parola d'ordine per il gruppo:
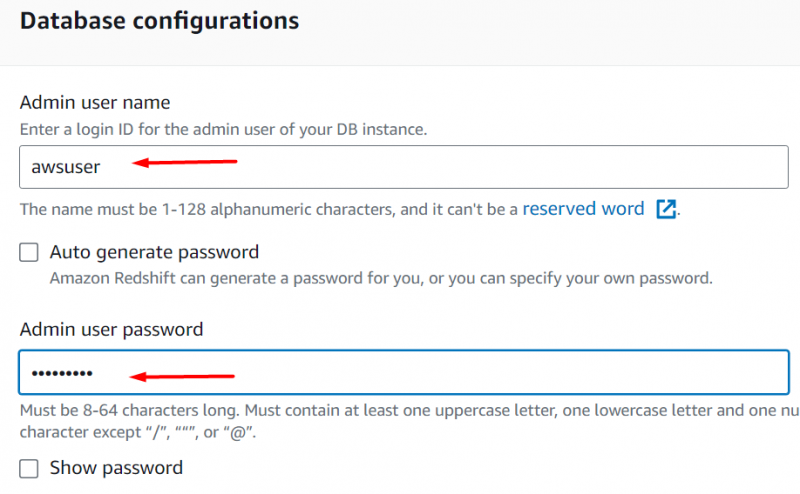
Scorri verso il basso fino a Ruoli IAM sezione. Allegheremo qui il ruolo IAM che abbiamo creato in precedenza in questo tutorial. A questo scopo, fare clic su “Ruolo IAM associato” pulsante:
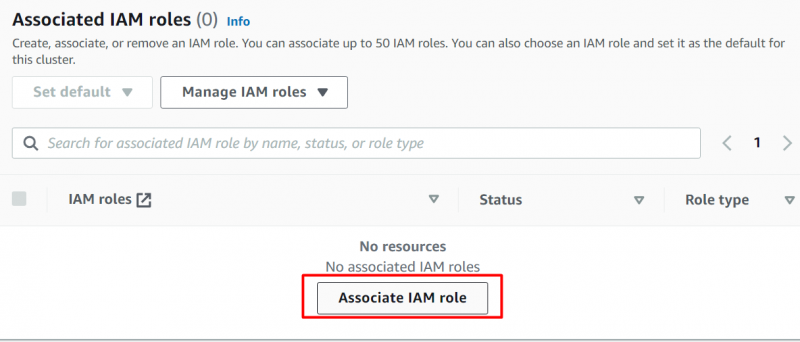
In questa sezione, abbiamo selezionato il ruolo creato e fatto clic su “Associa ruoli IAM” pulsante per allegare il ruolo:
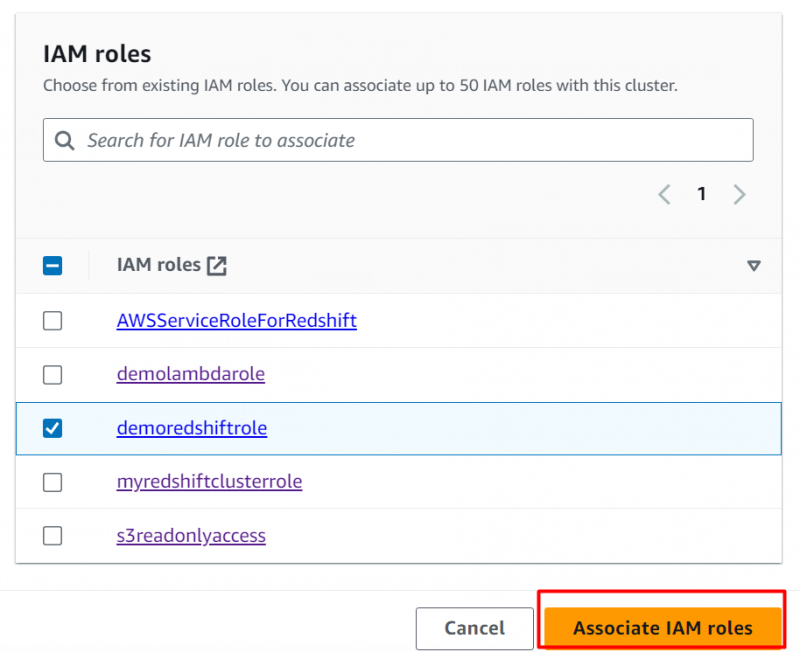
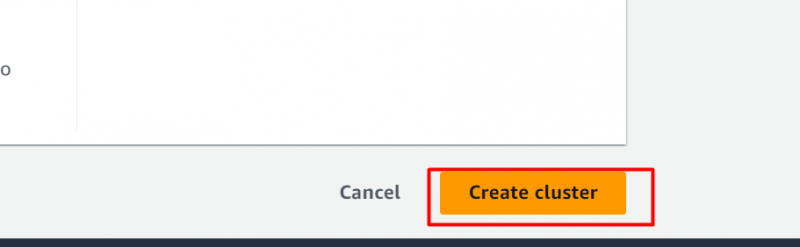
Mantenendo le impostazioni predefinite, fare clic su 'Crea cluster' pulsante nella parte inferiore dell'interfaccia:
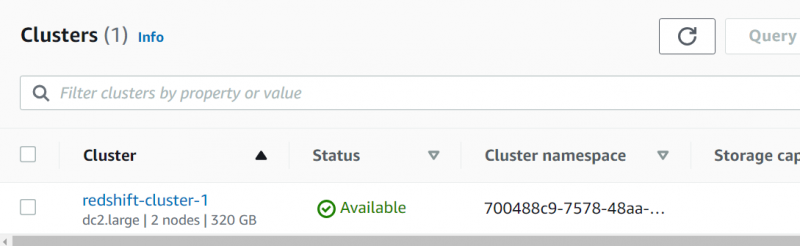
Ciò richiederà del tempo prima che il cluster sia disponibile. Clicca sul il nome del cluster dal dashboard RDS dopo la visualizzazione dello stato 'Attivo':
Passaggio 3: aggiungi autorizzazioni
Accedi al Servizio IAM dalla Console di gestione AWS a configurare una nuova politica nell'account utente root:
Dal Pannello di controllo IAM, clicca sul “Utenti” opzione dalla barra laterale di sinistra:
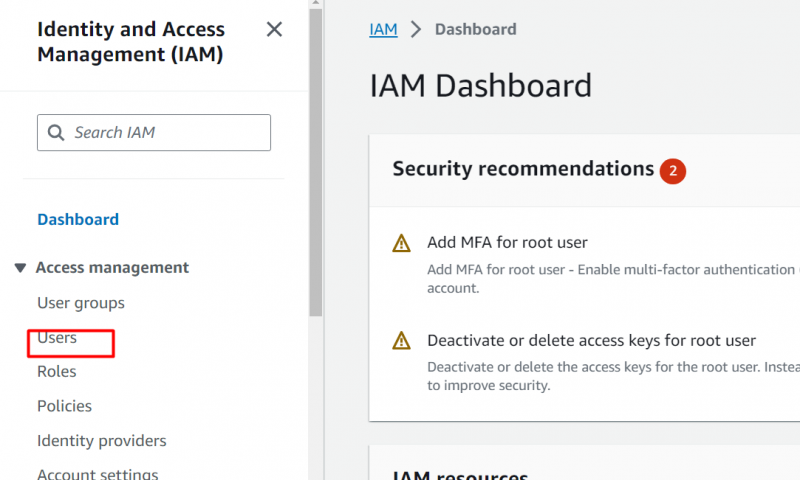
Clicca sul Nome del ruolo quello ha il accesso amministratore al conto:
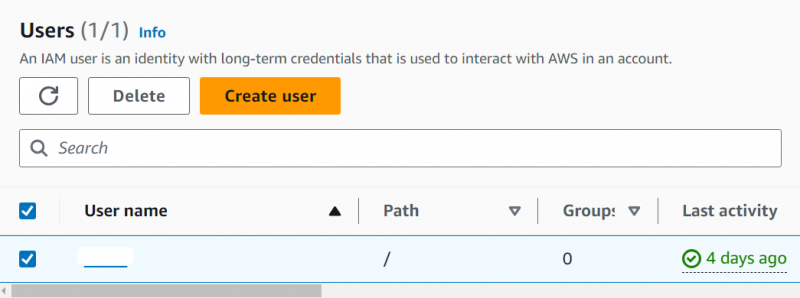
Clicca il 'Aggiungi autorizzazioni' pulsante situato sull'interfaccia:
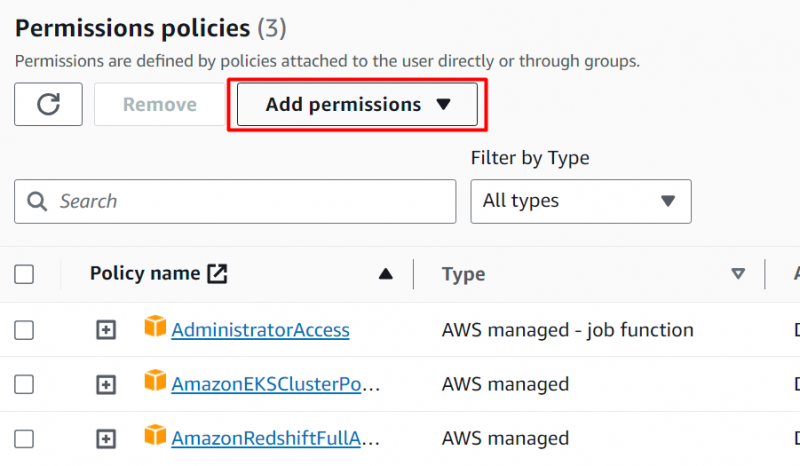
Clicca sul 'Allega direttamente le policy' opzione sotto il Opzioni di autorizzazione sezione:
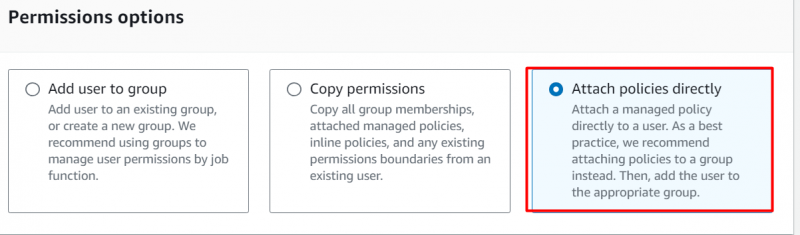
Aggiungi le seguenti autorizzazioni al tuo account:
- AmazonRedshiftQueryEditor
- AmazonRedshiftQueryEditorV2Accesso completo
- AmazonRedshiftReadOnlyAccess
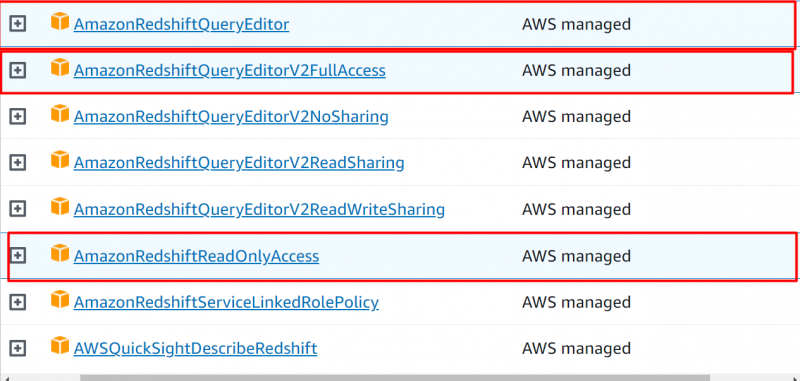
Dopo aver aggiunto le seguenti autorizzazioni, fare clic su 'Prossimo' pulsante:
Nel Riepilogo delle autorizzazioni sezione, fare clic su 'Aggiungi autorizzazioni' pulsante:
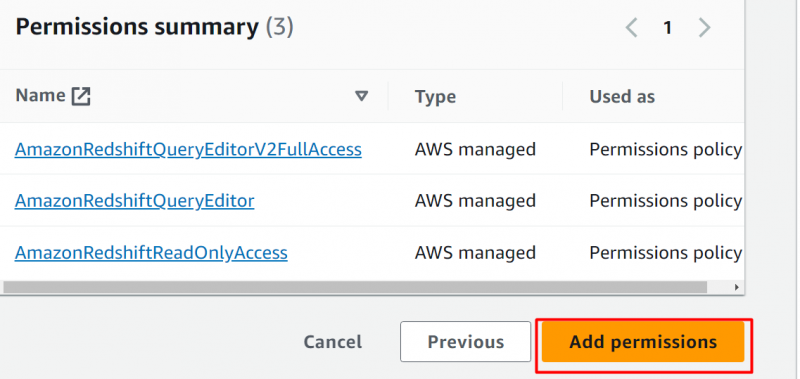
Qui le autorizzazioni sono configurate correttamente:
Passaggio 4: editor di query
Sul Pannello di controllo di AWS RDS , clicca sul 'Editor di query v2' opzione dalla barra laterale:
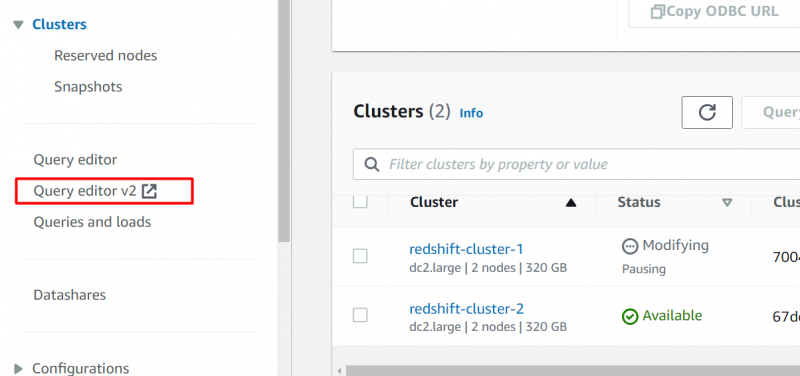
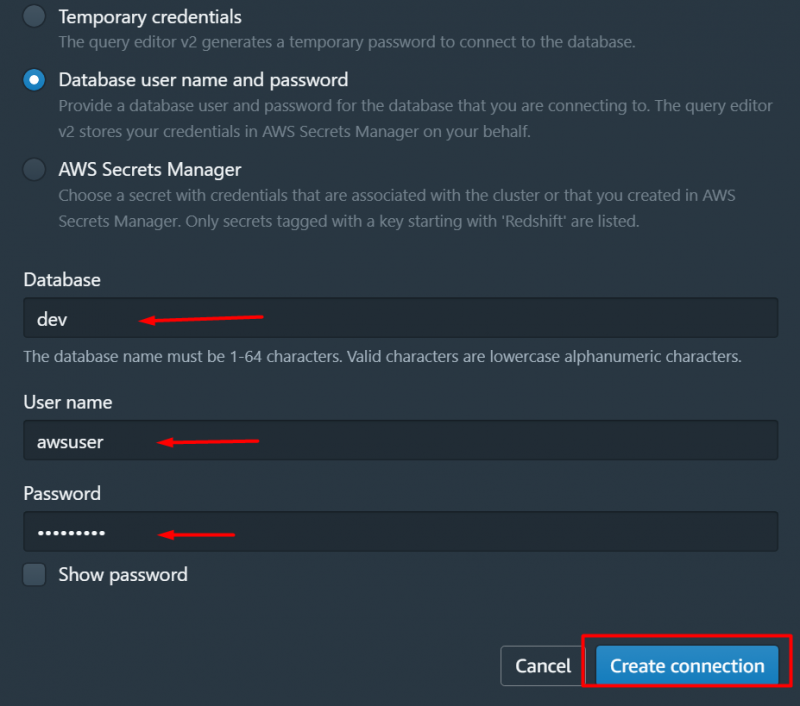
Verrà visualizzata la seguente interfaccia. Su questa interfaccia, seleziona il nome del tuo cluster e fornisci i seguenti dettagli per la connessione. Dopo aver fornito i dettagli, fare clic su “Crea connessione” pulsante:
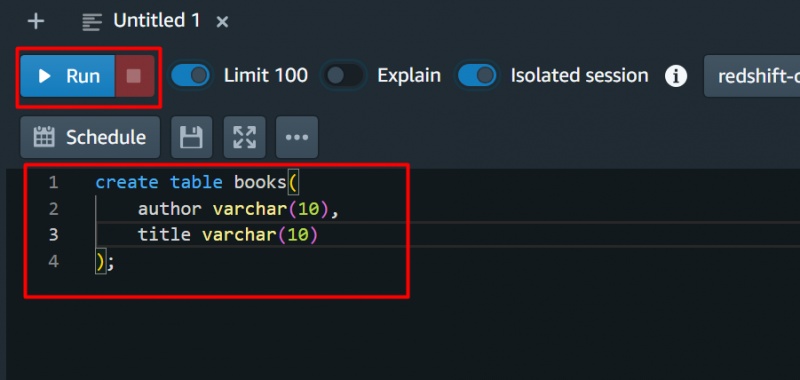
A scopo di test, forniremo la seguente query e premeremo il pulsante 'Correre' pulsante:
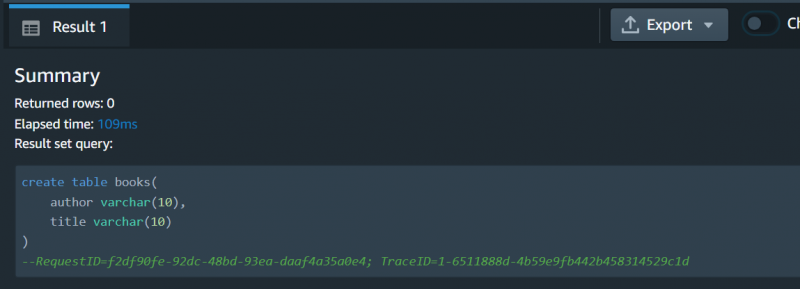
La query è stata eseguita con successo:
Questo è tutto da questa guida. Ora l'utente può eseguire diverse query in questa console, ad esempio Crea, inserisci, elimina, eccetera.
Conclusione
Per creare Data Warehousing con Redshift, configura un ruolo IAM e un'autorizzazione con il cluster RDS e fai clic sul pulsante ' Editor di query ' opzione per eseguire query. AWS Redshift è un database basato su cloud che segue la sintassi SQL ed esegue query su set di dati di grandi dimensioni in modo efficiente per prestazioni elevate. Questo articolo fornisce istruzioni per l'implementazione del data warehousing con Amazon Redshift.