Amazon Redshift è una soluzione cloud offerta da AWS che soddisfa lo scopo di un data warehouse. Un data warehouse è un grande spazio nel cloud che memorizza enormi quantità di dati. La differenza tra un data warehouse e un database è che il primo non memorizza solo i dati correnti ma anche la cronologia completa dei dati.
In questo articolo verranno fornite informazioni su Amazon Redshift di AWS e sui tipi di dati supportati da questo servizio.
Cos'è Amazon RedShift?
È una soluzione cloud per il data warehousing su cui si basa 'PostgreSQL' . Utilizza una tecnologia chiamata 'Elaborazione massivamente parallela (MPP)' per elaborare petabyte di dati alla velocità della luce. Ciò fornisce una soluzione semplice per la previsione in tempo reale basata su dati storici e soluzioni di streaming.
La figura seguente mostra il meccanismo di funzionamento di Amazon Redshift:
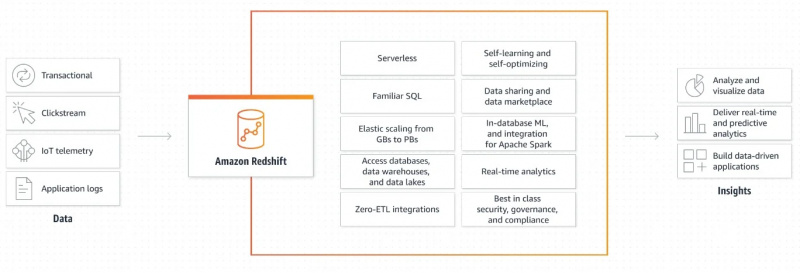
Questa spiegazione grafica di come funziona Amazon Redshift è molto semplice e chiara. Ci fornisce informazioni su come i dati vengono recuperati e ulteriormente elaborati per generare output e creare applicazioni basate sui dati.
L'architettura del data warehouse di Amazon Redshift può essere vista anche nella figura riportata di seguito:
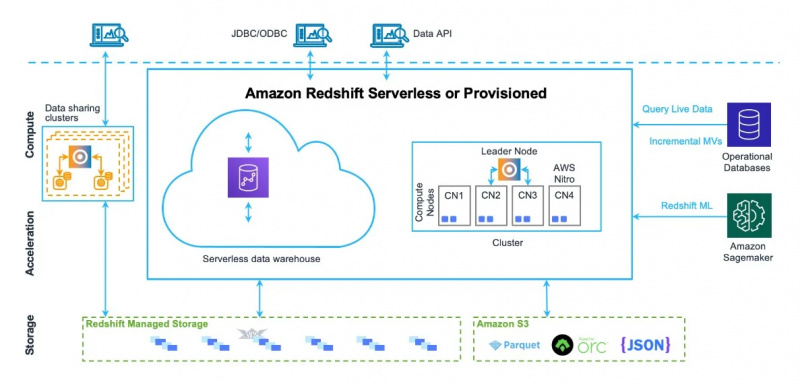
Ora andremo agli usi e alle caratteristiche di questo servizio.
Caratteristiche
Come già accennato, Amazon Redshift si basa su PostgreSQL e utilizza una tecnologia chiamata Massively Parallel Processing che gli consente di elaborare petabyte di dati in pochissimo tempo. Pertanto, Redshift offre un buon numero di funzionalità e utilizzi. Alcune di queste funzionalità sono riportate di seguito:
- Sicurezza e crittografia dei dati.
- Analisi aziendale.
- Supporto applicativo basato sui dati.
- Analisi predittiva.
- Ripetizione automatizzata delle attività.
- Scalabilità simultanea dei dati.
- Archiviazione dati.
Alcune caratteristiche extra di questo servizio possono essere viste nella figura sotto riportata:
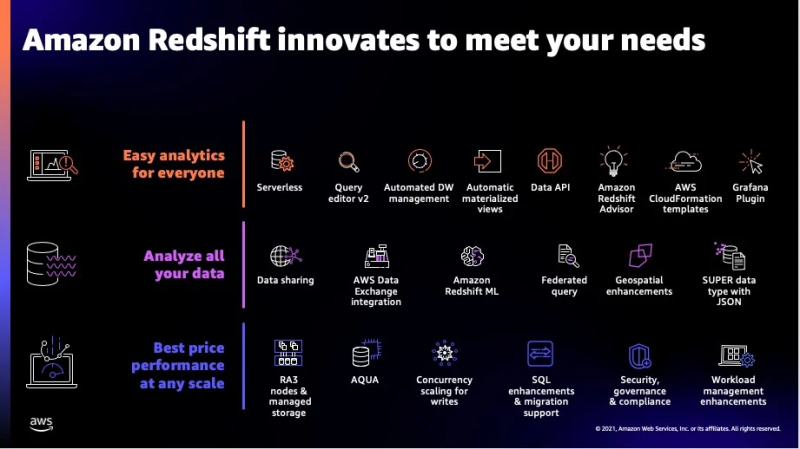
Queste erano la maggior parte delle funzionalità offerte da Redshift e ora passeremo ai tipi di dati supportati da questo servizio.
Tipi di dati
Amazon Redshift è una soluzione di data warehousing con un gran numero di funzionalità. Supporta tipi di dati strutturati e non strutturati. Poiché si basa su PostgreSQL, i dati possono essere manipolati tramite semplici query SQL.
Ora, sorge un'altra domanda, ovvero, in che modo questi formati di dati differiscono l'uno dall'altro? Discutiamo questi due formati di dati.
Dati strutturati
Un tipo di dati altamente formattati che può essere facilmente tradotto dagli algoritmi di apprendimento automatico è chiamato dati strutturati. Un database SQL funziona con dati strutturati. I dati strutturati sono in forma tabellare come i dati utilizzati dai database relazionali
Uno dei sistemi di gestione di database SQL ampiamente utilizzati è MYSQL. La sua architettura può essere vista sotto nella figura data:
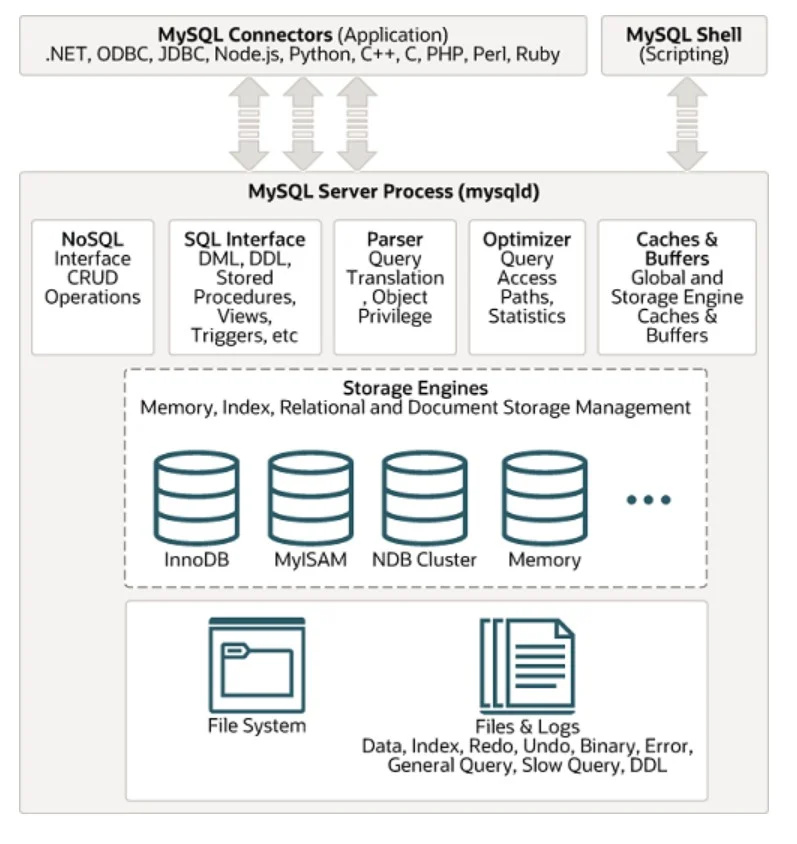
Dati non strutturati
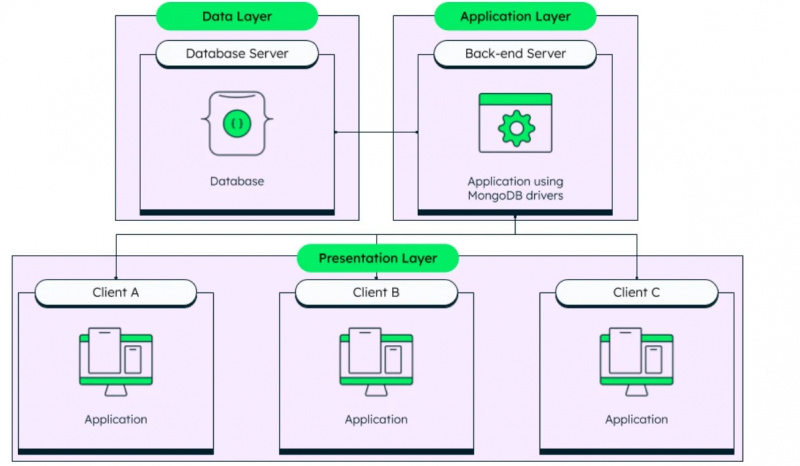
I dati non strutturati sono dati senza modello e senza formato come i dati utilizzati nei database non relazionali. MongoDB è un famoso database non relazionale. Le query SQL non funzionano su database non relazionali, quindi questi database sono anche chiamati database NoSQL.
Come già accennato, MongoDB è un sistema di gestione di database non strutturato e la sua architettura può essere vista di seguito nella figura riportata:
Abbiamo esaminato i due tipi di dati fondamentali utilizzati nei database e ora passeremo ai tipi di dati effettivi supportati da Amazon Redshift. Questi tipi di dati sono:
- Dati numerici
- Dati del personaggio
- Dati data e ora
- Dati booleani
- HLLSKETCH Dati
- Dati SUPER
- SOSTITUZIONE Dati
Discutiamo questi tipi di dati:
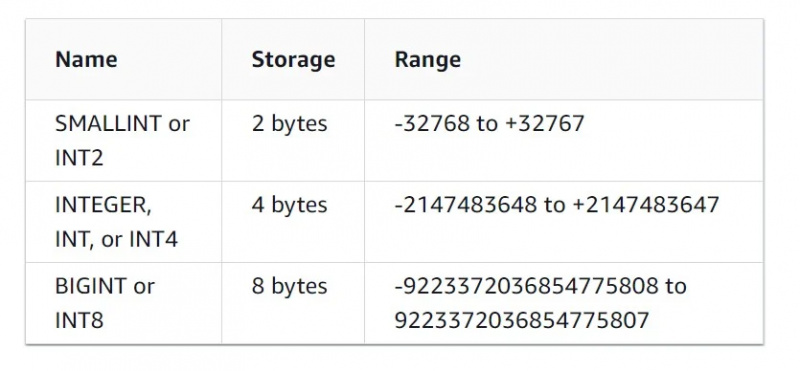
Dati numerici
Questo tipo di dati è autoesplicativo. Supporta dati sotto forma di numeri interi, decimali, virgola mobile e altri tipi di dati numerici.
Le caratteristiche del tipo di dati intero possono essere viste nella figura seguente:
Il tipo di dati decimale archivia i dati in base alla precisione dell'utente. Le sue caratteristiche sono le seguenti:

Dati del personaggio
I tipi di dati CHAR e VARCHAR rientrano nella categoria dei tipi di dati basati sui caratteri. NCHAR e NVARCHAR sono anche tipi di dati di tipo carattere. A differenza di CHAR e VARCHAR, questi due tipi di dati memorizzano caratteri Unicode a lunghezza fissa. Diamo un'occhiata alle proprietà di questi tipi di dati, come ad esempio:
- CHAR, CHARACTER, NCHAR hanno un intervallo di 4KB.
- VARCHAR, NVARCHAR ha una portata di 64 KB.
- BPCHAR ha un intervallo di 256 byte.
- TEXT ha un intervallo di 260 byte.
Dati data e ora
I tipi di dati data/ora sono DATE, TIME, TIMETZ,TIMESTAMP, TIMESTAMPTZ. Le capacità funzionali di questi tipi di dati sono le seguenti:
- DATE memorizza semplicemente le date del calendario.
- TIME memorizza l'ora senza riferimento a nessun fuso orario. È UTC, per impostazione predefinita.
- TIMETZ memorizza l'ora in riferimento al fuso orario. Per impostazione predefinita, è UTC sia nelle tabelle utente che nelle tabelle di sistema.
- TIMESTAMP non include solo l'ora ma anche le date. Per impostazione predefinita, è UTC sia nelle tabelle utente che nelle tabelle di sistema.
- TIMESTAMPTZ non include solo l'ora ma anche le date. Per impostazione predefinita, è UTC solo nelle tabelle utente.
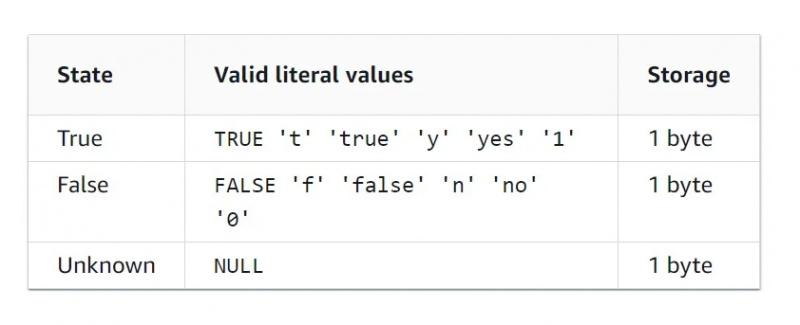
Dati booleani
Il tipo di dati booleano è un tipo di dati binari, il che significa che ci sono solo due valori. La tabella delle caratteristiche per il tipo di dati booleano è riportata di seguito nella figura:
HLLSKETCH Dati
Questo tipo di dati viene utilizzato per memorizzare gli schizzi. Redshift può rappresentare gli schizzi in forma sparsa o densa. Gli schizzi iniziano come radi e diventano gradualmente densi quando un formato denso fornisce maggiore efficienza seguendo il collegamento.
Dati SUPER
Questo tipo di dati si occupa di dati non strutturati che possono essere sotto forma di array, strutture nidificate o JSON. Non esiste un modello o un formato dei dati. Gli utenti possono esplorare ulteriori informazioni navigando sul collegamento.
SOSTITUZIONE Dati
Questo tipo di dati memorizza anche i caratteri. Tuttavia, la lunghezza è limitata. Amazon Redshift consente il cast di dati VARBYTE in qualsiasi tipo di dati di tipo intero o carattere. Per ottenere ulteriori informazioni su questo tipo di dati, seguire il collegamento sottostante.
Questo è tutto ciò che c'è in Amazon Redshift e nei tipi di dati che supporta.
Conclusione
Amazon Redshift è un servizio AWS che nella sua forma base ha lo scopo di un data warehouse ma è una soluzione molto potente e ricca di funzionalità per l'analisi e la previsione. Questo articolo ha discusso di Redshift e dei tipi di dati che supporta. Questi tipi di dati sono stati spiegati brevemente insieme alle loro caratteristiche.