Questo post riguarda il partizionamento PostgreSQL. Discuteremo le diverse opzioni di partizionamento che è possibile utilizzare e forniremo esempi su come utilizzarle per una migliore comprensione.
Come creare le partizioni PostgreSQL
Qualsiasi database può contenere numerose tabelle con più voci. Per una facile gestione, è necessario partizionare le tabelle, che è un'ottima e consigliata routine di data warehouse per l'ottimizzazione del database e per aumentare l'affidabilità. Puoi creare diverse partizioni tra cui elenco, intervallo e hash. Discutiamo ciascuno in dettaglio.
1. Elenco partizionamento
Prima di considerare qualsiasi partizionamento, dobbiamo creare la tabella che utilizzeremo per le partizioni. Quando crei la tabella, segui la sintassi fornita per tutte le partizioni:
CREATE TABLE nome_tabella(tipo_dati colonna1, tipo_dati colonna2) PARTITION BY
Il 'nome_tabella' è il nome della tabella insieme alle diverse colonne che avrà la tabella e ai relativi tipi di dati. Per 'partition_key', è la colonna in base alla quale avverrà il partizionamento. Ad esempio, l'immagine seguente mostra che abbiamo creato la tabella 'corsi' con tre colonne. Inoltre, il nostro tipo di partizionamento è LIST e selezioniamo la colonna facoltà come chiave di partizionamento:

Una volta creata la tabella, dobbiamo creare le diverse partizioni di cui abbiamo bisogno. Per questo, procedi con la seguente sintassi:
CREATE TABLE tabella_partizione PARTIZIONE DI tabella_principale FOR VALUES IN (VALUE);Ad esempio, il primo esempio nell'immagine seguente mostra che abbiamo creato una tabella di partizione denominata 'Fset' che contiene tutti i valori nella colonna 'facoltà' che abbiamo selezionato come chiave di partizione il cui valore è 'FSET'. Abbiamo utilizzato una logica simile per le altre due partizioni che abbiamo creato.
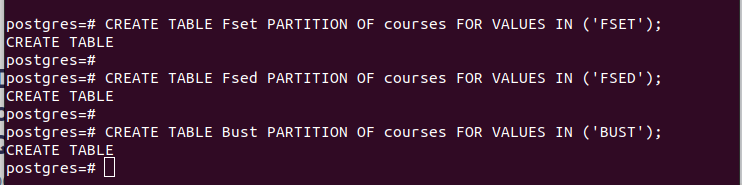
Una volta che hai le partizioni, puoi inserire i valori nella tabella principale che abbiamo creato. Ogni valore inserito viene abbinato al rispettivo partizionamento in base ai valori nella chiave di partizione selezionata.
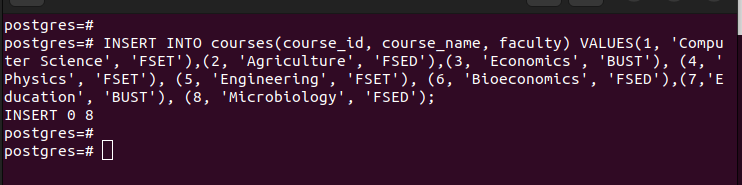
Se elenchiamo tutte le voci nella tabella principale, possiamo vedere che contiene tutte le voci che abbiamo inserito.
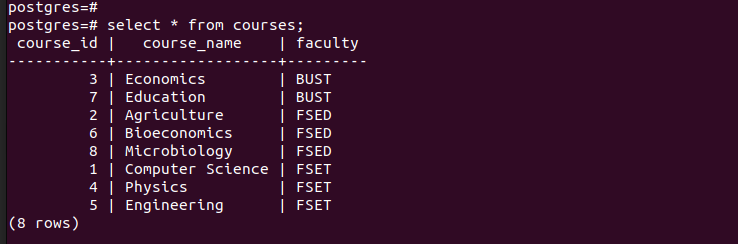
Per verificare che abbiamo creato correttamente le partizioni, controlliamo i record in ciascuna delle partizioni create.
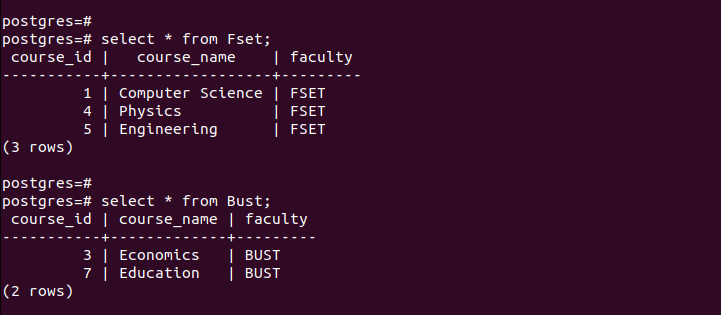
Si noti come ciascuna tabella partizionata contenga solo le voci che corrispondono ai criteri definiti durante il partizionamento. Ecco come funziona il partizionamento per elenco.
2. Partizionamento dell'intervallo
Un altro criterio per creare partizioni è utilizzare l'opzione RANGE. Per questo, dobbiamo specificare i valori iniziale e finale da utilizzare per l'intervallo. L'uso di questo metodo è ideale quando si lavora con le date.
La sua sintassi per creare la tabella principale è la seguente:
CREATE TABLE nome_tabella(tipo_dati colonna1, tipo_dati colonna2) PARTIZIONE PER INTERVALLO (chiave_partizione);Abbiamo creato la tabella 'cust_orders' e l'abbiamo specificata per utilizzare la data come 'partition_key'.

Per creare le partizioni, utilizzare la seguente sintassi:
CREATE TABLE tabella_partizione PARTIZIONE DI tabella_principale PER VALORI DA (valore_iniziale) A (valore_finale);Abbiamo definito le nostre partizioni in modo che funzionino trimestralmente utilizzando la colonna 'data'.
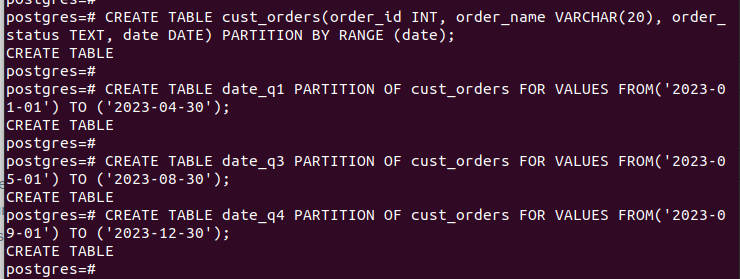
Dopo aver creato tutte le partizioni e inserito i dati, ecco come appare la nostra tabella:
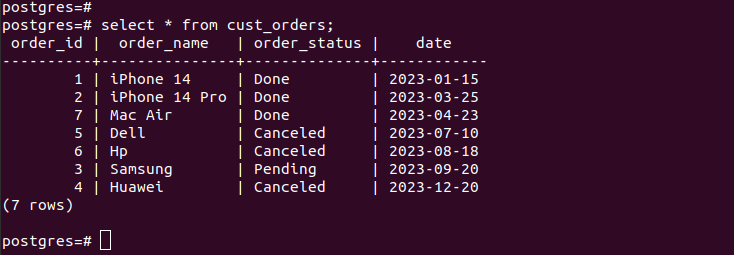
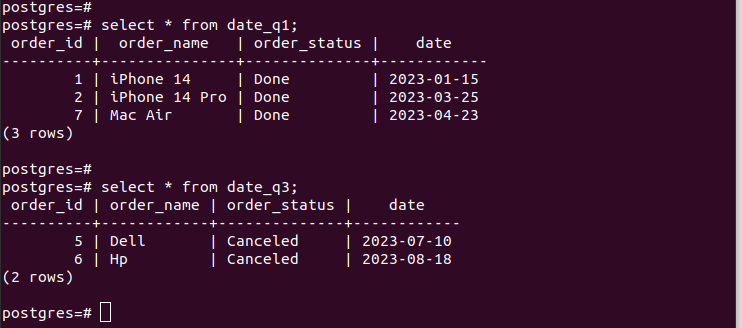
Se controlliamo le voci nelle partizioni create, verifichiamo che il nostro partizionamento funzioni e disponiamo solo dei record appropriati secondo i criteri di partizionamento che abbiamo specificato. Per tutte le nuove voci che aggiungi alla tabella, vengono aggiunte automaticamente alla rispettiva partizione.
3. Partizionamento hash
L'ultimo criterio di partizionamento di cui parleremo è l'utilizzo dell'hash. Creiamo rapidamente la tabella principale utilizzando la seguente sintassi:
CREATE TABLE nome_tabella(tipo_dati colonna1, tipo_dati colonna2) PARTIZIONE PER HASH (chiave_partizione); 
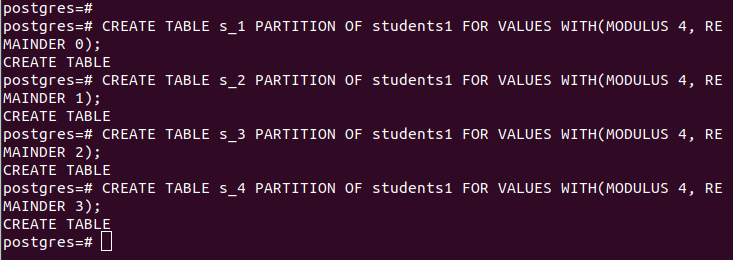
Quando si esegue il partizionamento con hash, è necessario fornire il modulo e il resto, le righe da dividere per il valore hash della “partition_key” specificata. Nel nostro caso utilizziamo il modulo 4.
La nostra sintassi è la seguente:
CREATE TABLE tabella_partizione PARTIZIONE DI tabella_principale PER VALORI CON (MODULO num1, RESTO num2);Le nostre partizioni sono le seguenti:
Per 'main_table', contiene le voci mostrate di seguito:
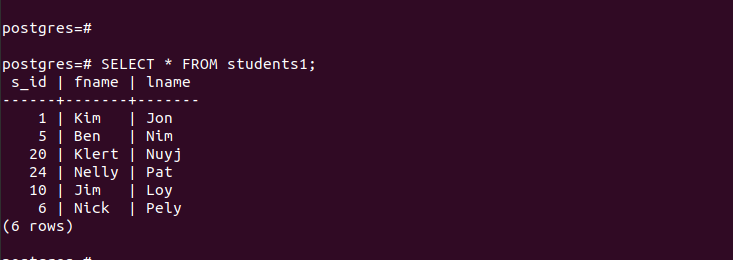
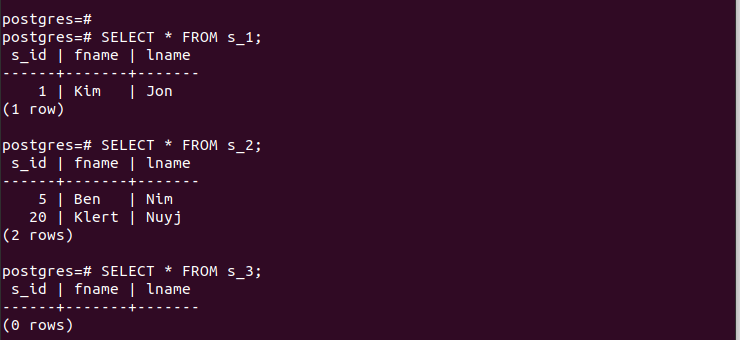
Per le partizioni create, possiamo accedere rapidamente alle loro voci e verificare che il nostro partizionamento funzioni.
Conclusione
Le partizioni PostgreSQL sono un modo pratico per ottimizzare il database per risparmiare tempo e migliorare l'affidabilità. Abbiamo discusso in dettaglio il partizionamento, comprese le diverse opzioni disponibili. Inoltre, abbiamo fornito esempi su come implementare le partizioni. Provali!