'Pandas' è uno strumento ad alte prestazioni per l'ambiente Python. È un codice sorgente “aperto” per l'analisi dei dati. Il metodo pandas join e pandas merge viene utilizzato per unire i due dataframe in un unico dataframe. In entrambi i metodi di panda, la differenza è che la funzione 'join' di panda si unisce al dataframe usando un indice. Mentre la funzione 'merge' dei panda si unisce al dataframe utilizzando il metodo index e column in cui possiamo selezionare noi stessi la colonna desiderata. Il metodo di unione dei panda viene utilizzato principalmente rispetto al metodo di unione dei panda. Il software che useremo per l'implementazione è il software 'spyder', che si trova nell'ambiente python che ci fornirà vantaggi per l'implementazione del codice del metodo panda join() e della funzione del metodo panda merge().
Sintassi del metodo Pandas Join()
“df1. giuntura ( df2 ) 'Il 'df' nella sintassi sopra è l'abbreviazione di 'dataframe'. Ci sono due dataframe nella sintassi con la funzione 'dot join', che serve per chiamare il metodo. È il metodo dei panda per unire due frame di dati. Funziona utilizzando l'indice per combinare i frame di dati in uno solo.
Sintassi del metodo Pandas Merge()
“df1. unire ( df2 , Su = 'nome_colonna' ) 'La sintassi del metodo di unione panda ha due frame di dati come 'df1' e 'df2'. La funzione 'dot merge' richiama il metodo per unire entrambi i dataframe con l'aspetto di colonne invertite.
Tratteremo i seguenti modi per combinare due dataframe per utilizzare i metodi di panda merge e panda join:
- Sovrapposizione del metodo Pandas Join.
- I panda si uniscono al metodo usando un ripristino dell'indice.
- Metodo di unione dei panda (colonna 'sinistra e destra').
- Metodo di unione dei panda esplicito.
Creazione dei dataframe per l'implementazione del metodo Pandas Merge e Pandas Join
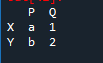
Innanzitutto, dobbiamo creare un frame di dati. Per questo, utilizzeremo lo strumento 'spyder'. Dopo averlo aperto, inizia a scrivere il codice. Importa i panda come 'pd' per l'associazione delle biblioteche dei panda. Abbiamo le variabili dataframe come 'x', 'y', 'p' e 'q corrispondentemente e 'a' con valori '1' e 'b' con il valore assegnato come '2'.

L'uscita è un “df” creato con i valori assegnati. Possiamo renderlo grande quanto i dati.
Creazione di un altro dataframe
Dobbiamo creare un altro dataframe, per comprendere i metodi di unione dei panda e della fusione dei panda in modo chiaro. Qui, abbiamo 'df' creato come il 'df' sopra, solo i valori sono variabili assegnati sono diversi. Abbiamo “h”, “j”, “s” e “d”, mentre assegniamo i valori “b” con il valore “8” e “Y” con il valore “3”.

L'output mostra un semplice 'df' creato.

Esempio n. 01: metodo di unione Pandas (sovrapposto)
Ora vedremo come unire due dataframe con il metodo di unione panda. Per questo metodo, possiamo scegliere la colonna di tua scelta su cui vogliamo lavorare dal dataframe. Abbiamo preso l'esempio con la colonna sovrapposta 'sinistra' dal 'df', quindi possiamo correggere questo con il 'suffisso' per superare la sovrapposizione di dati. Qui, le variabili utilizzate sono “x”, “z”, “v”, “d”. “p”, “o”, “l” e “y” con i valori assegnati come “3”, “6”, “7” e “9”. Il '.join' chiama il metodo, con l'allineamento impostato su join sinistro con il suffisso 'df' destro. ”. Il 'suffisso' utilizzato nel codice è perché nel dataframe ci sono due colonne che hanno lo stesso nome che è 'chiave' e che non si sovrapporranno ai dati.
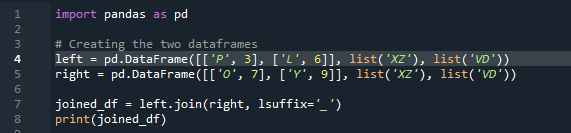
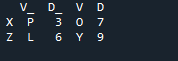
L'output non mostra dati sovrapposti con il metodo di unione di due 'df' utilizzando il metodo di unione panda.
Esempio n. 02: metodo di unione di Panda utilizzando un ripristino dell'indice
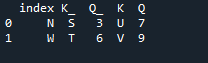
In questo esempio, specificheremo separatamente la colonna con il parametro 'on' da utilizzare come 'chiave' nel metodo join che aiuta a unire i due dataframe. la cosa combinata è fatta con questo parametro. Inoltre, l'indice di uno dei due 'df' dovrebbe essere simile per unirli. Tipi simili di dati o dati utilizzati per la stessa finalità possono essere riuniti per l'elaborazione. Questo utilizzerà l'indice ancora, usando da destra. Le variabili sono “s”, “t”, “u”, “v”, “n”, “w”, “k” e “q”. I valori assegnati sono “3”, “6”, “7” e “9”. Il 'reset dot index' è un metodo di panda per ripristinare l'indice del 'df'. L'indice di ripristino imposta tutti i numeri interi dell'elenco dei frame di dati da 0 fino a quando i dati del frame di dati non vengono allungati.
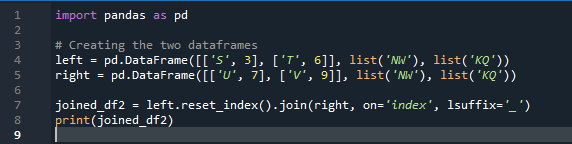
Ecco l'output visualizzato con il metodo di unione della 'chiave' dell'indice dei panda.
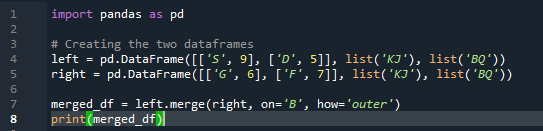
Esempio n. 03: Metodo di unione Pandas (colonna 'sinistra e destra')
Il metodo di unione esegue un'operazione simile al metodo di unione dei panda. Entrambi i metodi servono per combinare i dati su un dataframe simile. Il metodo di unione è più versatile e richiede la specifica della chiave. Possiamo anche specificarlo nelle colonne sinistra e destra a seconda del lavoro del tuo dataframe. Le variabili nel codice sono “s”, “d”, “g”, “f”, “k”, “j”, “b” e “q”. i valori assegnati sono “9”, “5”, “6” e “7”. L'implementazione esterna del 'join' viene eseguita su entrambi i 'df' utilizzando il parametro 'how' della funzione del metodo di unione panda.
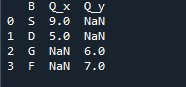
L'output che vediamo mostra i dati uniti dei due dataframe. Il 'NaN' rappresenta 'non un numero', il che significa che dove non c'è un numero assegnato nei dati, il 'NaN' mostra lì.
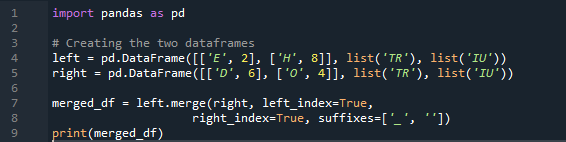
Esempio n. 04: il metodo di unione in modo esplicito
Qui, in questo esempio, il metodo di unione è la distruzione dell'indice e il valore dell'indice non viene assunto sul dataframe. Faremo questo metodo in base al lavoro necessario, in cui l'esplicito di specificazione deve essere seguito. Unirà i dati basati su un indice sinistro o un indice destro con il parametro. Le variabili in questo dataframe sono “t”, “r”, “I”, “u”, “h”, “o”, “e” ed “e”. I valori assegnati sono “2”, “4”, “6” e “4”. L'esempio sopra del metodo di unione dei panda con la selezione delle colonne in base alle esigenze è il metodo più presentabile e prezioso per unire i due frame di dati. Verifica alla fine della riga di codice che la chiave di unione sia univoca nel set di dati.
Nell'output sottostante l'indice non viene mostrato senza l'indice ma la funzione viene eseguita in base all'indice destro e sinistro.
Conclusione
I metodi merge() e join() sono entrambi metodi molto convenienti ed efficaci. Entrambe queste funzioni vengono utilizzate per unire i due dataframe separati sullo stesso dataframe ma hanno un uso diverso a seconda dei casi. In questo articolo, abbiamo appreso le principali differenze tra il metodo di unione e unione dei panda. Dopo aver fatto gli esempi e aver compreso il metodo di unione dei panda, lo concluderemo con la consapevolezza che, se vogliamo unire più flessibili e in stile database, è preferibile utilizzare il metodo di unione dei panda. D'altra parte, se vogliamo combinare ampiamente il dataframe con l'indice, possiamo utilizzare la funzione del metodo panda join().