'I 'Panda' è un ottimo linguaggio per eseguire l'analisi dei dati grazie al suo grande ecosistema di pacchetti Python incentrati sui dati. Ciò semplifica l'analisi e l'importazione di entrambi i fattori. La deviazione standard è una deviazione “tipica” derivata dalla media. È molto utilizzato, in quanto restituisce le unità di misura originali del dataframe. I panda hanno utilizzato std() per il calcolo della deviazione standard. La deviazione standard può essere calcolata dai valori forniti che possono trovarsi nel dataframe sotto forma di riga o colonna. Implementeremo tutti i modi possibili in cui viene utilizzata la deviazione standard dei panda. Per l'implementazione del codice, utilizzeremo lo strumento 'spyder' poiché è scritto in un ambiente python-friendly.'
Sintassi
“df.std ( ) '
La seguente sintassi viene utilizzata per calcolare la deviazione standard nel frame di dati. Il 'df' nel dataframe è l'abbreviazione del 'dataframe'. A cosa serve la deviazione standard? Misura l'estensione dei dati richiesti. Più alti sono i valori espansi, maggiore dovrebbe verificarsi la deviazione standard.
Ritorno
La deviazione standard panda restituisce il dataframe se il livello è specificato in base al requisito.
Si noti che la funzione 'std()' ignorerà automaticamente i valori 'NaN' in 'df' durante il calcolo della deviazione standard dei panda. 'NaN' può essere spiegato come 'non un numero', il che significa che non c'è alcun valore assegnato a un particolare.
Di seguito sono riportati i metodi che verranno eseguiti con esempi della deviazione standard dei panda:
-
- Calcolo della deviazione standard di Panda in un'unica colonna.
- Calcolo della deviazione standard di Panda in più colonne.
- Calcolo della deviazione standard di Pandas di tutte le colonne numeriche.
- deviazione standard panda usando l'asse = 1.
- deviazione standard panda usando l'asse = 0.
Creazione del dataframe per il calcolo della deviazione standard nei Panda
Innanzitutto, apri il software 'spyder'. Ora importa la libreria panda come pd. Creeremo un dataframe che consiste in un tabellone segnapunti con termini come 'x', 'y' e 'z' con i loro punti come '22', '10', '11', '16', '12', '45 ”, “36” e “40”. Abbiamo i loro valori di assist come '8', '9', '13', '7', '22', '24', '4' e '6', avendo anche il valore dei rimbalzi come '17', ' 14”, “3”, 5”, “9”, “8”, “7” e “4”.
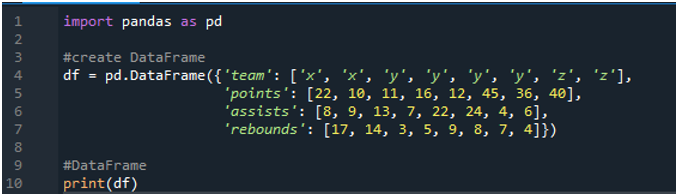
I display mostrano il dataframe creato in base ai valori assegnati nel codice:

Esempio n. 01: calcolo della deviazione standard di Panda in una singola colonna
In questo esempio, calcoleremo la deviazione standard di una singola colonna nel dataframe panda. Il dataframe ha i valori della squadra come “u”, “v” e “b” con i loro punti come “44”, “33”, “22”, “44”, “45”, “88”, “96 ” e “78”. I valori degli assist sono come “7”,”8”, “9”, “10”, “11”, “14”, “18” e “17” avendo anche i valori dei rimbalzi come “11”, “ 9”, “8”, “7”, “6”, “5”, “4” e “3”. La colonna 'punti' viene selezionata dal dataframe per calcolare la deviazione standard della singola colonna.
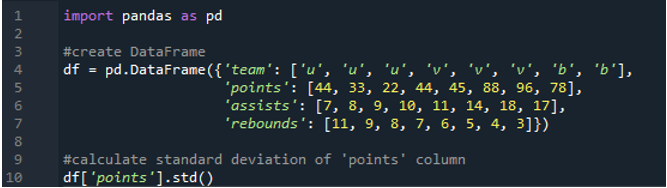
L'output mostra la deviazione standard calcolata della colonna 'punti':

Esempio n. 02: calcolo della deviazione standard di Panda in più colonne
In questo esempio, eseguiremo i calcoli della deviazione standard dei panda in più colonne. In questo dataframe, i dati sono sempre del tabellone sportivo avente i valori della squadra come “n”, “w” e “t” con il punteggio come “33”, “22”, “66”, “55”, “44”, “88”, “99” e “77”. Gli assist come “9”, “7”, “8”, “11”, “16”, “14”, “12” e “13” e rimbalzi come “5”, “8”, “1”, “ 2”, “3”, “4”, “6” e “7”. Qui calcoleremo la deviazione standard delle due colonne 'punti' e 'rimbalzi' utilizzando la funzione std() applicata al dataframe.
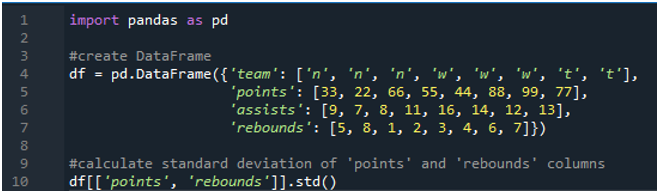
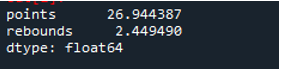
Come si vede, l'output mostra che la deviazione standard è risultata rispettivamente pari a 26,944387 nella colonna dei punti e 2,449490 nella colonna del rimbalzo.
Esempio n. 03: Calcolo della deviazione standard di Pandas di tutte le colonne numeriche
Ora abbiamo imparato come calcolare la deviazione standard di righe singole e multiple. Cosa succede se non vogliamo specificare tutti i nomi di colonna nel dataframe e calcolare l'intero dataframe? Ciò è possibile con una semplice implementazione della funzione della deviazione standard panda per il calcolo dell'intero dataframe nei risultati. Il dataframe qui è composto da 'l', 'm' e 'o' con i valori di punteggio '33', '36', '79', '78', '58', '55' e due squadre ottengono lo stesso punteggio cioè '25'. Gli assist sono “1”, “2”, “3”, “4”, “6”, “9”, “5” e “7” e i loro rimbalzi come “14”, “10”, “2” , “5”, “8”, “3”, “6” e “9”. Possiamo calcolare tutte le deviazioni standard delle colonne dei panda nel dataframe usando la funzione 'std()' dei panda.
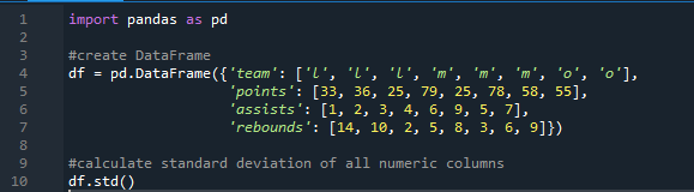
Il display ha la deviazione standard calcolata dell'intero “df” mostrato di seguito; possiamo anche notare che i panda non hanno calcolato la deviazione standard della prima colonna, che è “squadra”, perché non è una colonna numerica.
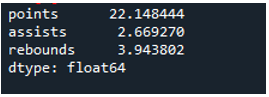
Esempio n. 04: Deviazione standard di Panda utilizzando l'asse = 0
In questo esempio, i dataframe hanno le squadre degli sport come 'g', 'h' e 'k' con ulteriori dati. Qui calcoleremo la deviazione standard utilizzando l'asse come '0', un parametro utilizzato nella deviazione standard dei panda. Questo argomento calcola la deviazione standard per colonna del frame di dati.
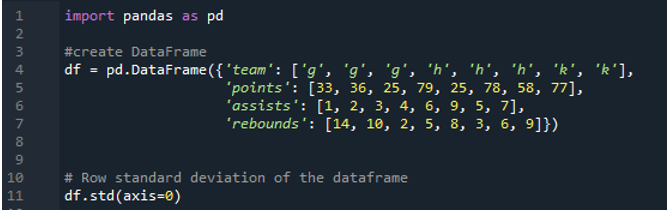
L'output seguente mostra i risultati in colonne della deviazione standard calcolata. La colonna dei punti ha la deviazione standard calcolata come '24,0313062', la colonna degli assist ha la deviazione standard calcolata come '2,669270' e la deviazione standard calcolata della colonna del rimbalzo è mostrata come '3,943802'.
Esempio n. 05: Deviazione standard di Panda utilizzando l'asse = 1
Qui useremo il parametro dell'asse assegnato come '1' per calcolare la deviazione standard nei panda. Che differenza può fare l'asse '1'? L'argomento dell'asse '1' calcola la deviazione standard per riga dei valori numerici nel frame di dati. Il dataframe ha le tre squadre come 's', 'd' ed 'e', con l'aggiunta di colonne di dati create come punti della squadra, assist della squadra e rimbalzi della squadra. Le direzioni sono tutte assegnate con valori diversi nel dataframe. Questo parametro dell'asse è un tale punto di svolta in quanto, per il momento, dobbiamo lavorare sui dati dove vogliamo che si trovino in una colonna più il punto calcolato della deviazione standard eseguita.
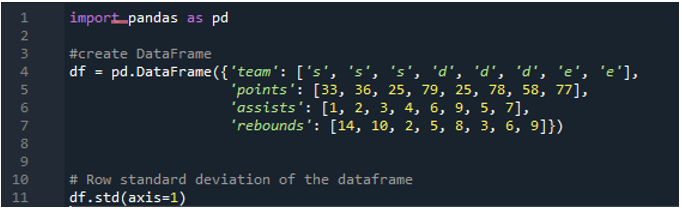
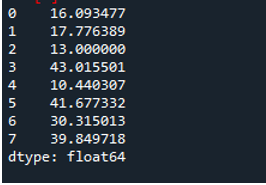
Il seguente output mostra la deviazione standard calcolata in una riga del frame di dati:
Conclusione
La deviazione standard di Panda è una funzione molto tecnica, che è una funzione molto vantaggiosa in quanto trova la deviazione standard del patto di entusiasmo dei dataframe di Panda. In questo editoriale abbiamo studiato i metodi per calcolare la deviazione standard nei panda. Abbiamo eseguito calcoli a colonna singola della deviazione standard e più colonne e abbiamo anche calcolato la deviazione standard dell'intero frame di dati insieme. Tutte le strategie funzionano bene fintanto che vengono utilizzate in modo coerente e con i risultati desiderati.