Questa guida spiegherà i crawler dell'elenco in AWS.
Cosa sono i crawler di elenchi in AWS?
Un crawler è un componente di AWS Glue che viene utilizzato per eseguire la scansione della posizione dei dati e dedurre tali informazioni nel catalogo. Le informazioni raccolte da un crawler possono essere tipi di dati, struttura dello schema o, in altre parole, raccogliere metadati. Il crawler può essere utilizzato anche con il catalogo dati che viene utilizzato quando i dati vengono spostati all'interno dell'ecosistema Glue durante l'utilizzo di lavori ETL, ecc.
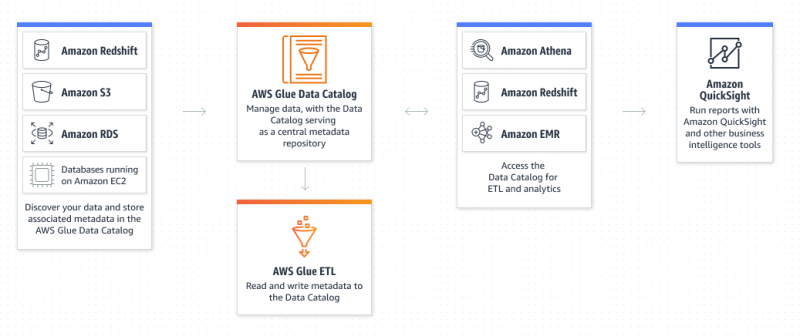
Che cos'è Amazon Glue Service?
AWS Glue è un servizio Amazon Extract Transform and Load che consente all'utente di organizzare, individuare, spostare e trasformare tutti i dati. AWS Glue è serverless in quanto l'utente non deve eseguire il provisioning e configurare i server o gestire i cicli di vita. Il catalogo dati e i crawler sono i componenti di AWS Glue che funge da repository di metadati persistente:

Come creare un crawler su AWS?
Per creare un crawler su AWS, visita il servizio AWS Glue dalla Console di gestione AWS:
Entra nel “ Crawler ” facendo clic sul suo nome dal pannello di sinistra:
Clicca sul ' Crea crawler pulsante ':
Digita il nome del crawler e fai clic su ' Prossimo pulsante ':
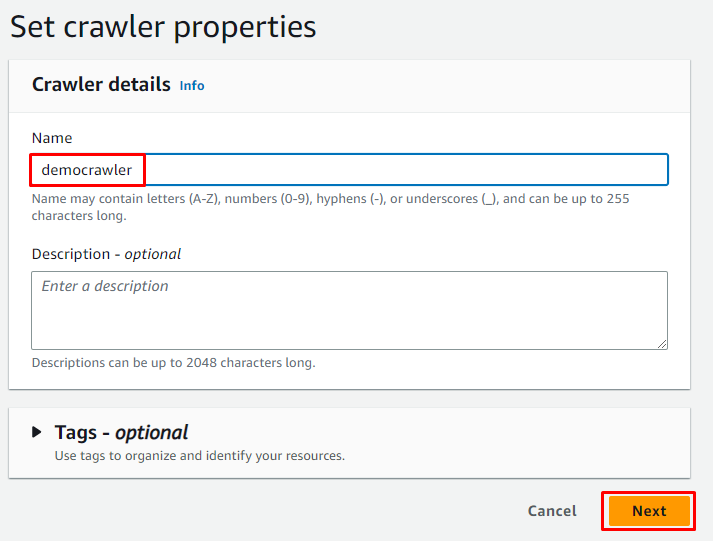
Selezionare l'opzione di mappatura per le tabelle di colla e fare clic su ' Aggiungi una fonte Pulsante ' per ottenere i dati da:

Seleziona il servizio S3 e fai clic su ' Sfoglia S3 Pulsante ' per ottenere la posizione della fonte:

Basta selezionare la cartella S3 e fare clic su ' Scegliere pulsante ':

Una volta aggiunta la posizione alla fonte, è sufficiente fare clic sul pulsante ' Aggiungi un'origine dati S3 pulsante ':
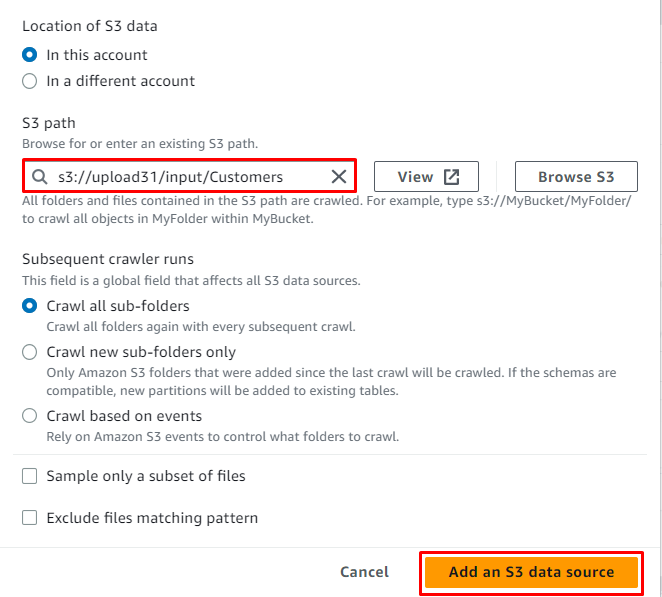
Clicca sul ' Prossimo pulsante ':

Clicca sul ' Crea un nuovo ruolo IAM ” pulsante dal “ Configura le impostazioni di sicurezza ' sezione:
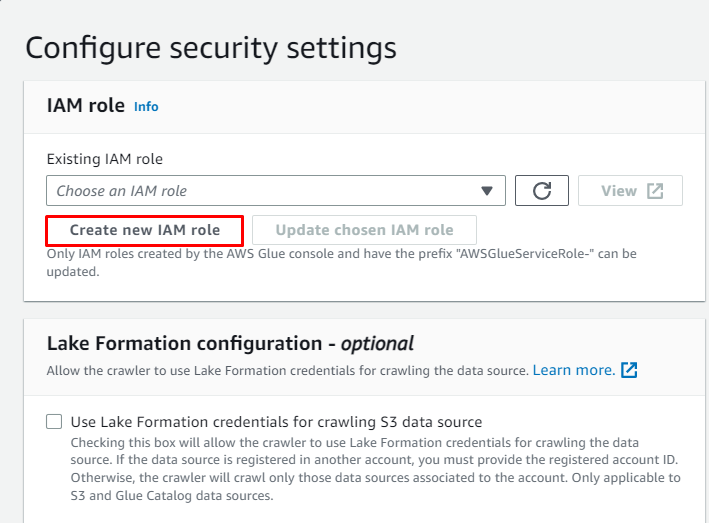
Inserisci il nome del ruolo e fai clic su ' Creare pulsante ':
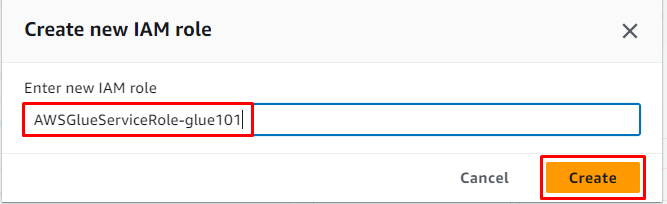
Successivamente, fai semplicemente clic su ' Prossimo pulsante ':

Seleziona il database di destinazione e digita il nome che verrà utilizzato per la tabella:
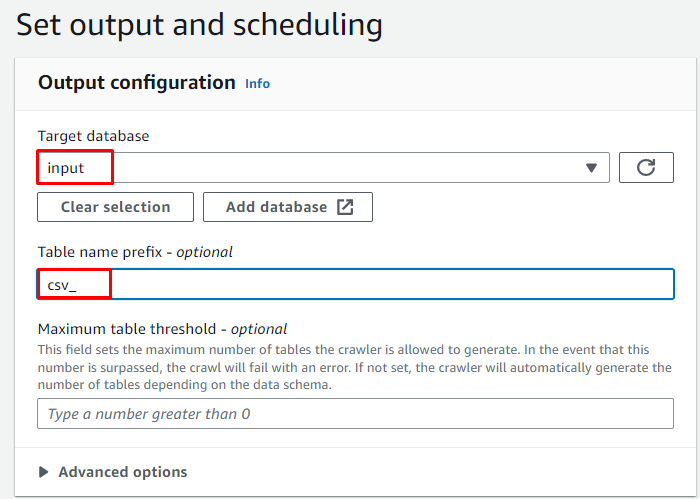
Pianifica il crawler per ' Su richiesta ' e fare clic su ' Prossimo pulsante ':
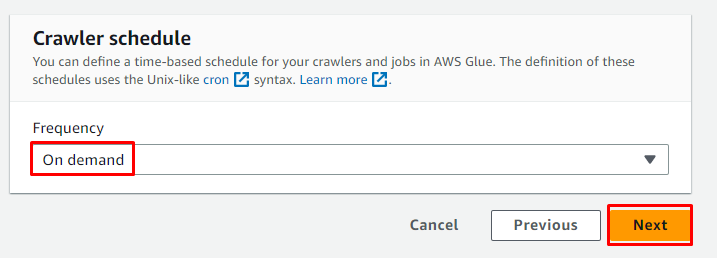
Rivedere la configurazione e fare clic su ' Crea crawler pulsante ':
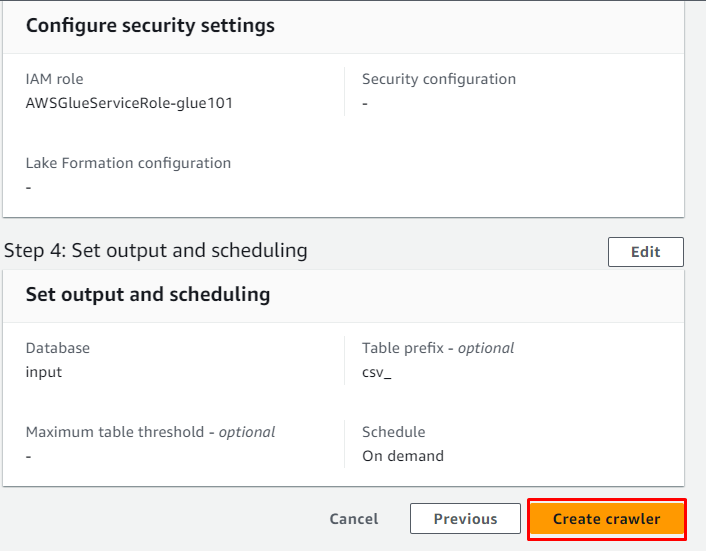
Il crawler è stato creato correttamente e può essere utilizzato per recuperare i dati dalla fonte facendo clic sul pulsante ' Correre pulsante ':

Questo è tutto sui crawler di elenchi in AWS.
Conclusione
ListCrawler è il componente del servizio AWS Glue che può essere utilizzato per eseguire la scansione delle informazioni dalle origini e tornare al catalogo. I cataloghi di dati e i crawler possono essere utilizzati per raccogliere dati per ottenere informazioni sui dati noti come metadati. L'utente può anche creare un crawler da AWS Glue per ottenere dati dal servizio S3 o da altre fonti e posizionare le tabelle di creazione nel database. Questa guida ha spiegato i ListCrawler in AWS e come crearli.