Ospitare e gestire i dati in database e data warehouse è sempre stato un compito frenetico e problematico. Richiede molte risorse e potenza di calcolo per dare un senso ai dati. Amazon Web Services dispone di una soluzione unica per questo scopo. Ha un servizio chiamato Amazon Redshift che gestisce completamente i data warehouse degli utenti.
Questo articolo spiegherà in dettaglio Amazon Redshift insieme alla sua architettura di data warehouse. Tutti i componenti dell'architettura del sistema di data warehouse di Redshift verranno spiegati in dettaglio.
Cos'è Amazon Redshift?
IT è un servizio di data warehousing fornito da Amazon. Gestisce e analizza in modo efficiente set di dati di grandi dimensioni per analisi e reporting. È costruito su un modello di archiviazione a colonne. Utilizza cluster di nodi di calcolo controllati da un nodo leader per fornire un'elaborazione dei dati ad alte prestazioni.
Prende dati da diverse fonti e li raggruppa per creare un data warehouse. Offre diverse funzionalità, come la condivisione dei dati e l'analisi in tempo reale. Visualizza l'immagine seguente per comprendere le caratteristiche e le capacità di Amazon Redshift:
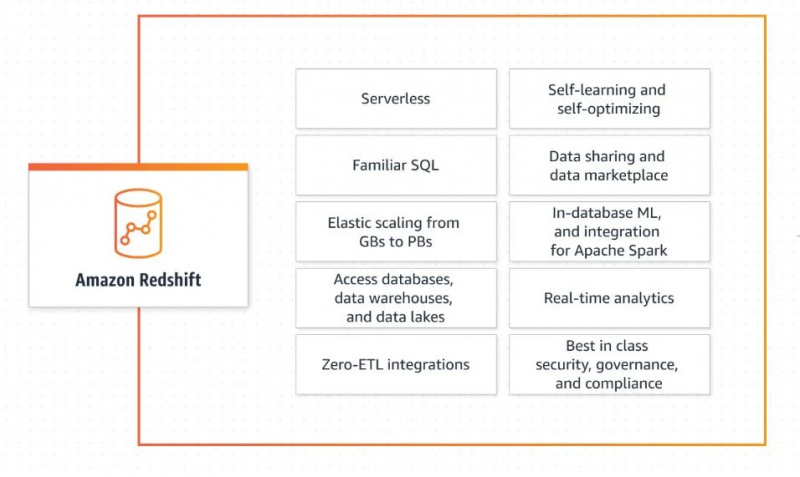
Passiamo ora all'architettura del sistema di data warehouse.
Cos'è l'architettura del sistema di data warehouse di Amazon Redshift?
Questa architettura di sistema ha tre parti principali. Queste parti sono:
- Magazzinaggio
- Accelerazione
- Calcolo
Cerchiamo di comprendere le loro finalità:
Magazzinaggio
La parte di archiviazione riguarda i servizi di archiviazione offerti da Redshift. Dispone di una propria opzione di servizio di archiviazione gestito e di un'opzione di bucket S3.
Accelerazione
La parte di accelerazione dipende dal servizio di stoccaggio in uso e dalla potenza computazionale impiegata. Lo storage gestito da Redshift è più veloce rispetto ad altre opzioni di storage
Calcolo
La parte computazionale riguarda esclusivamente la potenza di calcolo in uso. Il calcolo viene eseguito con cluster e i cluster hanno nodi. I nodi a loro volta hanno delle fette.
Per comprendere meglio tutti gli elementi e i componenti di questa architettura guardate l’immagine qui sotto:
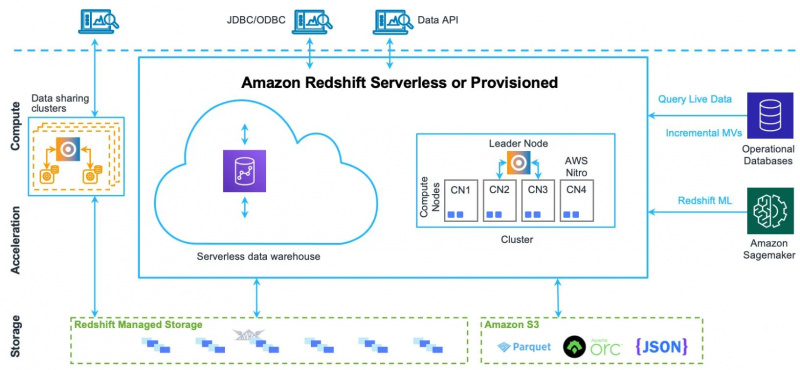
Cerchiamo di comprendere le sue componenti una per una.
Quali sono i componenti architettonici di Amazon Redshift?
Di seguito sono riportati i componenti architetturali di Amazon Redshift:
- Cluster
- Nodi
- Fette di nodo
- Magazzinaggio
- Rete interna
- Banche dati
Discutiamone uno per uno:
Cluster
Un cluster è l’unità fondamentale e centrale. Comprende una serie di nodi. Se un cluster è costituito da più nodi di calcolo, un ulteriore nodo leader interviene per coordinare le attività di questi nodi di calcolo e gestire la comunicazione esterna.
Nodi
I nodi nei cluster sono di due tipi. Questi sono:
- Nodo leader
- Nodo di calcolo
Cerchiamo di capirli uno per uno:
Nodo leader
Gestisce la comunicazione con i programmi client e coordina le interazioni con i nodi di calcolo. Il nodo leader svolge un ruolo fondamentale nell'esecuzione di query complesse. Compila il codice in base al piano di esecuzione che viene distribuito ai nodi di calcolo e assegna porzioni di dati a ciascun singolo nodo di calcolo.
Nodo di calcolo
I nodi di calcolo sono la spina dorsale dell'architettura di Amazon Redshift. Effettuano sia la memorizzazione che l'elaborazione dei dati. Questi hanno risorse dedicate, come memoria e CPU.
Fette di nodo
I nodi di calcolo sono ulteriormente divisi in sezioni. Queste sezioni lavorano insieme per elaborare i carichi di lavoro assegnati e ottenere il parallelismo per migliorare l'elaborazione delle query.
Magazzinaggio
L'archiviazione dei dati all'interno di Amazon Redshift è gestita da 'Redshift Managed Storage (RMS)'. Ha la capacità di ridimensionare lo spazio di archiviazione in modo indipendente utilizzando lo spazio di archiviazione 'Amazon S3'. RMS utilizza storage locale basato su SSD ad alte prestazioni come cache di livello 1 che ottimizza le prestazioni.
Rete interna
Questa rete interna in Amazon Redshift agevola la comunicazione rapida e sicura tra i nodi leader e i nodi di elaborazione. Questa rete non è direttamente accessibile alle applicazioni client.
Banche dati
I cluster hanno uno o più database. I dati di questi database si trovano sui nodi di calcolo. Le applicazioni client comunicano con il nodo leader. Il nodo di calcolo gestisce l'esecuzione delle query tra i nodi di calcolo.
Tutto riguarda Amazon Redshift e i suoi elementi architettonici. Questo articolo ha spiegato in modo esauriente i componenti di funzionamento di Amazon Redshift
Conclusione
L'architettura di Amazon Redshift è la ragione su cui poggiano le sue capacità. Il nodo leader controlla e gestisce i nodi di calcolo e le sezioni dei nodi aiutano nell'elaborazione parallela. Redshift Managed Storage utilizza l'archiviazione basata su SSD per migliorare le prestazioni. Questo articolo ha spiegato l'architettura del sistema di data warehouse di Amazon Redshift.