Questa guida illustrerà come utilizzare VectorStoreRetrieverMemory utilizzando il framework LangChain.
Come utilizzare VectorStoreRetrieverMemory in LangChain?
VectorStoreRetrieverMemory è la libreria di LangChain che può essere utilizzata per estrarre informazioni/dati dalla memoria utilizzando gli archivi vettoriali. Gli archivi vettoriali possono essere utilizzati per archiviare e gestire i dati per estrarre in modo efficiente le informazioni in base al prompt o alla query.
Per apprendere il processo di utilizzo di VectorStoreRetrieverMemory in LangChain, segui semplicemente la seguente guida:
Passaggio 1: installare i moduli
Avvia il processo di utilizzo del memory retriever installando LangChain utilizzando il comando pip:
pip installa langchain
Installa i moduli FAISS per ottenere i dati utilizzando la ricerca per somiglianza semantica:
pip installa faiss-gpu 
Installa il modulo chromadb per utilizzare il database Chroma. Funziona come archivio vettoriale per costruire la memoria per il retriever:
pip installa chromadb 
È necessario installare un altro modulo tiktoken che può essere utilizzato per creare token convertendo i dati in blocchi più piccoli:
pip installa tiktoken 
Installa il modulo OpenAI per utilizzare le sue librerie per creare LLM o chatbot utilizzando il suo ambiente:
pip installa openai 
Configura l'ambiente sull'IDE Python o sul notebook utilizzando la chiave API dall'account OpenAI:
importare Voiimportare getpass
Voi . circa [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'Chiave API OpenAI:' )
Passaggio 2: importare librerie
Il passaggio successivo è ottenere le librerie da questi moduli per utilizzare il memory retriever in LangChain:
da langchain. richiede importare Modello Promptda appuntamento importare appuntamento
da langchain. llms importare OpenAI
da langchain. incastri . openai importare OpenAIEmbeddings
da langchain. Catene importare Catena di conversazioni
da langchain. memoria importare VectorStoreRetrieverMemory
Passaggio 3: inizializzazione dell'archivio vettori
Questa guida utilizza il database Chroma dopo aver importato la libreria FAISS per estrarre i dati utilizzando il comando di input:
importare faissda langchain. archivio documenti importare InMemoryDocstore
#importazione di librerie per la configurazione di database o archivi di vettori
da langchain. vectorstores importare FAISS
#crea incorporamenti e testi per memorizzarli negli archivi vettoriali
incorporamento_dimensione = 1536
indice = faiss. IndicePiattoL2 ( incorporamento_dimensione )
incorporamento_fn = OpenAIEmbeddings ( ) . incorpora_query
vectorstore = FAISS ( incorporamento_fn , indice , InMemoryDocstore ( { } ) , { } )
Passaggio 4: creazione di Retriever supportato da un archivio di vettori
Costruisci la memoria per archiviare i messaggi più recenti nella conversazione e ottenere il contesto della chat:
documentalista = vectorstore. as_retriever ( search_kwargs = dict ( K = 1 ) )memoria = VectorStoreRetrieverMemory ( documentalista = documentalista )
memoria. salva_contesto ( { 'ingresso' : 'Mi piace mangiare la pizza' } , { 'produzione' : 'fantastico' } )
memoria. salva_contesto ( { 'ingresso' : 'Sono bravo a calcio' } , { 'produzione' : 'OK' } )
memoria. salva_contesto ( { 'ingresso' : 'Non mi piace la politica' } , { 'produzione' : 'Sicuro' } )
Testare la memoria del modello utilizzando l'input fornito dall'utente con la sua cronologia:
stampa ( memoria. carica_variabili_memoria ( { 'richiesta' : 'che sport dovrei guardare?' } ) [ 'storia' ] ) 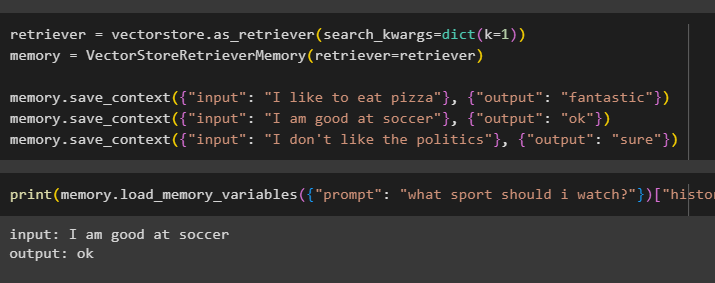
Passaggio 5: utilizzo di Retriever in una catena
Il passaggio successivo è l'utilizzo di un memory retriever con le catene costruendo il LLM utilizzando il metodo OpenAI() e configurando il modello di prompt:
llm = OpenAI ( temperatura = 0 )_MODELLO PREDEFINITO = '''Si tratta di un'interazione tra un essere umano e una macchina
Il sistema produce informazioni utili con dettagli utilizzando il contesto
Se il sistema non ha la risposta per te, dice semplicemente che non ho la risposta
Informazioni importanti dalla conversazione:
{storia}
(se il testo non è rilevante non usarlo)
Chat attuale:
Umano: {input}
AI:'''
RICHIESTA = Modello Prompt (
input_variabili = [ 'storia' , 'ingresso' ] , modello = _MODELLO PREDEFINITO
)
#configura ConversationChain() utilizzando i valori per i suoi parametri
conversazione_con_riepilogo = Catena di conversazioni (
llm = llm ,
richiesta = RICHIESTA ,
memoria = memoria ,
prolisso = VERO
)
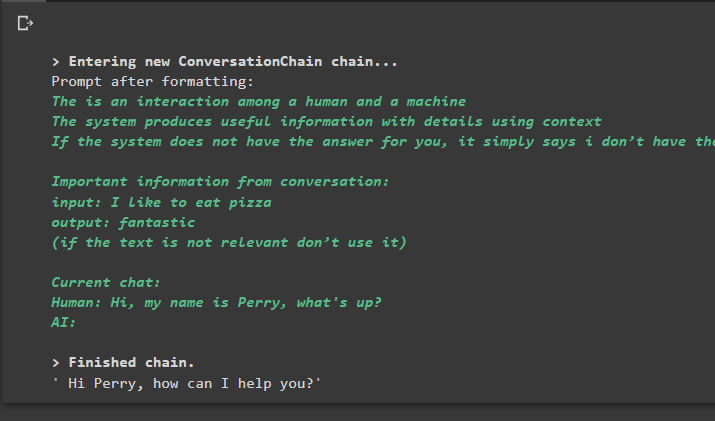
conversazione_con_riepilogo. prevedere ( ingresso = 'Ciao, mi chiamo Perry, che succede?' )
Produzione
L'esecuzione del comando esegue la catena e visualizza la risposta fornita dal modello o LLM:
Procedi con la conversazione utilizzando il prompt basato sui dati memorizzati nell'archivio vettoriale:
conversazione_con_riepilogo. prevedere ( ingresso = 'qual è il mio sport preferito?' ) 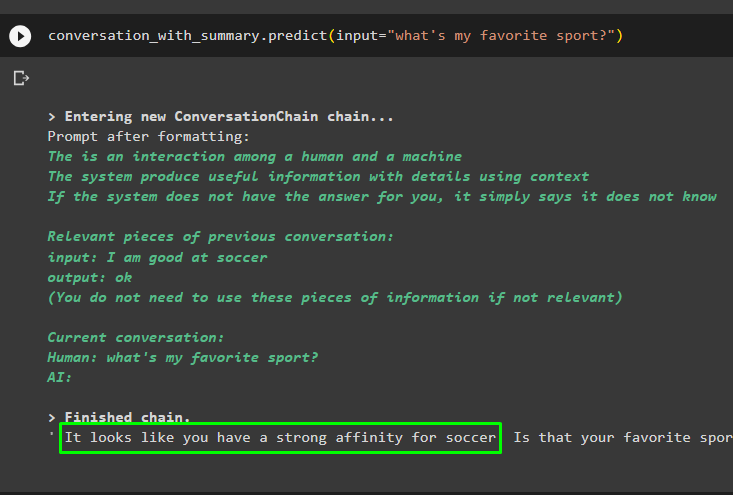
I messaggi precedenti vengono archiviati nella memoria del modello che può essere utilizzata dal modello per comprendere il contesto del messaggio:
conversazione_con_riepilogo. prevedere ( ingresso = 'Qual è il mio cibo preferito' ) 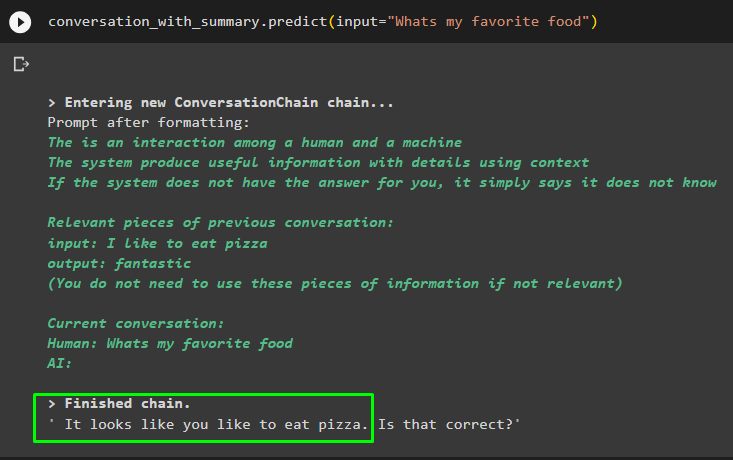
Ottieni la risposta fornita al modello in uno dei messaggi precedenti per verificare come funziona il memory retriever con il modello di chat:
conversazione_con_riepilogo. prevedere ( ingresso = 'Qual è il mio nome?' )Il modello ha visualizzato correttamente l'output utilizzando la ricerca per similarità dai dati archiviati in memoria:
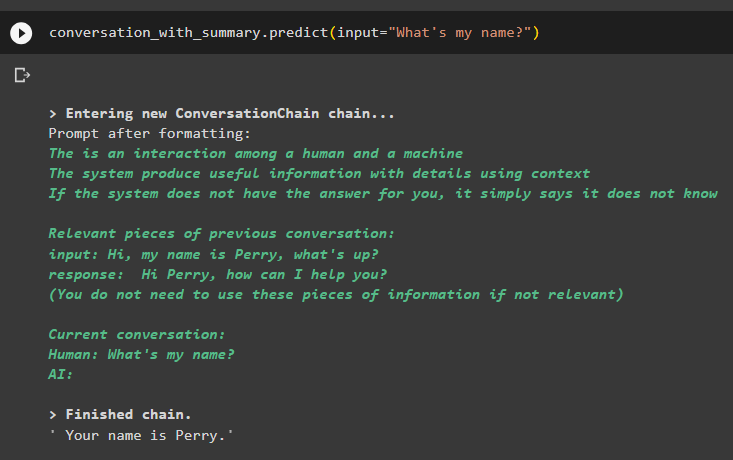
Si tratta di utilizzare il vector store retriever in LangChain.
Conclusione
Per utilizzare il memory retriever basato su un archivio vettoriale in LangChain, è sufficiente installare i moduli e i framework e configurare l'ambiente. Successivamente, importa le librerie dai moduli per creare il database utilizzando Chroma e quindi imposta il modello di prompt. Metti alla prova il retriever dopo aver archiviato i dati in memoria avviando la conversazione e ponendo domande relative ai messaggi precedenti. Questa guida ha approfondito il processo di utilizzo della libreria VectorStoreRetrieverMemory in LangChain.