Contorno rapido
Questo post contiene le seguenti sezioni:
- Come utilizzare un agente API asincrono in LangChain
- Metodo 1: utilizzo dell'esecuzione seriale
- Metodo 2: utilizzo dell'esecuzione simultanea
- Conclusione
Come utilizzare un agente API asincrono in LangChain?
I modelli di chat eseguono più attività contemporaneamente come comprendere la struttura del prompt, le sue complessità, estrarre informazioni e molto altro. L'utilizzo dell'agente API Async in LangChain consente all'utente di creare modelli di chat efficienti in grado di rispondere a più domande contemporaneamente. Per apprendere il processo di utilizzo dell'agente API Async in LangChain, segui semplicemente questa guida:
Passaggio 1: installazione dei framework
Prima di tutto, installa il framework LangChain per ottenere le sue dipendenze dal gestore pacchetti Python:
pip installa langchain
Successivamente, installa il modulo OpenAI per creare il modello linguistico come llm e imposta il suo ambiente:
pip installa openai
Passaggio 2: ambiente OpenAI
Il passaggio successivo dopo l'installazione dei moduli è impostazione dell'ambiente utilizzando la chiave API di OpenAI e API del server per cercare dati da Google:
importare Voi
importare getpass
Voi . circa [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'Chiave API OpenAI:' )
Voi . circa [ 'SERPER_API_KEY' ] = getpass . getpass ( 'Chiave API del server:' )
Passaggio 3: importazione delle librerie
Ora che l'ambiente è impostato, importa semplicemente le librerie richieste come asyncio e altre librerie utilizzando le dipendenze LangChain:
da langchain. agenti importare inizializza_agente , carica_strumentiimportare tempo
importare asincio
da langchain. agenti importare Tipo agente
da langchain. llms importare OpenAI
da langchain. richiamate . stdout importare StdOutCallbackHandler
da langchain. richiamate . traccianti importare LangChainTracer
da aiothttp importare Sessione cliente
Passaggio 4: domande di configurazione
Imposta un set di dati di domande contenente più query relative a diversi domini o argomenti che possono essere cercati su Internet (Google):
domande = ['Chi è il vincitore del campionato US Open nel 2021' ,
'Quali anni ha il fidanzato di Olivia Wilde' ,
'Chi è il vincitore del titolo mondiale di formula 1' ,
'Chi ha vinto la finale femminile degli US Open nel 2021' ,
'Chi è il marito di Beyoncé e qual è la sua età' ,
]
Metodo 1: utilizzo dell'esecuzione seriale
Una volta completati tutti i passaggi, è sufficiente eseguire le domande per ottenere tutte le risposte utilizzando l'esecuzione seriale. Ciò significa che verrà eseguita/visualizzata una domanda alla volta e verrà restituito anche il tempo completo necessario per eseguire queste domande:
llm = OpenAI ( temperatura = 0 )utensili = carica_strumenti ( [ 'intestazione Google' , 'llm-matematica' ] , llm = llm )
agente = inizializza_agente (
utensili , llm , agente = Tipo agente. ZERO_SHOT_REACT_DESCRIPTION , prolisso = VERO
)
S = tempo . perf_counter ( )
#configurazione del contatore del tempo per ottenere il tempo utilizzato per il processo completo
per Q In domande:
agente. correre ( Q )
trascorso = tempo . perf_counter ( ) - S
#stampa il tempo totale impiegato dall'agente per ottenere le risposte
stampa ( F 'Seriale eseguito in {elapsed:0.2f} secondi.' )
Produzione
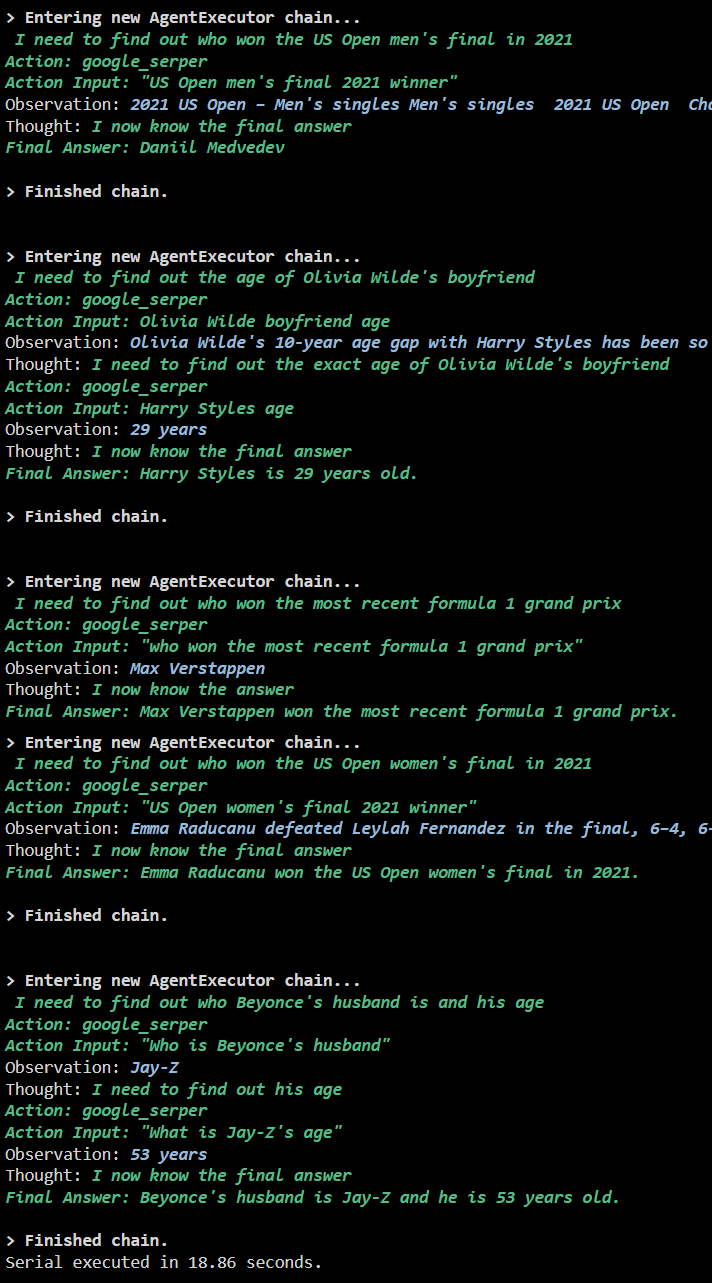
La schermata seguente mostra che a ciascuna domanda viene data risposta in una catena separata e una volta terminata la prima catena, diventa attiva la seconda catena. L'esecuzione seriale richiede più tempo per ottenere tutte le risposte individualmente:
Metodo 2: utilizzo dell'esecuzione simultanea
Il metodo di esecuzione simultanea accetta tutte le domande e ottiene le risposte simultaneamente.
llm = OpenAI ( temperatura = 0 )utensili = carica_strumenti ( [ 'intestazione Google' , 'llm-matematica' ] , llm = llm )
#Configurazione dell'agente utilizzando gli strumenti di cui sopra per ottenere risposte contemporaneamente
agente = inizializza_agente (
utensili , llm , agente = Tipo agente. ZERO_SHOT_REACT_DESCRIPTION , prolisso = VERO
)
#configurazione del contatore del tempo per ottenere il tempo utilizzato per il processo completo
S = tempo . perf_counter ( )
compiti = [ agente. malattia ( Q ) per Q In domande ]
attendere l'asincio. raccogliere ( *compiti )
trascorso = tempo . perf_counter ( ) - S
#stampa il tempo totale impiegato dall'agente per ottenere le risposte
stampa ( F 'Eseguito contemporaneamente in {elapsed:0.2f} secondi' )
Produzione
L'esecuzione simultanea estrae tutti i dati contemporaneamente e richiede molto meno tempo rispetto all'esecuzione seriale:
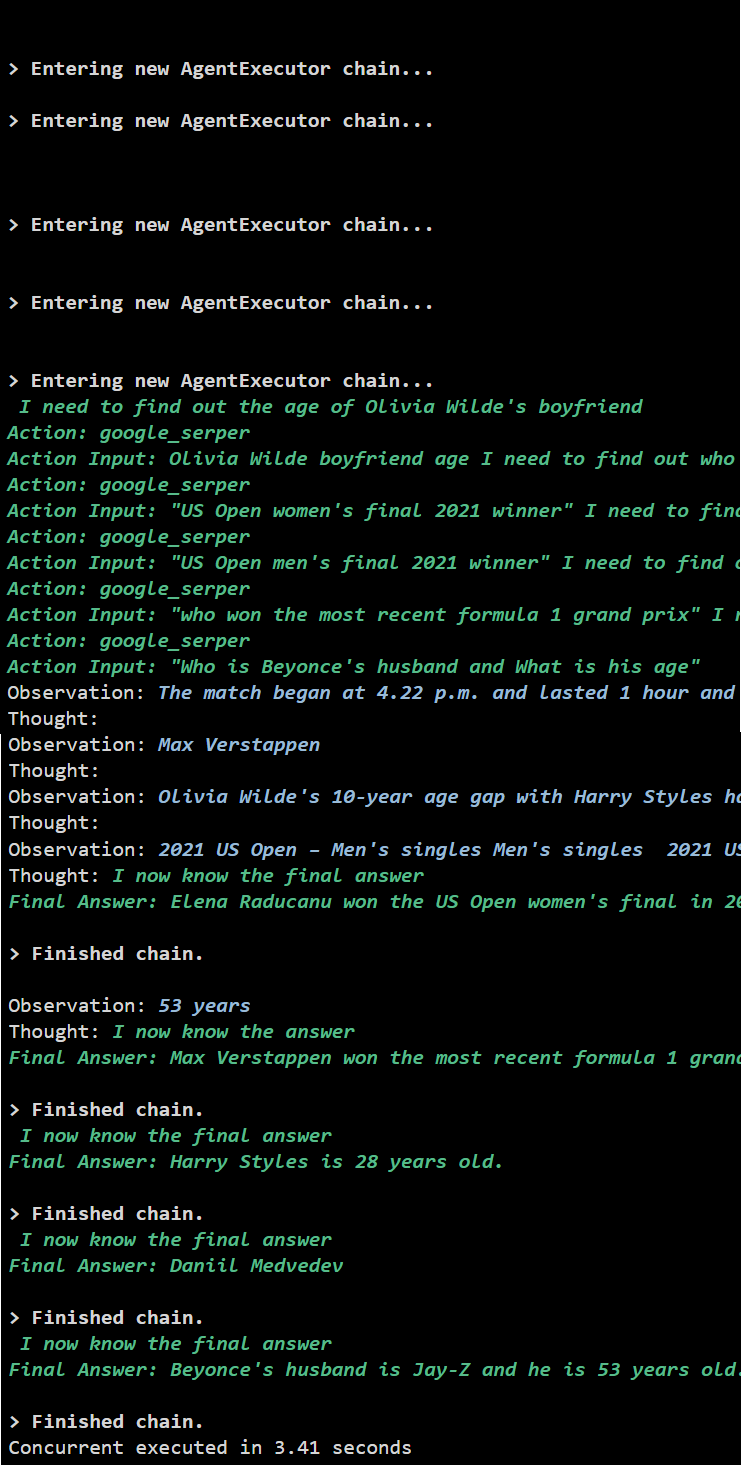
Si tratta di utilizzare l'agente API Async in LangChain.
Conclusione
Per utilizzare l'agente API Async in LangChain, è sufficiente installare i moduli per importare le librerie dalle loro dipendenze per ottenere la libreria asyncio. Successivamente, configura gli ambienti utilizzando le chiavi API OpenAI e Serper accedendo ai rispettivi account. Configura l'insieme di domande relative a diversi argomenti ed esegui le catene in serie e contemporaneamente per ottenere il loro tempo di esecuzione. Questa guida ha approfondito il processo di utilizzo dell'agente API Async in LangChain.