Questa guida spiegherà come creare crawler per recuperare i dati dal bucket S3.
Come creare un crawler per recuperare i dati dal bucket S3?
Per creare un crawler in AWS, visita il ' Colla AWS ' servizio dalla dashboard di Amazon:
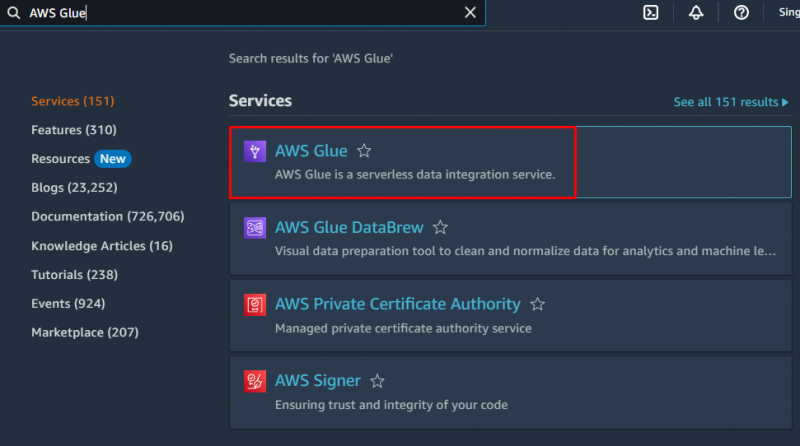
Clicca sul ' Banche dati ” dalla sezione Catalogo dati per creare un database:
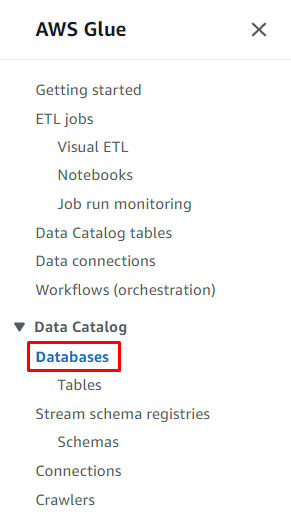
Clicca sul ' Aggiungi banca dati ” pulsante per avviare la configurazione:
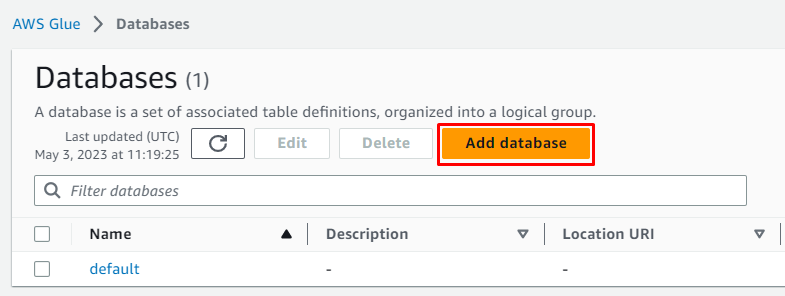
Inserisci il nome del database e lascia tutto come facoltativo prima di cliccare sul pulsante “ Crea banca dati pulsante ':
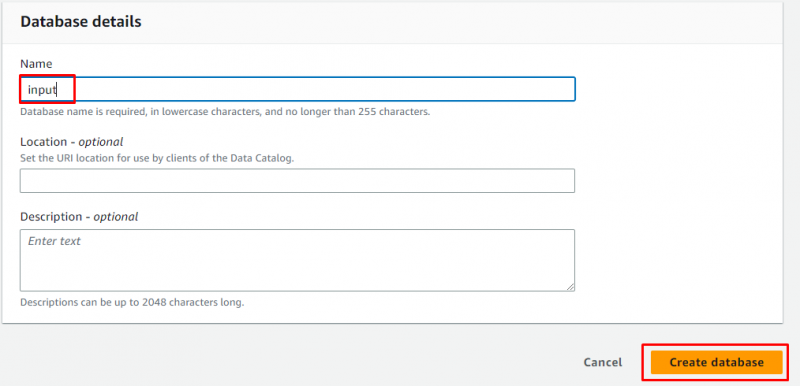
Il database è stato creato con successo:
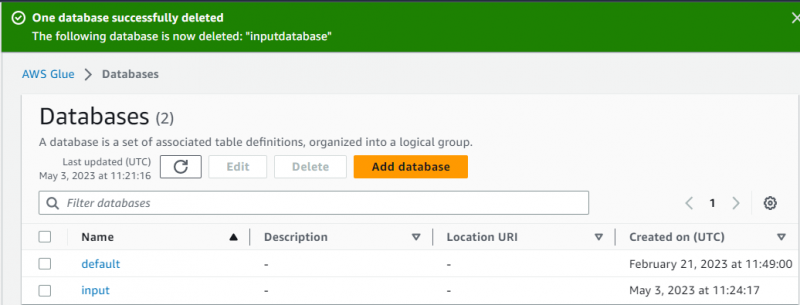
Dopodiché, vai semplicemente al ' Crawler ” facendo clic su di essa dal pannello di sinistra:
Clicca sul ' Crea crawler pulsante ':

Digita il nome del crawler e fai clic su ' Prossimo pulsante ':

Clicca sul ' Aggiungi un'origine dati ” pulsante per selezionare la fonte dei dati:
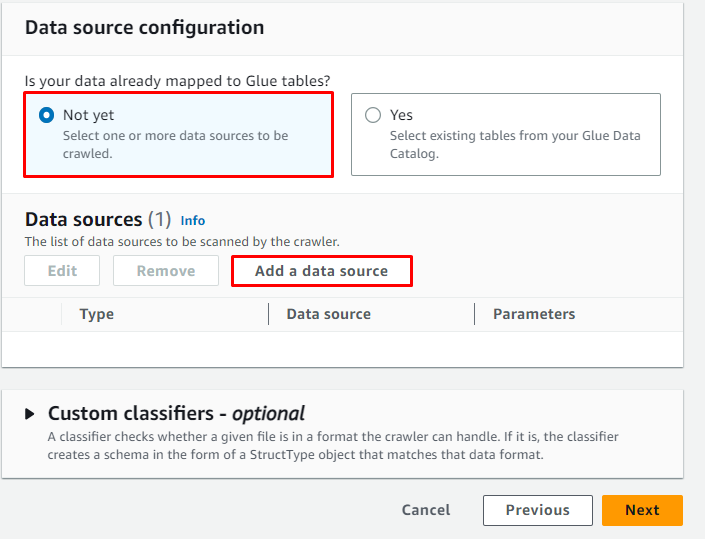
Per verificare il percorso in cui sono archiviati i dati, visitare il servizio S3:
Accedi al bucket S3 in cui vengono caricati i dati. L'utente può creare un secchio e caricamento dati su di esso dal dashboard AWS S3:

Clicca sul ' Sfoglia S3 ” pulsante per scegliere il percorso dei dati:
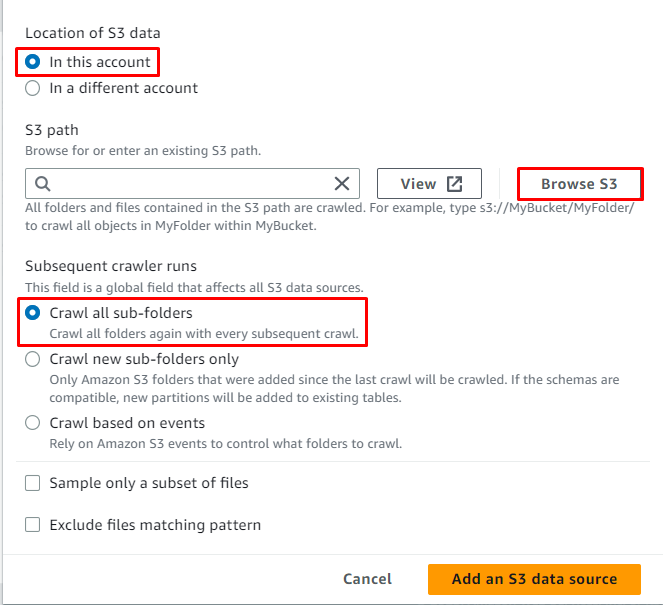
Selezionare la cartella contenente i dati, quindi fare clic su ' Scegliere pulsante ':

Il percorso S3 è stato selezionato, ora fai clic sul pulsante ' Aggiungi un'origine dati S3 pulsante ':

Una volta aggiunta l'origine dati, è sufficiente fare clic sul pulsante ' Prossimo pulsante ':
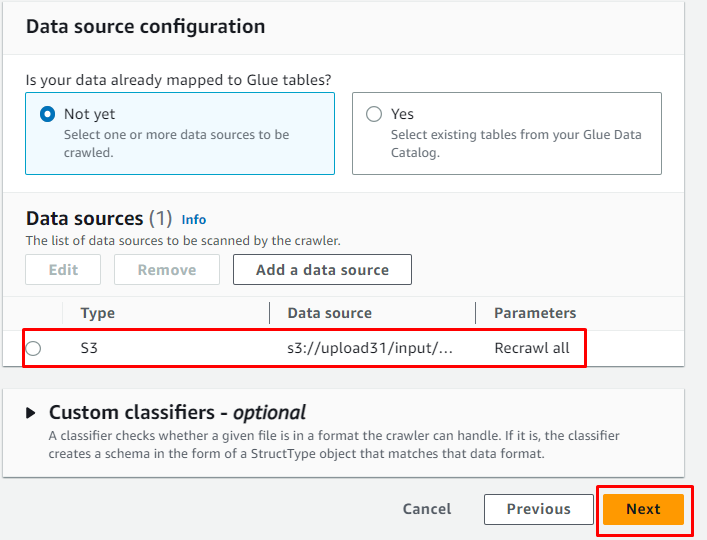
Aggiungere il ruolo IAM e quindi fare clic su ' Prossimo pulsante ':
Immettere il database di destinazione creato in precedenza, quindi digitare il nome della tabella:
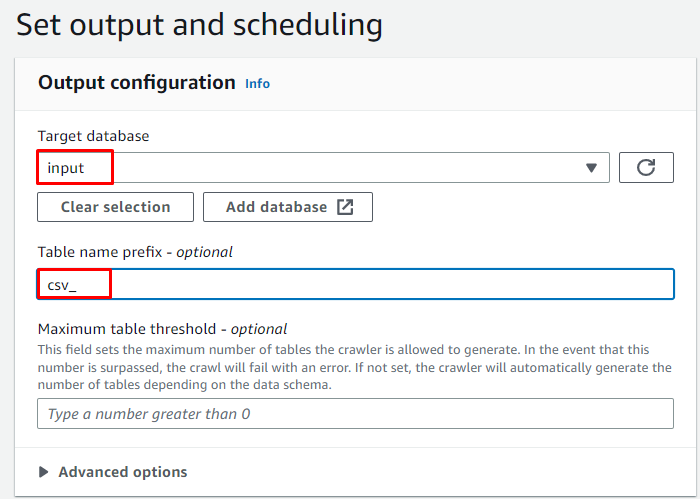
Selezionare la pianificazione On demand per il crawler e fare clic sul pulsante ' Prossimo pulsante ':
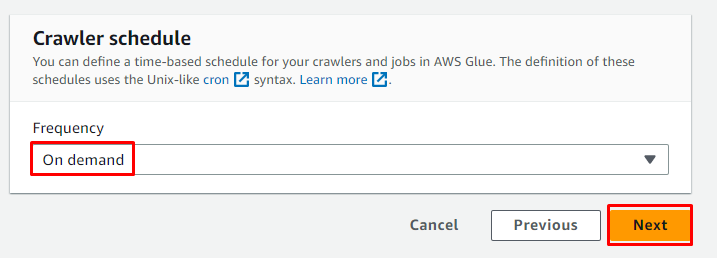
Esamina il crawler e fai clic su ' Crea crawler pulsante ':
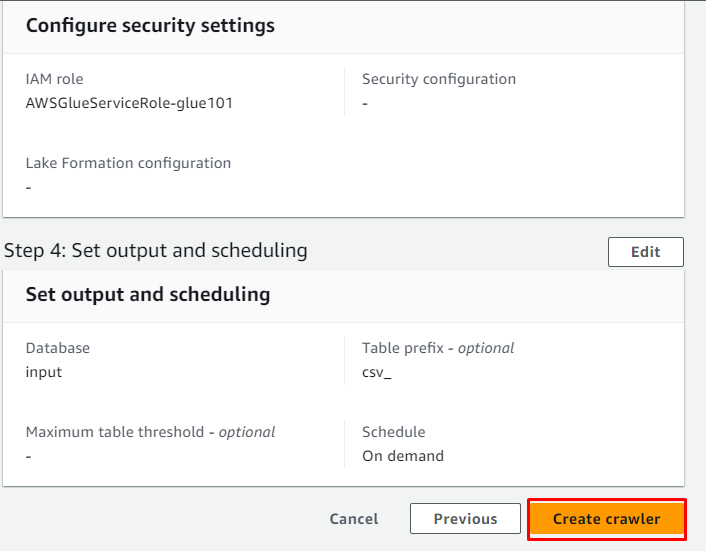
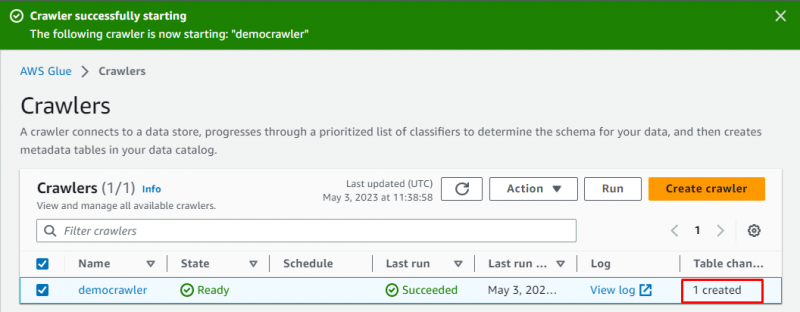
Il crawler è stato creato con successo, fai clic sul pulsante ' Correre ” dopo averlo selezionato:

Ci vorranno alcuni istanti per eseguire il crawler e recupererà i dati e creerà una tabella per archiviare i dati:
Entra nel “ Tabelle ” dalla dashboard di Glue:
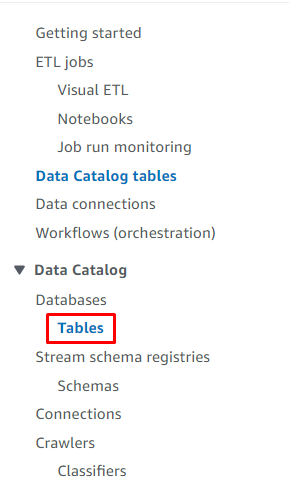
Seleziona la tabella cliccando sul suo nome:
Sono stati visualizzati i dettagli del conto contenenti i metadati dei dati recuperati:
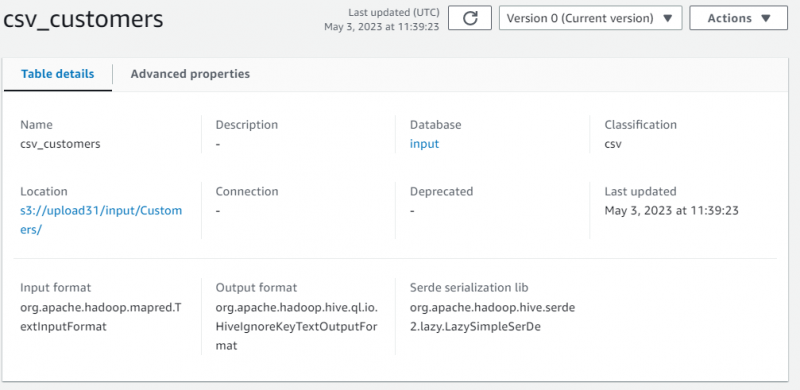
Scorri la pagina e seleziona la sezione per visualizzare la tabella contenente i dati:
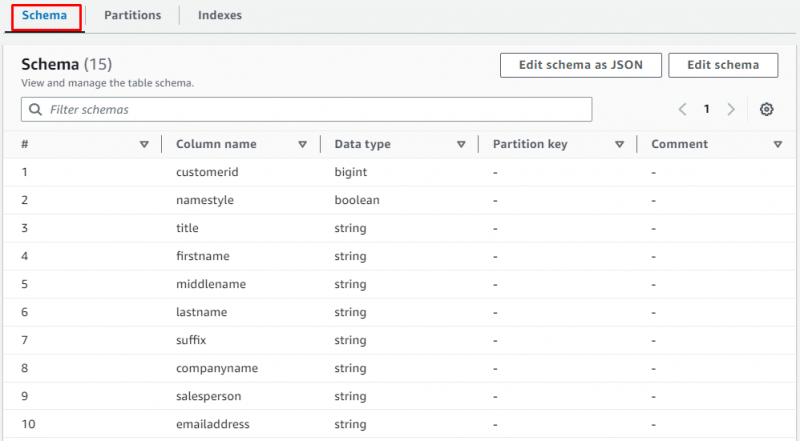
Si tratta di creare un crawler per recuperare i dati dal bucket S3.
Conclusione
Per creare un crawler per recuperare i dati dal bucket S3, crea un database su AWS Glue in cui verranno archiviati i dati scansionati. Configura il crawler dalla dashboard di Glue fornendo l'origine dei dati (bucket S3) e il database di destinazione. Esegui il crawler e recupera i dati dal bucket S3 alla tabella del database come spiegato in dettaglio in questa guida.