L'elemento più cruciale della struttura dei dati è la coda. La coda della struttura dei dati 'first in, first out' che è la base per il multiprocessing Python è paragonabile. Le code vengono fornite alla funzione del processo per consentire al processo di raccogliere i dati. Il primo elemento di dati da eliminare dalla coda è il primo elemento da inserire. Utilizziamo il metodo 'put()' della coda per aggiungere i dati alla coda e il relativo metodo 'get()' per recuperare i dati dalla coda.
Esempio 1: utilizzo del metodo Queue() per creare una coda di multielaborazione in Python
In questo esempio, creiamo una coda multiprocessing in Python usando il metodo 'queue()'. Il multiprocessing si riferisce all'utilizzo di una o più CPU in un sistema per eseguire due o più processi contemporaneamente. Il multiprocessing, un modulo costruito in Python, facilita il passaggio da un processo all'altro. Dobbiamo avere familiarità con la proprietà process prima di lavorare con il multiprocessing. Siamo consapevoli che la coda è una componente cruciale del modello di dati. La coda dati standard, che si basa sull'idea 'First-In-First-Out', e il multiprocessing Python sono le controparti esatte. In generale, la coda memorizza l'oggetto Python ed è fondamentale per il trasferimento dei dati tra le attività.
Lo strumento 'spyder' viene utilizzato per implementare lo script Python presente, quindi iniziamo semplicemente. Dobbiamo prima importare il modulo multiprocessing perché stiamo eseguendo lo script Python multiprocessing. Lo abbiamo fatto importando il modulo multiprocessing come 'm'. Usando la tecnica “m.queue()”, invochiamo il metodo multiprocessing “queue()”. Qui, creiamo una variabile chiamata 'queue' e inseriamo in essa il metodo multiprocessing 'queue()'. Poiché sappiamo che la coda memorizza gli elementi in un ordine 'first-in, first-out', l'elemento che aggiungiamo per primo viene rimosso per primo. Dopo aver avviato la coda multiprocessing, chiamiamo quindi il metodo 'print()', passando l'istruzione 'There is a multiprocessing queue' come argomento per visualizzarla sullo schermo. Quindi, poiché memorizziamo la coda costruita in questa variabile, stampiamo la coda passando la variabile 'queue' tra le parentesi del metodo 'print()'.
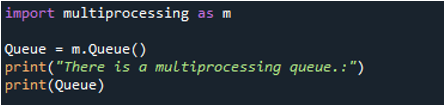
L'immagine seguente mostra che la coda di multielaborazione Python è ora costruita. L'estratto conto stampato viene mostrato per primo. Dopo che questa coda di multielaborazione è stata creata nell'indirizzo di memoria designato, può essere utilizzata per trasferire i dati distinti tra due o più processi in esecuzione.

Esempio 2: utilizzo del metodo 'Qsize()' per determinare la dimensione della coda di multielaborazione in Python
In questo caso, determiniamo la dimensione della coda di multielaborazione. Per calcolare la dimensione della coda multiprocessing, utilizziamo il metodo 'qsize()'. La funzione 'qsize()' restituisce la dimensione reale della coda multiprocessing di Python. In altre parole, questo metodo fornisce il numero totale di elementi in una coda.
Iniziamo importando il modulo multiprocessing Python come 'm' prima di eseguire il codice. Quindi, utilizzando il comando 'm.queue()', invochiamo la funzione multiprocessing 'queue()' e inseriamo il risultato nella variabile 'Queue'. Quindi, utilizzando il metodo 'put ()', aggiungiamo gli elementi alla coda nella riga seguente. Questo metodo viene utilizzato per aggiungere i dati a una coda. Pertanto, chiamiamo 'Queue' con il metodo 'put ()' e forniamo i numeri interi come elemento tra parentesi. I numeri che aggiungiamo sono '1', '2', '3', '4', '5', '6' e '7' usando le funzioni 'put()'.
Inoltre, utilizzando 'Queue' per ottenere la dimensione della coda multiprocessing, chiamiamo 'qsize()' con la coda multiprocessing. Quindi, nella nuova variabile 'result', salviamo il risultato del metodo 'qsize()'. Successivamente, chiamiamo il metodo 'print ()' e passiamo l'istruzione 'La dimensione della coda multiprocessing è' come parametro. Successivamente, chiamiamo la variabile 'result' nella funzione 'print()' poiché la dimensione viene salvata in questa variabile.
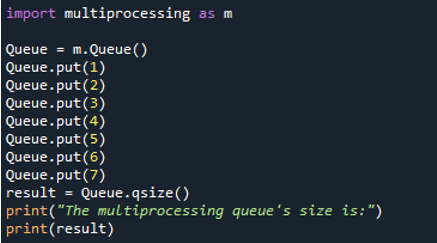
L'immagine di output ha le dimensioni visualizzate. Poiché utilizziamo la funzione 'put()' per aggiungere sette elementi alla coda multiprocessing e la funzione 'qsize()' per determinare la dimensione, viene visualizzata la dimensione '7' della coda multiprocessing. L'istruzione di input 'la dimensione della coda multielaborazione' viene mostrata prima della dimensione.

Esempio 3: utilizzo dei metodi 'Put()' e 'Get()' nella coda di elaborazione multipla di Python
In questo esempio vengono utilizzati i metodi della coda 'put()' e 'get()' della coda multiprocessing di Python. Sviluppiamo due funzioni definite dall'utente in questo esempio. In questo esempio, definiamo una funzione per creare un processo che produce '5' numeri interi casuali. Usiamo anche il metodo 'put ()' per aggiungerli a una coda. Il metodo 'put()' viene utilizzato per posizionare gli elementi nella coda. Quindi, per recuperare i numeri dalla coda e restituire i loro valori, scriviamo un'altra funzione e la chiamiamo durante la procedura. Usiamo la funzione “get()” per recuperare i numeri dalla coda poiché questo metodo serve per recuperare i dati dalla coda che inseriamo usando il metodo “put()”.
Iniziamo a implementare il codice ora. Per prima cosa, importiamo le quattro librerie che compongono questo script. Per prima cosa importiamo 'sleep' dal modulo time per ritardare l'esecuzione per un certo tempo misurato in secondi, seguito da 'random' dal modulo random che viene utilizzato per generare numeri casuali, quindi 'process' da multiprocessing perché questo codice crea un processo e, infine, la 'coda' dal multiprocessing. Costruendo inizialmente un'istanza di classe, è possibile utilizzare la coda. Per impostazione predefinita, questo stabilisce una coda infinita o una coda senza dimensione massima. Impostando l'opzione dimensione massima su un numero maggiore di zero, è possibile realizzare una creazione con un limite di dimensione.
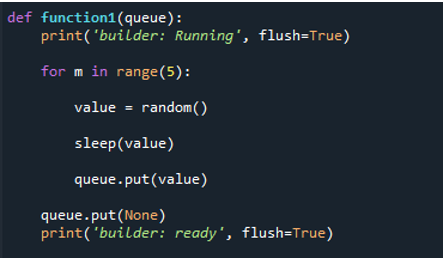
Definiamo una funzione. Quindi, poiché questa funzione è definita dall'utente, le diamo il nome 'funzione1' e passiamo il termine 'coda' come argomento. Successivamente, invochiamo la funzione 'print()', passandole le istruzioni 'builder: Running', 'flush' e l'oggetto 'True'. La funzione di stampa di Python ha un'opzione unica chiamata flush che consente all'utente di scegliere se bufferizzare o meno questo output. Il passaggio successivo consiste nel generare l'attività. Per fare ciò, usiamo 'for' e creiamo la variabile 'm' e impostiamo l'intervallo su '5'. Quindi, nella riga successiva, usa 'random()' e memorizza il risultato nella variabile che abbiamo creato, che è 'value'. Ciò indica che la funzione ora termina le sue cinque iterazioni, con ogni iterazione che crea un numero intero casuale compreso tra 0 e 5.
Quindi, nel passaggio successivo, chiamiamo la funzione 'sleep()' e passiamo l'argomento 'value' per ritardare la porzione per un certo numero di secondi. Quindi, chiamiamo la 'coda' con il metodo 'put()' per aggiungere essenzialmente il valore alla coda. L'utente viene quindi informato che non c'è più lavoro da fare invocando ancora una volta il metodo 'queue.put()' e passando il valore 'None'. Quindi, eseguiamo il metodo 'print ()', passiamo l'istruzione 'builder: ready' insieme a 'flush' e la impostiamo su 'True'.
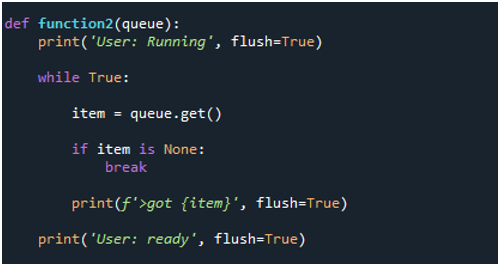
Definiamo ora una seconda funzione, 'funzione2', e le assegniamo la parola chiave 'coda' come suo argomento. Quindi, chiamiamo la funzione 'print()' mentre trasmettiamo gli stati del rapporto 'Utente: in esecuzione' e 'flush' che è impostato su 'True'. Iniziamo l'operazione di 'function2' utilizzando la condizione while true per estrarre i dati dalla coda e inserirli nella variabile 'item' appena creata. Quindi, usiamo la condizione 'if', 'item is None', per interrompere il ciclo se la condizione è vera. Se nessun elemento è disponibile, si ferma e ne chiede uno all'utente. L'attività interrompe il ciclo e termina in questo caso se l'elemento ottenuto dal valore è nullo. Quindi, nel passaggio successivo, chiamiamo la funzione 'print()' e forniamo il rapporto 'Utente: pronto' e i parametri 'flush=True'.
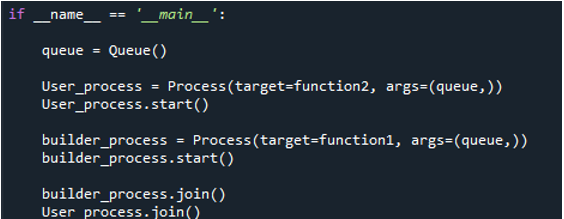
Quindi, entriamo nel processo principale utilizzando 'If-name = main_'. Creiamo una coda chiamando il metodo 'queue()' e memorizzandola nella variabile 'queue'. Successivamente, creiamo un processo chiamando la funzione utente 'funzione2'. Per questo, chiamiamo la classe 'processo'. Al suo interno, passiamo 'target=function2' per chiamare la funzione nel processo, passiamo l'argomento 'queue' e lo memorizziamo nella variabile 'User_process'. Il processo quindi inizia chiamando il metodo 'start()' con la variabile 'User_ process'. Ripetiamo quindi la stessa procedura per chiamare la 'funzione1' nel processo e inserirla nella variabile 'processo builder'. Quindi, chiamiamo i processi con il metodo 'join()' per attendere l'esecuzione.
Ora che è presentato, puoi vedere le istruzioni di entrambe le funzioni nell'output. Visualizza gli elementi che abbiamo aggiunto utilizzando i metodi 'put()' e 'get()' utilizzando rispettivamente i metodi 'get()'.
Conclusione
Abbiamo imparato a conoscere la coda multiprocessing di Python in questo articolo. Abbiamo utilizzato le illustrazioni fornite. Inizialmente, abbiamo descritto come creare una coda nel multiprocessing Python utilizzando la funzione queue(). Quindi, abbiamo utilizzato il metodo 'qsize()' per determinare il valore . Abbiamo anche utilizzato i metodi put() e get() della coda. La classe sleep del modulo time e la classe random del modulo random sono state entrambe discusse nell'ultimo esempio.