5.1 Introduzione
Il sistema operativo per il computer Commodore-64 viene fornito con il computer nella memoria di sola lettura (ROM). Il numero di posizioni di byte di memoria per il Commodore-64 varia da $ 0000 a $ FFFF (cioè da 000016 a FFFF16 che è da 010 a 65,53510). Il sistema operativo va da $E000 a $FFFF (ovvero da 57,34410 a 65,53610).
Perché studiare il sistema operativo Commodore-64
Perché studiare oggi il sistema operativo Commodore-64 quando era il sistema operativo di un computer rilasciato nel 1982? Ebbene, il computer Commodore-64 utilizza la Central Processing Unit 6510 che è un aggiornamento (sebbene non un grande aggiornamento) del 6502 µP.
Il 6502 µP viene prodotto ancora oggi in gran numero; non si tratta più dei computer di casa o dell'ufficio ma di apparecchi (dispositivi) elettrici ed elettronici. Il 6502 µP è anche semplice da comprendere e da utilizzare rispetto agli altri microprocessori dell'epoca. Per questo motivo è uno dei migliori (se non il migliore) microprocessore da utilizzare per insegnare il linguaggio assembly.
Il 65C02 µP, sempre della classe dei microprocessori 6502, dispone di 66 istruzioni in linguaggio assembly, tutte imparabili anche a memoria. I microprocessori moderni hanno molte istruzioni in linguaggio assembly e non possono essere imparati a memoria. Ogni µP ha il proprio linguaggio assembly. Qualsiasi sistema operativo, nuovo o vecchio che sia, utilizza il linguaggio assembly. Detto questo, il linguaggio assembly 6502 è utile per insegnare il sistema operativo ai principianti. Dopo aver appreso un sistema operativo, come quello del Commodore-64, è possibile apprendere facilmente un sistema operativo moderno utilizzando quello come base.
Questa non è solo l'opinione dell'autore (me stesso). È una tendenza in crescita nel mondo. In Internet vengono scritti sempre più articoli per migliorare il sistema operativo Commodore-64 per farlo sembrare un sistema operativo moderno. I moderni sistemi operativi sono spiegati nel capitolo successivo.
Nota : Il sistema operativo Commodore-64 (Kernal) funziona ancora bene con i moderni dispositivi di input e output (non tutti).
Computer a otto bit
In un microcomputer a otto bit come il Commodore 64, le informazioni vengono archiviate, trasferite e manipolate sotto forma di codici binari a otto bit.
Mappa della memoria
Una mappa di memoria è una scala che divide l'intero intervallo di memoria in intervalli più piccoli di diverse dimensioni e mostra cosa (subroutine e/o variabile) appartiene a quale intervallo. Una variabile è un'etichetta che corrisponde a un particolare indirizzo di memoria che ha un valore. Le etichette vengono utilizzate anche per identificare l'inizio delle subroutine. Ma in questo caso sono conosciuti come i nomi delle subroutine. Una subroutine può essere chiamata semplicemente routine.
La mappa della memoria (layout) nel capitolo precedente non è sufficientemente dettagliata. È abbastanza semplice. La mappa della memoria del computer Commodore-64 può essere mostrata con tre livelli di dettaglio. Se mostrato al livello intermedio, il computer Commodore-64 ha diverse mappe di memoria. La mappa di memoria predefinita del computer Commodore-64 a livello intermedio è:

Fig. 5.11 Mappa della memoria del Commodore-64
A quei tempi esisteva un linguaggio informatico popolare chiamato BASIC. Molti utenti di computer avevano bisogno di conoscere alcuni comandi minimi del linguaggio BASIC come caricare un programma dal dischetto (disco) nella memoria, eseguire (eseguire) un programma nella memoria e uscire (chiudere) un programma. Quando il programma BASIC è in esecuzione, l'utente deve inserire i dati riga per riga. Non è come oggi quando un'applicazione (un certo numero di programmi forma un'applicazione) è scritta in un linguaggio di alto livello con Windows e l'utente deve semplicemente inserire i diversi dati in posti specializzati in una finestra. In alcuni casi, utilizziamo il mouse per selezionare i dati preordinati. A quel tempo il BASIC era un linguaggio di alto livello, ma era abbastanza vicino al linguaggio assembly.
Si noti che la maggior parte della memoria è occupata dal BASIC nella mappa di memoria predefinita. Il BASIC ha comandi (istruzioni) che vengono eseguiti da quello che è noto come interprete BASIC. In effetti, l'interprete BASIC è nella ROM dalla posizione $A000 a $BFFF (incluso), che presumibilmente è un'area RAM. 8 Kbyte sono abbastanza grandi per il momento! In realtà è nella ROM in quel punto dell'intera memoria. Ha le stesse dimensioni del sistema operativo da $E000 a $FFFF (incluso). Anche i programmi scritti in BASIC sono compresi nell'intervallo compreso tra $ 0200 e $ BFFF.
La RAM per il programma in linguaggio assembly utente va da $C000 a $CFFF, solo 4 Kbyte su 64 Kbyte. Quindi, perché usiamo o impariamo il linguaggio assembly? I nuovi e vecchi sistemi operativi sono linguaggi assembly. Il sistema operativo del Commodore-64 è in ROM, da $E000 a $FFFF. È scritto nel linguaggio assembly 65C02 µP (6510 µP). Consiste di subroutine. Il programma utente in linguaggio assembly deve chiamare queste subroutine per interagire con le periferiche (dispositivi di input e output). Comprendere il sistema operativo Commodore-64 in linguaggio assembly consente allo studente di comprendere i sistemi operativi rapidamente, in modo molto meno noioso. Ancora una volta, a quei tempi, molti programmi utente per il Commodore-64 erano scritti in BASIC e non in linguaggio assembly. A quei tempi i linguaggi assembly venivano utilizzati più dagli stessi programmatori per scopi tecnici.
Il Kernal, scritto K-e-r-n-a-l, è il sistema operativo del Commodore-64. Viene fornito con il computer Commodore-64 nella ROM e non in un disco (o dischetto). Il Kernal è costituito da subroutine. Per accedere alle periferiche, il programma utente in linguaggio assembly (linguaggio macchina) deve utilizzare queste subroutine. Il Kernal non deve essere confuso con il kernel che si scrive K-e-r-n-e-l dei moderni sistemi operativi, sebbene siano quasi la stessa cosa.
L'area di memoria da $C000 (49,15210) a $CFFF (6324810) di 4 Kbyte10 della memoria è RAM o ROM. Quando è RAM, viene utilizzata per accedere alle periferiche. Quando è ROM, viene utilizzata per stampare i caratteri sullo schermo (monitor). Ciò significa che i caratteri vengono stampati sullo schermo o che si accede alle periferiche utilizzando questa porzione di memoria. C'è un banco di ROM (ROM caratteri) nell'unità di sistema (scheda madre) che viene inserito ed estratto dall'intero spazio di memoria per raggiungere questo obiettivo. L'utente potrebbe non notare il passaggio.
L'area di memoria da $ 0100 (256 10 ) a $ 01FF (511 10 ) è la pila. Viene utilizzato sia dal sistema operativo che dai programmi utente. Il ruolo dello stack è stato spiegato nel capitolo precedente di questo corso di carriera online. L'area della memoria da $ 0000 (0 10 ) a $ 00FF (255 10 ) viene utilizzato dal sistema operativo. Qui vengono assegnati molti puntatori.
Tabella del salto Kernal
Kernal ha routine che vengono chiamate dal programma utente. Con l'uscita delle nuove versioni del sistema operativo, gli indirizzi di queste routine sono cambiati. Ciò significa che i programmi utente non potrebbero più funzionare con le nuove versioni del sistema operativo. Ciò non è avvenuto perché il Commodore-64 prevedeva una tabella di salto. La tabella di salto è un elenco di 39 voci. Ogni voce della tabella ha tre indirizzi (tranne gli ultimi 6 byte) che non sono mai cambiati nemmeno con il cambio di versione del sistema operativo.
Il primo indirizzo di una voce ha un'istruzione JSR. I successivi due indirizzi sono costituiti da un puntatore a due byte. Questo puntatore a due byte è l'indirizzo (o il nuovo indirizzo) di una routine effettiva che si trova ancora nella ROM del sistema operativo. Il contenuto del puntatore potrebbe cambiare con le nuove versioni del sistema operativo, ma i tre indirizzi per ciascuna voce della tabella di salto non cambiano mai. Consideriamo ad esempio gli indirizzi $FF81, $FF82 e $FF83. Questi tre indirizzi servono alla routine per inizializzare i circuiti dello schermo e della tastiera (registri) della scheda madre. L'indirizzo $FF81 ha sempre il codice operativo (un byte) di JSR. Gli indirizzi $FF82 e $FF83 hanno l'indirizzo vecchio o nuovo della subroutine (ancora nella ROM del sistema operativo) per eseguire l'inizializzazione. Un tempo, gli indirizzi $FF82 e $FF83 avevano il contenuto (indirizzo) di $FF5B che poteva cambiare con la successiva versione del sistema operativo. Tuttavia, gli indirizzi $FF81, $FF82 e $FF83 della tabella di salto non cambiano mai.
Per ogni voce di tre indirizzi, il primo indirizzo con JSR ha un'etichetta (nome). L'etichetta per $FF81 è PCINT. PCINT non cambia mai. Quindi, per inizializzare i registri dello schermo e della tastiera, il programmatore può semplicemente digitare 'JSR PCINT' che funziona per tutte le versioni del sistema operativo Commodore-64. La posizione (indirizzo iniziale) della subroutine effettiva, ad esempio $FF5B, potrebbe cambiare nel tempo con diversi sistemi operativi. Sì, sono presenti almeno due istruzioni JSR coinvolte nel programma utente che utilizza il sistema operativo ROM. Nel programma utente è presente un'istruzione JSR che salta a una voce nella tabella di salto. Ad eccezione degli ultimi sei indirizzi nella tabella di salto, il primo indirizzo di una voce nella tabella di salto ha un'istruzione JSR. Nel Kernal, alcune subroutine possono richiamare altre subroutine.
La tabella di salto Kernal inizia da $FF81 (incluso) salendo verso l'alto in gruppi di tre, ad eccezione degli ultimi sei byte che sono tre puntatori con indirizzi di byte inferiori: $FFFA, $FFFC e $FFFE. Tutte le routine del sistema operativo ROM sono codici riutilizzabili. Quindi, l'utente non deve riscriverli.
Diagramma a blocchi dell'unità di sistema Commodore-64
Lo schema seguente è più dettagliato di quello del capitolo precedente:
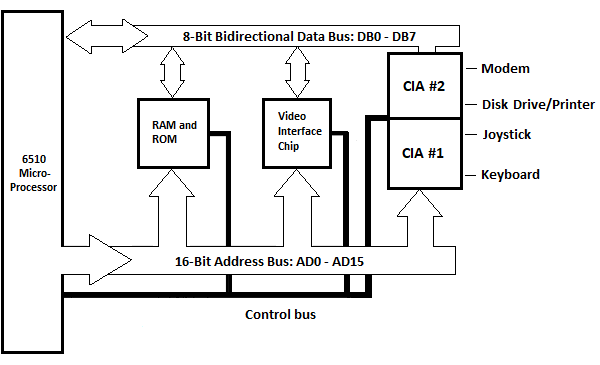
Fig. 5.12 Diagramma a blocchi dell'unità di sistema Commodore_64
ROM e RAM sono mostrate qui come un blocco. Qui è mostrato il chip di interfaccia video (IC) per la gestione delle informazioni sullo schermo, che non è stato mostrato nel capitolo precedente. Il blocco unico per i dispositivi di input/output, illustrato nel capitolo precedente, è qui rappresentato come due blocchi: CIA #1 e CIA #2. CIA sta per Complex Interface Adapter. Ognuno ha due porte parallele a otto bit (da non confondere con le porte esterne su una superficie verticale dell'unità di sistema) chiamate porta A e porta B. In questa situazione i CIA sono collegati a cinque dispositivi esterni. I dispositivi sono la tastiera, il joystick, l'unità disco/stampante e un modem. La stampante è collegata sul retro dell'unità disco. Sono inoltre presenti un circuito del dispositivo di interfaccia audio e un circuito della matrice logica programmabile che non sono mostrati.
Tuttavia, esiste una ROM dei caratteri che può essere scambiata con entrambe le CIA quando un personaggio viene inviato sullo schermo e non viene mostrato nello schema a blocchi.
Gli indirizzi RAM da $D000 a $DFFF per i circuiti di ingresso/uscita in assenza di ROM caratteri hanno la seguente mappa di memoria di dettaglio:
| Tabella 5.11 Mappa di memoria dettagliata da $ D000 a $ DFFF |
||
|---|---|---|
| Intervallo di sottoindirizzi | Circuito | Dimensioni (byte) |
| D000 – D3FF | VIC (controller dell'interfaccia video (chip)) | 1K |
| D400 – D7FF | SID (circuito audio) | 1K |
| D800 – DBFF | RAM a colori | Bocconcini da 1K |
| DC00 – DCFF | CIA #1 (tastiera, joystick) | 256 |
| DD00 – DDFF | CIA #2 (bus seriale, porta utente/RS-232) | 256 |
| DE00 – DEF | Aprire lo slot I/O n.1 | 256 |
| DF00 – DFFF | Aprire lo slot I/O n.2 | 256 |
5.2 I due adattatori di interfaccia complessi
Ci sono due particolari circuiti integrati (IC) nell'unità di sistema Commodore-64, e ciascuno di essi è chiamato adattatore di interfaccia complessa. Questi due chip vengono utilizzati per interfacciare la tastiera e altre periferiche al microprocessore. Ad eccezione del VIC e dello schermo, tutti i segnali di ingresso/uscita tra il microprocessore e le periferiche passano attraverso questi due circuiti integrati. Con il Commodore-64 non c'è comunicazione diretta tra la memoria e nessuna periferica. La comunicazione tra la memoria e qualsiasi periferica passa attraverso l'accumulatore del microprocessore, e uno di questi sono gli adattatori CIA (IC). Gli IC sono indicati come CIA #1 e CIA #2. CIA sta per Complex Interface Adapter.
Ogni CIA ha 16 registri. Ad eccezione dei registri timer/contatore nella CIA, ciascun registro ha una larghezza di 8 bit e ha un indirizzo di memoria. Gli indirizzi dei registri di memoria per CIA #1 provengono da $DC00 (56320 10 ) in $DC0F (56335 10 ). Gli indirizzi dei registri di memoria per CIA #2 provengono da $DD00 (56576 10 ) a $DD0F (56591 10 ). Sebbene questi registri non siano nella memoria dei circuiti integrati, fanno parte della memoria. Nella mappa di memoria intermedia, l'area I/O da $D000 a $DFFF comprende gli indirizzi CIA da $DC00 a $DC0F e da $DD00 a $DD0F. La maggior parte dell'area di memoria I/O RAM da $D000 a $DFFF può essere scambiata con il banco di memoria della ROM caratteri per i caratteri dello schermo. Ecco perché quando i personaggi vengono inviati sullo schermo le periferiche non possono funzionare; anche se l'utente potrebbe non notarlo poiché lo scambio avanti e indietro è veloce.
Ci sono due registri nella CIA n.1 chiamati Porta A e Porta B. I loro indirizzi sono rispettivamente $DC00 e $DC01. Ci sono anche due registri nella CIA n. 2 chiamati Porta A e Porta B. Naturalmente, i loro indirizzi sono diversi; sono rispettivamente $DD00 e $DD01.
La porta A o la porta B in entrambe le CIA è una porta parallela. Ciò significa che può inviare i dati alla periferica in otto bit contemporaneamente o ricevere i dati dal microprocessore in otto bit contemporaneamente.
Associato alla porta A o alla porta B c'è un Data Direction Register (DDR). Il registro della direzione dei dati per la porta A di CIA #1 (DDRA1) si trova nella posizione del byte di memoria $DC02. Il registro della direzione dei dati per la porta B di CIA #1 (DDRB1) si trova nella posizione del byte di memoria $DC03. Il registro della direzione dei dati per la porta A di CIA #2 (DDRA2) si trova nella posizione del byte di memoria di $DD02. Il registro della direzione dei dati per la porta B di CIA #2 (DDRB2) si trova nella posizione del byte di memoria $DD03.
Ora, ciascun bit per la porta A o la porta B può essere impostato dal registro della direzione dei dati corrispondente come ingresso o uscita. Ingresso significa che l'informazione passa dalla periferica al microprocessore attraverso una CIA. Output significa che l'informazione passa dal microprocessore alla periferica attraverso una CIA.
Se deve essere inserita una cella di una porta (registro), il bit corrispondente nel registro della direzione dei dati è 0. Se deve essere emessa una cella di una porta (registro), il bit corrispondente nel registro della direzione dei dati è 1. Nella maggior parte dei casi, tutti gli 8 bit di una porta sono programmati per essere input o output. Quando il computer è acceso, la porta A è programmata per l'output e la porta B è programmata per l'input. Il seguente codice rende la porta CIA #1 A come output e la porta CIA #1 B come input:
LDA #$FF
STA DDRA1 ; $DC00 è diretto da $DC02
LDA #$00
STA DDRB1; $DC01 è diretto da $DC03
DDRA1 è l'etichetta (nome della variabile) per la posizione del byte di memoria di $DC02 e DDRB1 è l'etichetta (nome della variabile) per la posizione del byte di memoria di $DC03. La prima istruzione carica 11111111 nell'accumulatore del µP. La seconda istruzione lo copia nel registro di direzione dati della porta A della CIA n. 1. La terza istruzione carica 00000000 nell'accumulatore del µP. La quarta istruzione lo copia nel registro di direzione dati della porta B della CIA n. 1. Questo codice si trova in una delle subroutine del sistema operativo che esegue questa inizializzazione all'accensione del computer.
Ciascuna CIA dispone di una linea di richiesta del servizio di interruzione al microprocessore. Quello della CIA n. 1 va a IRQ pin del µP. Quello della CIA n. 2 va a NMI pin del µP. Ricordati che NMI ha una priorità più alta di IRQ .
5.3 Programmazione in linguaggio assembly della tastiera
Ci sono solo tre possibili interruzioni per il Commodore-64: IRQ , BRK e NMI . Il puntatore della tabella di salto per IRQ si trova agli indirizzi $FFFE e $FFFF nella ROM (sistema operativo) che corrisponde a una subroutine ancora nel sistema operativo (ROM). Il puntatore della tabella di salto per BRK si trova negli indirizzi $FFFC e $FFFD nell'OS, il che corrisponde a una subroutine ancora nell'OS (ROM). Il puntatore della tabella di salto per NMI si trova negli indirizzi $FFFA e $FFFB nel sistema operativo e corrisponde a una subroutine ancora nel sistema operativo (ROM). Per il IRQ , ci sono in realtà due subroutine. Pertanto, l'interruzione software BRK (istruzione) ha il proprio puntatore alla tabella di salto. Il puntatore della tabella di salto per IRQ porta al codice che decide se è l'interruzione hardware o l'interruzione software ad essere attivata. Se si tratta dell'interruzione hardware, la routine for IRQ è chiamato. Se si tratta dell'interruzione del software (BRK), viene richiamata la routine per BRK. In una delle versioni del sistema operativo, la subroutine per IRQ è a $EA31 e la subroutine per BRK è a $FE66. Questi indirizzi sono inferiori a $FF81, quindi non sono voci della tabella di salto e potrebbero cambiare con la versione del sistema operativo. Ci sono tre routine interessanti in questo argomento: quella che controlla se si tratta di un tasto premuto o di un BRK, quella che è a $FE43 e quella che può anche cambiare con la versione del sistema operativo.
Il computer Commodore-64 è come un'enorme macchina da scrivere (verso l'alto) in apparenza senza la sezione di stampa (testina e carta). La tastiera è collegata a CIA #1. Per impostazione predefinita, il CIA #1 esegue la scansione della tastiera ogni 1/60 di secondo senza alcuna interferenza di programmazione. Quindi, ogni 1/60 di secondo, la CIA n. 1 invia un IRQ al µP. Ce n'è solo uno IRQ pin al µP che proviene solo dalla CIA #1. L'unico pin di ingresso di NMI del µP, che è diverso da IRQ , proviene solo dalla CIA #2 (fare riferimento alla seguente illustrazione). BRK è in realtà un'istruzione in linguaggio assembly codificata in un programma utente.
Quindi, ogni 1/60 di secondo, il IRQ viene richiamata la routine puntata da $FFFE e $FFFF. La routine controlla se viene premuto un tasto o se viene incontrata l'istruzione BRK. Se viene premuto un tasto, viene richiamata la routine per gestire la pressione del tasto. Se si tratta di un'istruzione BRK, viene richiamata la routine per gestire BRK. Se non è nessuno dei due, non succede nulla. Potrebbe non verificarsi nessuna delle due cose, ma la CIA n. 1 invia IRQ al µP ogni 1/60 di secondo.
La coda della tastiera, nota anche come buffer della tastiera, è un intervallo di posizioni di byte RAM da $ 0277 a $ 0280 inclusi; 1010 byte in tutto. Questo è un buffer First-IN-First-Out. Ciò significa che il primo personaggio ad arrivare è il primo ad andarsene. Un carattere dell'Europa occidentale occupa un byte.
Pertanto, mentre il programma non consuma alcun carattere quando viene premuto un tasto, il codice del tasto entra in questo buffer (coda). Il buffer continua a riempirsi finché non rimangono dieci caratteri. Qualsiasi carattere premuto dopo il decimo carattere non viene registrato. Viene ignorato finché almeno un carattere non viene ottenuto (consumato) dalla coda. La tabella di salto ha una voce per una subroutine che porta il primo carattere dalla coda al microprocessore. Ciò significa che prende il primo carattere che entra in coda e lo inserisce nell'accumulatore del µP. La subroutine di salto della tabella per fare ciò è chiamata GETIN (per Get-In). Il primo byte per la voce di tre byte nella tabella di salto viene contrassegnato come GETIN (indirizzo $FFE4). I due byte successivi sono il puntatore (indirizzo) che punta alla routine effettiva nella ROM (OS). È responsabilità del programmatore chiamare questa routine. In caso contrario, il buffer della tastiera rimarrà pieno e tutti i tasti premuti di recente verranno ignorati. Il valore che entra nell'accumulatore è il valore ASCII della chiave corrispondente.
Come fanno i codici chiave ad entrare in coda? Esiste una routine di salto della tabella chiamata SCNKEY (per chiave di scansione). Questa routine può essere richiamata sia dal software che dall'hardware. In questo caso, viene chiamato da un circuito elettronico (fisico) nel microprocessore quando viene inviato il segnale elettrico IRQ è basso. Il modo esatto in cui ciò viene fatto non viene affrontato in questo corso di carriera online.
Il codice per ottenere il primo codice chiave dal buffer della tastiera nell'accumulatore A è solo una riga:
ENTRA
Se il buffer della tastiera è vuoto, $00 viene inserito nell'accumulatore. Ricorda che il codice ASCII per zero non è $00; è $ 30. $ 00 significa Nullo. In un programma, potrebbe esserci un punto in cui il programma deve attendere la pressione di un tasto. Il codice per questo è:
ASPETTA CHE JSR OTTIENI
CMP #$00
RANA ASPETTA
Nella prima riga, 'WAIT' è un'etichetta che identifica l'indirizzo RAM in cui viene inserita (digitata) l'istruzione JSR. Anche GETIN è un indirizzo. È l'indirizzo del primo dei tre byte corrispondenti nella tabella di salto. La voce GETIN, così come tutte le voci nella tabella di salto (tranne le ultime tre), è composta da tre byte. Il primo byte della voce è l'istruzione JSR. I due byte successivi sono l'indirizzo del corpo dell'effettiva subroutine GETIN che è ancora nella ROM (OS) ma sotto la tabella di salto. Quindi la voce dice di passare alla subroutine GETIN. Se la coda della tastiera non è vuota, GETIN inserisce nell'accumulatore il codice chiave ASCII della coda First-In-First-Out. Se la coda è vuota, nell'accumulatore viene inserito Null ($00).
La seconda istruzione confronta il valore dell'accumulatore con $00. Se è $00, significa che la coda della tastiera è vuota e l'istruzione CMP invia 1 al flag Z del registro di stato del processore (chiamato semplicemente registro di stato). Se il valore in A non è $00, l'istruzione CMP invia 0 al flag Z del registro di stato.
La terza istruzione che è 'BEQ WAIT' rimanda il programma alla prima istruzione se il flag Z del registro di stato è 1. La prima, la seconda e la terza istruzione vengono eseguite ripetutamente in ordine finché non viene premuto un tasto sulla tastiera . Se non viene mai premuto un tasto il ciclo si ripete all'infinito. Un segmento di codice come questo viene normalmente scritto con un segmento di codice di temporizzazione che abbandona il ciclo dopo un po' di tempo se un tasto non viene mai premuto (fare riferimento alla discussione seguente).
Nota : la tastiera è il dispositivo di input predefinito e lo schermo è il dispositivo di output predefinito.
5.4 Canale, numero dispositivo e numero file logico
Le periferiche utilizzate in questo capitolo per spiegare il sistema operativo Commodore-64 sono la tastiera, lo schermo (monitor), l'unità disco con dischetto, la stampante e il modem che si collega tramite l'interfaccia RS-232C. Affinché possa avvenire la comunicazione tra questi dispositivi e l'unità di sistema (microprocessore e memoria), è necessario stabilire un canale.
Un canale è costituito da un buffer, un numero di dispositivo, un numero di file logico e facoltativamente un indirizzo secondario. La spiegazione di questi termini è la seguente:
Un tampone
Si noti dalla sezione precedente che quando viene premuto un tasto, il suo codice deve andare in una posizione byte nella RAM di una serie di dieci posizioni consecutive. Questa serie di dieci posizioni costituisce il buffer della tastiera. Ogni dispositivo di input o output (periferico) ha una serie di posizioni consecutive nella RAM chiamate buffer.
Numero del dispositivo
Con il Commodore-64, ad ogni periferica viene assegnato un numero di dispositivo. La tabella seguente mostra i diversi dispositivi e i loro numeri:
| Tabella 5.41 Numeri di dispositivo Commodore 64 e relativi dispositivi |
|
|---|---|
| Numero | Dispositivo |
| 0 | Tastiera |
| 1 | Unità nastro |
| 2 | Interfaccia RS 232C ad es. un modem |
| 3 | Schermo |
| 4 | Stampante n. 1 |
| 5 | Stampante n. 2 |
| 6 | Plotter n.1 |
| 7 | Plotter n.2 |
| 8 | Unità disco |
| 9 ¦ ¦ ¦ 30 |
Da 8 (inclusi) fino a 22 dispositivi di archiviazione aggiuntivi |
Esistono due tipi di porte per un computer. Un tipo è esterno, sulla superficie verticale dell'unità di sistema. L'altro tipo è interno. Questa porta interna è un registro. Il Commodore-64 ha quattro porte interne: porta A e porta B per CIA 1 e porta A e porta B per CIA 2. C'è una porta esterna per il Commodore-64 chiamata porta seriale. I dispositivi con il numero 3 verso l'alto sono collegati alla porta seriale. Sono collegati a margherita (uno collegato dietro l'altro), ognuno dei quali è identificabile dal numero del dispositivo. I dispositivi con il numero 8 verso l'alto sono generalmente i dispositivi di archiviazione.
Nota : Il dispositivo di input predefinito è la tastiera con il numero di dispositivo 0. Il dispositivo di output predefinito è lo schermo con il numero di dispositivo 3.
Numero di file logico
Un numero di file logico è un numero assegnato a un dispositivo (periferica) nell'ordine in cui vengono aperti per l'accesso. Vanno da 010 a 255 10 .
Indirizzo secondario
Immagina che due file (o più di un file) siano aperti sul disco. Per distinguere tra questi due file, vengono utilizzati gli indirizzi secondari. Gli indirizzi secondari sono numeri che variano da dispositivo a dispositivo. Il significato di 3 come indirizzo secondario per una stampante è diverso dal significato di 3 come indirizzo secondario per un'unità disco. Il significato dipende da funzionalità come quando un file viene aperto per la lettura o quando un file viene aperto per la scrittura. I possibili numeri secondari partono da 0 10 a 15 10 per ciascun dispositivo. Per molti dispositivi, il numero 15 viene utilizzato per inviare comandi.
Nota : Il numero del dispositivo è noto anche come indirizzo del dispositivo e il numero secondario è anche noto come indirizzo secondario.
Identificazione di un bersaglio periferico
Per la mappatura di memoria predefinita del Commodore, gli indirizzi di memoria da $0200 a $02FF (pagina 2) sono utilizzati esclusivamente dal sistema operativo in ROM (Kernal) e non dal sistema operativo più il linguaggio BASIC. Sebbene BASIC possa comunque utilizzare le posizioni tramite il sistema operativo ROM.
Il modem e la stampante sono due destinazioni periferiche diverse. Se due file vengono aperti dal disco, si tratta di due destinazioni diverse. Con la mappa di memoria predefinita, ci sono tre tabelle (elenchi) consecutive che possono essere viste come un'unica grande tabella. Queste tre tabelle mantengono la relazione tra i numeri dei file logici, i numeri dei dispositivi e gli indirizzi secondari. In questo modo diventa identificabile un canale specifico o un target di ingresso/uscita. Le tre tabelle sono chiamate Tabelle di file. Gli indirizzi RAM e ciò che hanno sono:
$0259 — $0262: tabella con etichetta, LAT, contenente fino a dieci numeri di file logici attivi.
$0263 — $026C: tabella con etichetta, FAT, fino a dieci numeri di dispositivo corrispondenti.
$026D — $0276: Tabella con etichetta, SAT, di dieci indirizzi secondari corrispondenti.
Qui, '-' significa 'a' e un numero occupa un byte.
Il lettore potrebbe chiedere: 'Perché il buffer per ciascun dispositivo non è incluso nell'identificazione di un canale?' Ebbene, la risposta è che con il commodore-64 ogni dispositivo esterno (periferica) ha una serie fissa di byte nella RAM (mappa di memoria). Senza alcun canale aperto, le loro posizioni sono ancora presenti nella memoria. Il buffer per la tastiera, ad esempio, è fissato da $0277 a $0280 (inclusi) per la mappa di memoria predefinita.
Le subroutine Kernal SETLFS e SETNAM
SETLFS e SETNAM sono routine Kernal. Un canale può essere visto come un file logico. Per aprire un canale è necessario produrre il numero del file logico, il numero del dispositivo e un indirizzo secondario opzionale. Potrebbe essere necessario anche un nome file opzionale (testo). La routine SETLFS imposta il numero di file logico, il numero di dispositivo e un indirizzo secondario opzionale. Questi numeri vengono inseriti nelle rispettive tabelle. La routine SETNAM imposta un nome stringa per il file che può essere obbligatorio per un canale e facoltativo per un altro canale. Questo è costituito da un puntatore (indirizzo a due byte) nella memoria. Il puntatore punta all'inizio della stringa (nome) che potrebbe trovarsi in un altro posto nella memoria. Il nome della stringa inizia con un byte che ha la lunghezza della stringa, seguito dal testo (nome). Il nome ha una lunghezza massima di sedici byte (lungo).
Per richiamare la routine SETLFS, il programma utente deve saltare (JSR) all'indirizzo $FFBA della tabella di salto del sistema operativo nella ROM per la mappa di memoria predefinita. Ricordare che, ad eccezione degli ultimi sei byte della tabella di salto, ogni voce è composta da tre byte. Il primo byte è l'istruzione JSR, che poi salta alla subroutine, inizia dall'indirizzo nei due byte successivi. Per richiamare la routine SETNAM il programma utente deve saltare (JSR) all'indirizzo $FFBD della tabella di salto dell'OS nella ROM. L'utilizzo di queste due routine è mostrato nella discussione seguente.
5.5 Apertura di un canale, apertura di un file logico, chiusura di un file logico e chiusura di tutti i canali I/O
Un canale è costituito da un buffer di memoria, un numero di file logico, un numero di dispositivo (indirizzo del dispositivo) e un indirizzo secondario opzionale (un numero). Un file logico (un'astrazione) identificato da un numero di file logico può fare riferimento a una periferica come una stampante, un modem, un'unità disco, ecc. Ciascuno di questi diversi dispositivi dovrebbe avere numeri di file logici diversi. Ci sono molti file nel disco. Un file logico può anche fare riferimento a un particolare file nel disco. Quel particolare file ha anche un numero di file logico diverso da quelli delle periferiche come la stampante o il modem. Il numero di file logico viene fornito dal programmatore. Può essere qualsiasi numero compreso tra 010 ($00) e 25510 ($FF).
La routine SETLFS del sistema operativo
La routine OS SETLFS a cui si accede saltando (JSR) alla tabella di salto della ROM del sistema operativo in $FFBA imposta il canale. È necessario inserire il numero di file logico nella tabella dei file che è LAT ($0259 — $0262). È necessario inserire il numero del dispositivo corrispondente nella tabella dei file che è FAT ($0263 — $026C). Se l'accesso al file (dispositivo) richiede un numero secondario, è necessario inserire l'indirizzo secondario corrispondente (numero) nella tabella dei file che è SAT ($026D — $0276).
Per poter funzionare, la subroutine SETLFS necessita di ottenere il numero logico del file dall'accumulatore µP; è necessario ottenere il numero del dispositivo dal registro µP X. Se richiesto dal canale, è necessario ottenere l'indirizzo secondario dal registro µP Y.
Il numero di file logico viene deciso dal programmatore. I numeri di file logici che fanno riferimento a dispositivi diversi sono diversi. Ora, prima di chiamare la routine SETLFS, il programmatore dovrebbe inserire il numero del file logico nell'accumulatore µP. Il numero del dispositivo viene letto da una tabella (documento) come nella Tabella 5.41. Il programmatore dovrebbe anche dover inserire il numero del dispositivo nel registro µP X. Il fornitore di un dispositivo come una stampante, un'unità disco, ecc. fornisce i possibili indirizzi secondari e il loro significato per il dispositivo. Se il canale necessita di un indirizzo secondario, il programmatore dovrà ricavarlo dal documento fornito con il dispositivo (periferica). Se l'indirizzo secondario (numero) è necessario, il programmatore deve inserirlo nel registro µP Y prima di chiamare la subroutine SETLFS. Se non è necessario un indirizzo secondario, il programmatore deve inserire il numero $FF nel registro µP Y prima di chiamare la subroutine SETLFS.
La subroutine SETLFS viene chiamata senza alcun argomento. I suoi argomenti sono già nei tre registri del 6502 µP. Dopo aver inserito i numeri appropriati nei registri, la routine viene richiamata nel programma semplicemente con quanto segue in una riga separata:
JSR SETLFS
La routine inserisce i diversi numeri in modo appropriato nelle rispettive tabelle di file.
La routine OS SETNAM
È possibile accedere alla routine OS SETNAM saltando (JSR) alla tabella di salto della ROM del sistema operativo in $FFBD. Non tutte le destinazioni hanno nomi di file. Per quelli che hanno destinazioni (come i file nel disco), è necessario impostare il nome del file. Supponiamo che il nome del file sia 'mydocum' che consiste di 7 byte senza virgolette. Supponiamo che questo nome si trovi nelle posizioni da $ C101 a $ C107 (incluse) e che la lunghezza di $ 07 sia nella posizione $ C100. L'indirizzo iniziale dei caratteri della stringa è $C101. Il byte più basso dell'indirizzo iniziale è $01 e il byte più alto è $C1.
Prima di chiamare la routine SETNAM, il programmatore deve inserire il numero $07 (lunghezza della stringa) nell'accumulatore µP. Il byte più basso dell'indirizzo iniziale della stringa $01 viene inserito nel registro µP X. Il byte più alto dell'indirizzo iniziale della stringa di $C1 viene inserito nel registro µP Y. La subroutine viene chiamata semplicemente con quanto segue:
JSR SETNAM
La routine SETNAM associa i valori dei tre registri al canale. Successivamente non è necessario che i valori rimangano nei registri. Se il canale non necessita di un nome file, il programmatore deve inserire $00 nell'accumulatore µP. In questo caso, i valori presenti nei registri X e Y vengono ignorati.
La routine di apertura del sistema operativo
È possibile accedere alla routine OS OPEN passando (JSR) alla tabella di salto della ROM del sistema operativo in $FFC0. Questa routine utilizza il numero logico del file, il numero del dispositivo (e del buffer), un possibile indirizzo secondario e un possibile nome del file, per fornire una connessione tra il computer Commodore e il file nel dispositivo esterno o il dispositivo esterno stesso.
Questa routine, come tutte le altre routine della ROM del sistema operativo Commodore, non accetta argomenti. Sebbene utilizzi i registri µP, nessuno dei registri deve essere precaricato con argomenti (valori). Per codificarlo, basta digitare quanto segue dopo aver chiamato SETLFS e SETNAM:
JSR APERTO
Possono verificarsi errori con la routine OPEN. Ad esempio, il file potrebbe non essere trovato per la lettura. Quando si verifica un errore, la routine fallisce e inserisce il numero di errore corrispondente nell'accumulatore µP e imposta il flag di riporto (a 1) del registro di stato µP. La tabella seguente fornisce i numeri di errore e il loro significato:
| Tabella 5.51 Numeri di errore del kernel e relativi significati per la routine di apertura della ROM del sistema operativo |
||
|---|---|---|
| Numero errore | Descrizione | Esempio |
| 1 | TROPPI FILE | OPEN quando sono già aperti dieci file |
| 2 | FILE APERTO | APERTO 1,3: APERTO 1,4 |
| 3 | FILE NON APERTO | STAMPA#5 senza APERTURA |
| 4 | FILE NON TROVATO | CARICARE “NONEXISTENF”,8 |
| 5 | DISPOSITIVO NON PRESENTE | APERTURA 11,11: STAMPA#11 |
| 6 | NON FILE DI IMMISSIONE | APRI “SEQ,S,W”: RICEVI#8,X$ |
| 7 | NON FILE DI USCITA | APERTO 1,0: STAMPA#1 |
| 8 | NOME FILE MANCANTE | CARICARE “”,8 |
| 9 | DISPOSITIVO ILLEGALE N. | CARICARE “PROGRAMMA”,3 |
Questa tabella è presentata in un modo che il lettore probabilmente vedrà in molti altri posti.
La routine CHKIN del sistema operativo
È possibile accedere alla routine OS CHKIN saltando (JSR) alla tabella di salto della ROM del sistema operativo in $FFC6. Dopo aver aperto un file (file logico), si deve decidere se l'apertura sarà per l'input o per l'output. La routine CHKIN rende l'apertura di un canale di input. Questa routine necessita di leggere il numero di file logico dal registro µP X. Quindi, il programmatore deve inserire il numero logico del file nel registro X prima di chiamare questa routine. Si chiama semplicemente così:
JSR CHKIN
La routine CHKOUT del sistema operativo
È possibile accedere alla routine OS CHKOUT saltando (JSR) alla tabella di salto della ROM del sistema operativo in $FFC9. Dopo aver aperto un file (file logico), si deve decidere se l'apertura sarà per l'input o per l'output. La routine CHKOUT rende l'apertura di un canale di uscita. Questa routine necessita di leggere il numero di file logico dal registro µP X. Quindi, il programmatore deve inserire il numero logico del file nel registro X prima di chiamare questa routine. Si chiama semplicemente così:
JSR CHKOUT
La routine di chiusura del sistema operativo
È possibile accedere alla routine OS CLOSE saltando (JSR) alla tabella di salto della ROM del sistema operativo in $FFC3. Dopo che un file logico è stato aperto e i byte sono stati trasmessi, il file logico deve essere chiuso. La chiusura del file logico libera il buffer nell'unità di sistema per essere utilizzato da qualche altro file logico che deve ancora essere aperto. Vengono cancellati anche i parametri corrispondenti nelle tre tabelle dei file. La posizione RAM per il numero di file aperti viene diminuita di 1.
Quando il computer viene acceso, viene eseguito il ripristino dell'hardware per il microprocessore e gli altri chip principali (circuiti integrati) sulla scheda madre. Segue l'inizializzazione di alcune locazioni di memoria RAM e di alcuni registri in alcuni chip della scheda madre. Nel processo di inizializzazione, la posizione di memoria in byte dell'indirizzo $0098 nella pagina zero viene assegnata con l'etichetta NFILES o LDTND, a seconda della versione del sistema operativo. Mentre il computer è in funzione, questa posizione di un byte di 8 bit contiene il numero di file logici che vengono aperti e l'indice dell'indirizzo iniziale delle tre tabelle di file consecutive. In altre parole, questo byte ha il numero di file aperti che viene decrementato di 1 quando il file logico viene chiuso. Quando il file logico viene chiuso, l'accesso al dispositivo terminale (di destinazione) o al file effettivo sul disco non è più possibile.
Per chiudere un file logico, il programmatore deve inserire il numero del file logico nell'accumulatore µP. Si tratta dello stesso numero di file logico utilizzato per aprire il file. La routine CLOSE ne ha bisogno per chiudere quel particolare file. Come altre routine della ROM del sistema operativo, la routine CLOSE non accetta argomenti, sebbene il valore utilizzato dall'accumulatore sia in qualche modo un argomento. La riga di istruzioni del linguaggio assembly è semplicemente:
JSR CHIUSO
Le subroutine (routine) del linguaggio assembly 6502 personalizzate o predefinite non accettano argomenti. Tuttavia, gli argomenti arrivano in modo informale inserendo i valori che la subroutine utilizzerà nei registri del microprocessore.
La routine CLRCN
È possibile accedere alla routine OS CLRCHN saltando (JSR) alla tabella di salto della ROM del sistema operativo in $FFCC. CLRCHN sta per CLeAR CHanneL. Quando un file logico viene chiuso, i suoi parametri relativi al numero del file logico, al numero del dispositivo e all'eventuale indirizzo secondario vengono eliminati. Quindi, il canale per il file logico viene cancellato.
Il manuale dice che la routine OS CLRCHN cancella tutti i canali aperti e ripristina i numeri di dispositivo predefiniti e altri valori predefiniti. Ciò significa che è possibile modificare il numero di dispositivo di una periferica? Beh, non proprio. Durante l'inizializzazione del sistema operativo, la posizione in byte dell'indirizzo $0099 viene fornita con l'etichetta DFLTI per contenere il numero del dispositivo di input corrente quando il computer è in funzione. Il Commodore-64 può accedere solo ad una periferica alla volta. Durante l'inizializzazione del sistema operativo, la posizione in byte dell'indirizzo $009A viene fornita con l'etichetta DFLTO per contenere il numero del dispositivo di output corrente quando il computer è in funzione.
Quando viene richiamata la subroutine CLRCHN, imposta la variabile DFLTI su 0 ($00) che è il numero del dispositivo di input predefinito (tastiera). Imposta la variabile DFLTO su 3 ($03), che è il numero del dispositivo di output predefinito (schermo). Altre variabili del numero di dispositivo vengono reimpostate in modo simile. Questo è il significato di ripristinare (o ripristinare) i dispositivi di ingresso/uscita alla normalità (valori predefiniti).
Il manuale del Commodore-64 dice che dopo che è stata chiamata la routine CLRCHN, i file logici aperti rimangono aperti e potrebbero ancora trasmettere i byte (dati). Ciò significa che la routine CLRCHN non cancella le voci corrispondenti nelle tabelle dei file. Il nome CLRCHN è piuttosto ambiguo per quanto riguarda il suo significato.
5.6 Invio del personaggio sullo schermo
Il circuito integrato principale (IC) per gestire la visualizzazione di caratteri e grafica sullo schermo è chiamato Video Interface Controller (chip) che è abbreviato come VIC nel Commodore-64 (in realtà VIC II per VIC versione 2). Affinché un'informazione (valori) possa andare sullo schermo, deve passare attraverso il VIC II prima di raggiungere lo schermo.
Lo schermo è composto da 25 righe e 40 colonne di celle di caratteri. Ciò fa 40 x 25 = 1000 caratteri che possono essere visualizzati sullo schermo. Il VIC II legge i corrispondenti caratteri nelle 1000 posizioni di byte consecutive della memoria RAM. L'insieme di queste 1000 posizioni è noto come memoria dello schermo. Ciò che accade in queste 1000 posizioni sono i codici dei caratteri. Per il Commodore-64, i codici dei caratteri sono diversi dai codici ASCII.
Un codice carattere non è un modello di carattere. Esiste anche la cosiddetta ROM dei caratteri. La ROM dei caratteri è composta da tutti i tipi di caratteri, alcuni dei quali corrispondono ai caratteri sulla tastiera. La ROM dei caratteri è diversa dalla memoria dello schermo. Quando un carattere deve essere visualizzato sullo schermo, il codice del carattere viene inviato in una posizione tra le 1000 posizioni della memoria dello schermo. Da lì, il modello corrispondente viene selezionato dalla ROM dei caratteri che deve essere visualizzata sullo schermo. La scelta del modello corretto nella ROM dei caratteri da un codice carattere viene eseguita dal VIC II (hardware).
Molte posizioni di memoria comprese tra $D000 e $DFFF hanno due scopi: vengono utilizzate per gestire operazioni di input/output diverse dallo schermo o utilizzate come ROM di caratteri per lo schermo. Sono interessati due blocchi di memoria. Uno è la RAM e l'altro è la ROM per la ROM dei caratteri. Lo scambio dei banchi per gestire l'input/output o i pattern di caratteri (ROM dei caratteri) viene effettuato dal software (routine del sistema operativo nella ROM da $F000 a $FFFF).
Nota : Il VIC dispone di registri indirizzati con indirizzi dello spazio di memoria compresi nell'intervallo $D000 e $DFFF.
La routine CHROUT
È possibile accedere alla routine OS CHROUT saltando (JSR) alla tabella di salto della ROM del sistema operativo in $FFD2. Questa routine, quando richiamata, prende il byte che il programmatore ha inserito nell'accumulatore µP e lo stampa sullo schermo dove si trova il cursore. Il segmento di codice per stampare il carattere 'E', ad esempio, è:
LDA #$05
CROTA
Lo 0516 non è il codice ASCII per “E”. Il Commodore-64 ha i propri codici carattere per lo schermo dove $05 significa “E”. Il numero #$05 viene inserito nella memoria dello schermo prima che VIC lo invii allo schermo. Queste due righe di codifica dovrebbero arrivare dopo l'impostazione del canale, l'apertura del file logico e la chiamata della routine CHKOUT per l'output. Il codice completo è:
; Canale di impostazione
LDA#$40; numero di file logico
LDX #$03 ; il numero del dispositivo per lo schermo è $ 03
LDY #$FF ; nessun indirizzo secondario
JSR SETLFS ; impostare il canale correttamente
; no SETNAM poiché lo schermo non necessita di un nome
;
; Apri file logico
JSR APERTO
; Imposta il canale per l'uscita
LDX#$40; numero di file logico
JSR CHKOUT
;
; Caratteri di output sullo schermo
LDA #$05
JSR CHROUT
; Chiudi il file logico
LDA#$40
JSR CHIUSO
L'apertura deve essere chiusa prima di eseguire un altro programma. Supponiamo che l'utente del computer digiti un carattere sulla tastiera quando previsto. Il seguente programma stampa un carattere dalla tastiera allo schermo:
; Canale di impostazione
LDA#$40; numero di file logico
LDX #$03 ; il numero del dispositivo per lo schermo è $ 03
LDY #$FF ; nessun indirizzo secondario
JSR SETLFS ; impostare il canale correttamente
; no SETNAM poiché lo schermo non necessita di un nome
;
; Apri file logico
JSR APERTO
; Imposta il canale per l'uscita
LDX#$40; numero di file logico
JSR CHKOUT
;
; Inserisci il carattere dalla tastiera
ATTENDERE JSR GETIN; inserisce $00 in A se la coda della tastiera è vuota
CMP#$00; Se $ 00 vanno ad A, allora Z è 1 con il confronto
BEQ ATTESA ; OTTIENI di nuovo dalla coda se 0 va all'accumulatore
BNE PRNSCRN ; vai a PRNSCRN se Z è 0, perché A non ha più $ 00
; Caratteri di output sullo schermo
PRNSCRN JSR CHROUT ; invia il carattere in A allo schermo
; Chiudi il file logico
LDA#$40
JSR CHIUSO
Nota : WAIT e PRNSCRN sono le etichette che identificano gli indirizzi. Il byte dalla tastiera che arriva nell'accumulatore µP è un codice ASCII. Il codice corrispondente da inviare allo schermo dal Commodore-64 deve essere diverso. Nel programma precedente questo non è stato preso in considerazione per ragioni di semplicità.
5.7 Invio e ricezione di byte per l'unità disco
Ci sono due adattatori di interfaccia complessi nell'unità di sistema (scheda madre) del Commodore-64 chiamati VIA #1 e CIA #2. Ogni CIA ha due porte parallele chiamate Porta A e Porta B. Sulla superficie verticale sul retro dell'unità di sistema Commodre-64 è presente una porta esterna chiamata porta seriale. Questa porta ha 6 pin, uno dei quali è per i dati. I dati entrano o escono dall'unità di sistema in serie, un bit alla volta.
Otto bit paralleli dalla porta interna A della CIA #2, ad esempio, possono uscire dall'unità di sistema attraverso la porta seriale esterna dopo essere stati convertiti in dati seriali da un registro a scorrimento nella CIA. I dati seriali a otto bit dalla porta seriale esterna possono entrare nella porta interna A della CIA n. 2 dopo essere stati convertiti in dati paralleli da un registro a scorrimento nella CIA.
L'unità di sistema Commodore-64 (unità base) utilizza un'unità disco esterna con un dischetto. Una stampante può essere collegata a questa unità disco in modalità daisy chain (collegando i dispositivi in serie come una stringa). Il cavo dati per l'unità disco è collegato alla porta seriale esterna dell'unità di sistema Commodore-64. Ciò significa che anche una stampante collegata a catena è collegata alla stessa porta seriale. Questi due dispositivi sono identificati da due diversi numeri di dispositivo (tipicamente 8 e 4, rispettivamente).
L'invio o la ricezione dei dati per l'unità disco segue la stessa procedura descritta in precedenza. Questo è:
- Impostazione del nome del file logico (numero) che è uguale a quello del file del disco reale utilizzando la routine SETNAM.
- Apertura del file logico utilizzando la routine OPEN.
- Decidere se è input o output utilizzando la routine CHKOUT o CHKIN.
- Invio o ricezione dei dati utilizzando l'istruzione STA e/o LDA.
- Chiusura del file logico utilizzando la routine CLOSE.
Il file logico deve essere chiuso. La chiusura del file logico chiude effettivamente quel particolare canale. Quando si imposta il canale per l'unità disco, il numero logico del file viene deciso dal programmatore. È un numero compreso tra $00 e $FF (inclusi). Non dovrebbe essere un numero già scelto per qualsiasi altro dispositivo (o file vero e proprio). Il numero del dispositivo è 8 se è presente una sola unità disco. L'indirizzo secondario (numero) si ottiene dal manuale dell'unità disco. Il seguente programma utilizza 2. Il programma scrive la lettera 'E' (ASCII) in un file nel disco chiamato 'miodoc.doc'. Si presuppone che questo nome inizi con l'indirizzo di memoria di $C101. Pertanto, il byte più basso di $01 deve trovarsi nel registro X e il byte più alto di $C1 deve trovarsi nel registro Y prima che venga richiamata la routine SETNAM. Anche il registro A dovrebbe avere il numero $09 prima che venga chiamata la routine SETNAM.
; Canale di impostazione
LDA#$40; numero di file logico
LDX #$08 ; numero di dispositivo per la prima unità disco
LDY #$02 ; indirizzo secondario
JSR SETLFS ; impostare il canale correttamente
;
; Il file nell'unità disco necessita di un nome (già in memoria)
LDA #$09
LDX #$01
LDY#$C1
JSR SETNAM
; Apri file logico
JSR APERTO
; Imposta il canale per l'uscita
LDX#$40; numero di file logico
JSR CHKOUT ;per la scrittura
;
; Caratteri di output su disco
LDA#$45
JSR CHROUT
; Chiudi il file logico
LDA#$40
JSR CHIUSO
Per leggere un byte dal disco nel registro µP Y, ripetere il programma precedente con le seguenti modifiche: Invece di “JSR CHKOUT ; per scrivere”, utilizzare “JSR CHKIN ; per leggere'. Sostituisci il segmento di codice per “; Output char to disk” con quanto segue:
; Inserisci il carattere dal disco
JSR CHRIS
Si accede alla routine OS CHRIN saltando (JSR) alla tabella di salto della ROM del sistema operativo in $FFCF. Questa routine, quando chiamata, prende un byte da un canale che è già impostato come canale di ingresso e lo inserisce nel registro µP A. La routine GETIN ROM OS può essere utilizzata anche al posto di CHRIN.
Invio di un byte alla stampante
L'invio di un byte alla stampante avviene in modo simile all'invio di un byte a un file sul disco.
5.8 La routine di salvataggio del sistema operativo
È possibile accedere alla routine OS SAVE saltando (JSR) alla tabella di salto della ROM del sistema operativo in $FFD8. La routine OS SAVE nella ROM salva (scarica) una sezione della memoria sul disco come file (con un nome). È necessario conoscere l'indirizzo iniziale della sezione di memoria. Deve essere noto anche l'indirizzo finale della sezione. Il byte più basso dell'indirizzo iniziale viene inserito nella pagina zero nella RAM all'indirizzo $ 002B. Il byte più alto dell'indirizzo iniziale viene inserito nella posizione di memoria del byte successivo all'indirizzo $002C. Nella pagina zero, l'etichetta TXTTAB si riferisce a questi due indirizzi, sebbene TXTTAB in realtà significhi l'indirizzo $002B. Il byte più basso dell'indirizzo finale viene inserito nel registro µP X. Il byte più alto dell'indirizzo finale più 1 viene inserito nel registro µP Y. Il registro µP A assume il valore di $2B per TXTTAB ($002B). Con ciò, la routine SAVE può essere chiamata con quanto segue:
SALVATAGGIO JSR
La sezione di memoria da salvare può essere un programma in linguaggio assembly oppure un documento. Un esempio di documento può essere una lettera o un saggio. Per utilizzare la routine di salvataggio, è necessario seguire la seguente procedura:
- Imposta il canale utilizzando la routine SETLFS.
- Impostare il nome del file logico (numero) che è uguale a quello del file del disco effettivo utilizzando la routine SETNAM.
- Aprire il file logico utilizzando la routine OPEN.
- Crea un file per l'output utilizzando CHKOUT.
- Qui va il codice per salvare il file che termina con “JSR SAVE”.
- Chiudere il file logico utilizzando la routine CLOSE.
Il seguente programma salva un file che inizia dalle locazioni di memoria da $C101 a $C200:
; Canale di impostazione
LDA#$40; numero di file logico
LDX #$08 ; numero di dispositivo per la prima unità disco
LDY #$02 ; indirizzo secondario
JSR SETLFS ; impostare il canale correttamente
;
; Nome del file nell'unità disco (già in memoria in $C301)
LDA#$09; lunghezza del nome del file
LDX #$01
LDY #$C3
JSR SETNAM
; Apri file logico
JSR APERTO
; Imposta il canale per l'uscita
LDX#$40; numero di file logico
JSRCHKOUT ; per scrivere
;
; File di output su disco
LDA #$01
STA $ 2 miliardi; TXTTAB
LDA #$C1
ST$2C
LDX #$00
LDY#$C2
LDA #$2B
SALVATAGGIO JSR
; Chiudi il file logico
LDA#$40
JSR CHIUSO
Si noti che questo è un programma che salva un'altra sezione della memoria (non la sezione del programma) su disco (dischetto per Commodore-64).
5.9 La routine di CARICAMENTO DEL SO
È possibile accedere alla routine OS LOAD saltando (JSR) alla tabella di salto della ROM del sistema operativo su $FFD5. Quando una sezione (ampia area) della memoria viene salvata sul disco, viene salvata con un'intestazione che contiene l'indirizzo iniziale della sezione nella memoria. La subroutine OS LOAD carica i byte di un file nella memoria. Con questa operazione LOAD, il valore dell'accumulatore deve essere 010 ($00). Affinché l'operazione LOAD legga l'indirizzo iniziale nell'intestazione del file nel disco e inserisca i byte del file nella RAM a partire da quell'indirizzo, l'indirizzo secondario del canale deve essere 1 o 2 (il seguente programma utilizza 2). Questa routine restituisce l'indirizzo più 1 della posizione RAM più alta caricata. Ciò significa che il byte basso dell'ultimo indirizzo del file in RAM più 1 viene messo nel registro µP X, e il byte alto dell'ultimo indirizzo del file in RAM più 1 viene messo nel registro µP Y.
Se il caricamento non riesce, il registro µP A contiene il numero di errore (possibilmente 4, 5, 8 o 9). Viene impostato anche il flag C del registro di stato del microprocessore (reso 1). Se il caricamento ha esito positivo, l'ultimo valore del registro A non è importante.
Ora, nel capitolo precedente di questo corso carriera online, la prima istruzione del programma in linguaggio assembly si trova all'indirizzo nella RAM in cui è iniziato il programma. Non deve essere così. Ciò significa che la prima istruzione di un programma non deve trovarsi all'inizio del programma nella RAM. L'istruzione di avvio di un programma può trovarsi in qualsiasi punto del file nella RAM. Si consiglia al programmatore di etichettare l'istruzione di avvio in linguaggio assembly con START. Detto questo, dopo che il programma è stato caricato, viene eseguito nuovamente (eseguito) con la seguente istruzione in linguaggio assembly:
INIZIO JSR
'JSR START' si trova nel programma in linguaggio assembly che carica il programma da eseguire. Un linguaggio assembly che carica un altro file di linguaggio assembly ed esegue il file caricato ha la seguente procedura di codice:
- Impostare il canale utilizzando la routine SETLFS.
- Impostare il nome del file logico (numero) che è uguale a quello del file del disco effettivo utilizzando la routine SETNAM.
- Aprire il file logico utilizzando la routine OPEN.
- Rendilo il file per l'input utilizzando CHKIN.
- Il codice per caricare il file va qui e termina con “JSR LOAD”.
- Chiudere il file logico utilizzando la routine CLOSE.
Il seguente programma carica un file dal disco e lo esegue:
; Canale di impostazione
LDA#$40; numero di file logico
LDX #$08 ; numero di dispositivo per la prima unità disco
LDY #$02 ; indirizzo secondario
JSR SETLFS ; impostare il canale correttamente
;
; Nome del file nell'unità disco (già in memoria in $C301)
LDA#$09; lunghezza del nome del file
LDX #$01
LDY#$C3
JSR SETNAM
; Apri file logico
JSR APERTO
; Imposta il canale per l'ingresso
LDX#$40; numero di file logico
JSRCHKIN; per leggere
;
; File di input dal disco
LDA #$00
CARICO JSR
; Chiudi il file logico
LDA#$40
JSR CHIUSO
; Avvia il programma caricato
INIZIO JSR
5.10 Il modem e lo standard RS-232
Il modem è un dispositivo (periferico) che converte i bit provenienti dal computer nei corrispondenti segnali audio elettrici da trasmettere sulla linea telefonica. All'estremità ricevente c'è un modem prima del computer ricevente. Questo secondo modem converte i segnali audio elettrici in bit per il computer ricevente.
Un modem deve essere collegato a un computer tramite una porta esterna (sulla superficie verticale del computer). Lo standard RS-232 si riferisce ad un particolare tipo di connettore che collegava un modem al computer (in passato). In altre parole, molti computer in passato avevano una porta esterna che era un connettore RS-232 o un connettore compatibile con RS-232.
L'unità di sistema Commodore-64 (computer) ha una porta esterna sulla superficie verticale posteriore chiamata porta utente. Questa porta utente è compatibile con RS-232. Qui è possibile collegare un dispositivo modem. Il Commodore-64 comunica con un modem attraverso questa porta utente. Il sistema operativo ROM del Commodore-64 dispone di subroutine per comunicare con un modem chiamate routine RS-232. Queste routine hanno voci nella tabella di salto.
Velocità di trasmissione
Il byte da otto bit proveniente dal computer viene convertito in una serie di otto bit prima di essere inviato al modem. Dal modem al computer avviene il contrario. La velocità di trasmissione è il numero di bit trasmessi al secondo, in serie.
Il fondo della memoria
Il termine 'bottom of memory' non si riferisce alla posizione del byte di memoria dell'indirizzo $0000. Si riferisce alla posizione RAM più bassa in cui l'utente può iniziare a inserire i propri dati e programmi. Per impostazione predefinita, è $ 0800. Ricordiamo dalla discussione precedente che molte posizioni tra $ 0800 e $ BFFF sono utilizzate dal linguaggio informatico BASIC e dai suoi programmatori (utenti). Solo le posizioni degli indirizzi da $ C000 a $ CFFF vengono lasciate da utilizzare per i programmi e i dati in linguaggio assembly; si tratta di 4Kbyte dei 64 Kbyte di memoria.
La parte superiore della memoria
A quei tempi, quando i clienti acquistavano i computer Commodore-64, alcuni non venivano forniti con tutte le posizioni di memoria. Tali computer avevano ROM con il relativo sistema operativo da $ E000 a $ FFFF. Avevano RAM da $ 0000 fino a un limite, che non è $ DFFF, vicino a $ E000. Il limite era inferiore a $DFFF e tale limite è chiamato 'Top of Memory'. Pertanto, la parte superiore della memoria non si riferisce alla posizione $FFFF.
Buffer Commodore-64 per la comunicazione RS-232
Buffer di trasmissione
Il buffer per la trasmissione RS-232 (uscita) occupa 256 byte dalla parte superiore della memoria verso il basso. Il puntatore per questo buffer di trasmissione è etichettato come ROBUF. Questo puntatore si trova nella pagina zero con gli indirizzi $00F9 seguiti da $00FA. ROBUF identifica effettivamente $00F9. Quindi, se l'indirizzo per l'inizio del buffer è $BE00, il byte più basso di $BE00, che è $00, è nella posizione $00F9 e il byte più alto di $BE00, che è $BE, è in $00FA posizione.
Buffer di ricezione
Il buffer per ricevere i byte RS-232 (input) occupa 256 byte dal fondo del buffer di trasmissione. Il puntatore per questo buffer di ricezione è etichettato come RIBUF. Questo puntatore si trova nella pagina zero con gli indirizzi $00F7 seguiti da $00F8. RIBUF identifica effettivamente $00F7. Quindi, se l'indirizzo per l'inizio del buffer è $BF00, il byte più basso di $BF00, che è $00, si trova nella posizione $00F7 e il byte più alto di $BF00, che è $BF, è nella posizione $00F8 posizione. Pertanto, 512 byte dalla parte superiore della memoria vengono utilizzati come buffer RAM RS-232 totale.
Canale RS-232
Quando un modem è collegato alla porta utente (esterna), la comunicazione con il modem è solo comunicazione RS-232. La procedura per avere un canale RS-232 completo è quasi la stessa della discussione precedente, ma con un'importante differenza: il nome del file è un codice e non una stringa in memoria. Il codice $0610 è una buona scelta. Significa una velocità di trasmissione di 300 bit/sec e alcuni altri parametri tecnici. Inoltre, non esiste un indirizzo secondario. Tieni presente che il numero del dispositivo è 2. La procedura per impostare un canale RS-232 completo è:
- Impostazione del canale utilizzando la routine SETLFS.
- Impostando il nome del file logico, $0610.
- Apertura del file logico utilizzando la routine OPEN.
- Rendendolo il file per l'output utilizzando CHKOUT o il file per l'input utilizzando CHKIN.
- Invio dei singoli byte con CHROUT o ricezione dei singoli byte con GETIN.
- Chiusura del file logico utilizzando la routine CLOSE.
È possibile accedere alla routine OS GETIN saltando (JSR) alla tabella di salto della ROM del sistema operativo in $FFE4. Questa routine, quando viene chiamata, prende il byte inviato nel buffer del ricevitore e lo inserisce (restituito) nell'accumulatore µP.
Il seguente programma invia il byte 'E' (ASCII) al modem collegato alla porta compatibile RS-232 dell'utente:
; Canale di impostazione
LDA#$40; numero di file logico
LDX #$02 ; numero del dispositivo per RS-232
LDY #$FF ; nessun indirizzo secondario
JSR SETLFS ; impostare il canale correttamente
;
; Il nome per RS-232 è un codice, ad es. $ 0610
LDA#$02; la lunghezza del codice è 2 byte
LDX#$10
LDY #$06
JSR SETNAM
;
; Apri file logico
JSR APERTO
; Imposta il canale per l'uscita
LDX#$40; numero di file logico
JSR CHKOUT
;
; Caratteri di uscita su RS-232 ad es. modem
LDA#$45
JSR CHROUT
; Chiudi il file logico
LDA#$40
JSR CHIUSO
Per ricevere un byte, il codice è molto simile, tranne che “JSR CHKOUT” è sostituito da “JSR CHKIN” e:
LDA#$45
JSR CHROUT
viene sostituito da 'JSR GETIN' e il risultato viene inserito nel registro A.
L'invio o la ricezione continua di byte viene eseguita rispettivamente da un ciclo per l'invio o la ricezione del segmento di codice.
Si noti che l'input e l'output con il Commodore sono simili per la maggior parte dei casi, ad eccezione della tastiera dove alcune routine non vengono chiamate dal programmatore, ma vengono chiamate dal sistema operativo.
5.11 Conteggio e cronometraggio
Considera la sequenza di conto alla rovescia che è:
2, 1, 0
Questo è il conto alla rovescia da 2 a 0. Ora, considera la sequenza ripetuta del conto alla rovescia:
2, 1, 0, 2, 1, 0, 2, 1, 0, 2, 1, 0
Questo è il conto alla rovescia ripetuto della stessa sequenza. La sequenza viene ripetuta quattro volte. Quattro volte significa che il tempo è 4. All'interno di una sequenza si conta. Ripetere la stessa sequenza è cronometrare.
Ci sono due adattatori di interfaccia complessi nell'unità di sistema del Commodore-64. Ogni CIA ha due circuiti contatore/timer denominati Timer A (TA) e Timer B (TB). Il circuito di conteggio non è diverso dal circuito di temporizzazione. Il contatore o timer del Commodore-64 si riferisce alla stessa cosa. In effetti, entrambi si riferiscono essenzialmente a un registro a 16 bit che conta sempre fino a 0 sugli impulsi di clock del sistema. È possibile impostare valori diversi nel registro a 16 bit. Maggiore è il valore, maggiore è il tempo necessario per il conto alla rovescia fino a zero. Ogni volta che uno dei timer supera lo zero, il IRQ il segnale di interruzione viene inviato al microprocessore. Quando il conteggio scende oltre lo zero, si parla di underflow.
A seconda di come è programmato il circuito del timer, un timer può funzionare in modalità singola o continua. Nell'illustrazione precedente, la modalità una tantum significa 'fai 2, 1, 0' e fermati mentre gli impulsi dell'orologio continuano. La modalità continua è come “2, 1, 0, 2, 1, 0, 2, 1, 0, 2, 1, 0, ecc.” che continua con gli impulsi dell'orologio. Ciò significa che quando supera lo zero, se non viene data alcuna istruzione, la sequenza del conto alla rovescia si ripete. Il numero più grande è solitamente molto più grande di 2.
Viene generato il timer A (TA) della CIA #1 IRQ a intervalli regolari (durate) per effettuare la manutenzione della tastiera. In realtà, questo è in realtà ogni 1/60 di secondo per impostazione predefinita. IRQ viene inviato al microprocessore ogni 1/60 di secondo. È solo quando IRQ viene inviato che un programma può leggere il valore di una chiave dalla coda della tastiera (buffer). Ricordare che il microprocessore ha un solo pin per il IRQ segnale. Il microprocessore ha anche un solo pin per il NMI segnale. Il segnale ¯NMI al microprocessore proviene sempre da CIA #2.
Il registro del timer a 16 bit ha due indirizzi di memoria: uno per il byte più basso e uno per il byte più alto. Ogni CIA ha due circuiti timer. Le due CIA sono identiche. Per CIA #1, gli indirizzi per i due timer sono: DC04 e DC05 per TA e DC06 e DC07 per TB. Per CIA #2, gli indirizzi per i due timer sono: DD04 e DD05 per TA e DD06 e DD07 per TB.
Supponiamo che il numero 25510 debba essere inviato al timer TA della CIA n. 2 per il conto alla rovescia. 25510 = 00000000111111112 è in sedici bit. 00000000111111112 = $000FFF è in formato esadecimale. In questo caso, $FF viene inviato al registro all'indirizzo $DD04 e $00 viene inviato al registro all'indirizzo $DD05 – little endianness. Il seguente segmento di codice invia il numero al registro:
LDA #$FF
STATO $GG04
LDA #$00
STATO $GG05
Sebbene i registri in una CIA abbiano indirizzi RAM, sono fisicamente nella CIA e la CIA è un IC separato dalla RAM o dalla ROM.
Ma non è tutto! Quando al timer è stato assegnato un numero per il conto alla rovescia, come nel caso del codice precedente, il conto alla rovescia non si avvia. Il conteggio alla rovescia inizia quando un byte di otto bit è stato inviato al registro di controllo corrispondente per il timer. Il primo bit di questo byte per il registro di controllo indica se deve iniziare o meno il conto alla rovescia. Un valore pari a 0 per questo primo bit significa interrompere il conto alla rovescia, mentre un valore pari a 1 significa iniziare il conto alla rovescia. Inoltre, il byte deve indicare se il conto alla rovescia è in modalità one shot (una tantum) o in modalità free running (modalità continua). La modalità One-shot esegue il conto alla rovescia e si arresta quando il valore del registro del timer diventa zero. Con la modalità di esecuzione libera, il conto alla rovescia si ripete dopo aver raggiunto lo 0. Il quarto bit (indice 3) del byte inviato al registro di controllo indica la modalità: 0 significa modalità di esecuzione libera e 1 significa modalità one-shot.
Un numero adatto per iniziare a contare in modalità one shot è 000010012 = $09 in formato esadecimale. Un numero adatto per iniziare a contare in modalità esecuzione libera è 000000012 = $01 in formato esadecimale. Ogni registro del timer ha il proprio registro di controllo. In CIA #1, il registro di controllo per il timer A ha l'indirizzo RAM di DC0E16 e il registro di controllo per il timer B ha l'indirizzo RAM di DC0F16. In CIA #2, il registro di controllo per il timer A ha l'indirizzo RAM di DD0E16 e il registro di controllo per il timer B ha l'indirizzo RAM di DD0F16. Per iniziare il conto alla rovescia del numero a sedici bit in TA di CIA #2, in modalità one-shot, utilizzare il seguente codice:
LDA #$09
STA $DD0E
Per iniziare il conto alla rovescia del numero a sedici bit in TA di CIA #2, in modalità esecuzione libera, utilizzare il seguente codice:
LDA #$01
STA $DD0E
5.12 Il IRQ E NMI Richieste
Il microprocessore 6502 ha il IRQ E NMI linee (perni). Sia la CIA #1 che la CIA #2 hanno ciascuna il file IRQ pin per il microprocessore. IL IRQ il pin di CIA #2 è collegato a NMI pin del µP. IL IRQ il pin di CIA #1 è collegato a IRQ pin del µP. Queste sono le uniche due linee di interruzione che collegano il microprocessore. Così il IRQ il pin della CIA n. 2 è il NMI sorgente e può anche essere vista come la linea ¯NMI.
CIA #1 ha cinque possibili fonti immediate per generare il file IRQ segnale per il µP. La CIA #2 ha la stessa struttura della CIA #1. Quindi, la CIA n. 2 ha le stesse cinque possibili fonti immediate per generare il segnale di interruzione questa volta, ovvero NMI segnale. Ricorda che quando il µP riceve il NMI segnale, se sta gestendo il IRQ richiesta, la sospende e gestisce la richiesta NMI richiesta. Quando finisce di gestire il file NMI richiesta, riprende quindi la gestione del file IRQ richiesta.
CIA #1 è normalmente collegato esternamente alla tastiera e ad un dispositivo di gioco come un joystick. La tastiera utilizza più la porta A di CIA #1 che la porta B. Il dispositivo di gioco utilizza più porta B di CIA #1 che la sua porta A. CIA #2 è normalmente collegato esternamente all'unità disco (collegato a catena alla stampante) e il modem. L'unità disco utilizza più porta A di CIA #2 (tramite la porta seriale esterna) rispetto alla porta B. Il modem (RS-232) utilizza più porta B di CIA #2 rispetto alla porta A.
Detto questo, come fa l'unità di sistema a sapere cosa causa il IRQ O NMI interrompere? La CIA n. 1 e la CIA n. 2 hanno cinque fonti immediate di interruzione. Se il segnale di interruzione al µP è NMI , la fonte è una delle cinque fonti più immediate della CIA n.2. Se il segnale di interruzione al µP è IRQ , la fonte è una delle cinque fonti più immediate della CIA n. 1.
La domanda successiva è: “In che modo l’unità di sistema distingue tra le cinque fonti immediate di ciascuna CIA?” Ogni CIA ha un registro a otto bit chiamato Interrupt Control Register (ICR). L'ICR serve entrambi i porti della CIA. La tabella seguente mostra il significato degli otto bit del registro di controllo degli interrupt, a partire dal bit 0:
| Tabella 5.13 Registro di controllo degli interrupt |
|
|---|---|
| Indice dei bit | Senso |
| 0 | Impostato (effettuato 1) per underflow del timer A |
| 1 | Impostato tramite underflow del timer B |
| 2 | Impostato quando l'ora del giorno corrisponde alla sveglia |
| 3 | Impostato quando la porta seriale è piena |
| 4 | Impostato tramite dispositivo esterno |
| 5 | Non utilizzato (prodotto 0) |
| 6 | Non utilizzato (prodotto 0) |
| 7 | Impostato quando è impostato uno qualsiasi dei primi cinque bit |
Come si vede dalla tabella, ciascuna delle sorgenti immediate è rappresentata da uno dei primi cinque bit. Pertanto, quando il segnale di interruzione viene ricevuto al µP, è necessario eseguire il codice per leggere il contenuto del registro di controllo dell'interruzione per conoscere l'esatta fonte dell'interruzione. L'indirizzo RAM per l'ICR di CIA #1 è DC0D16. L'indirizzo RAM per l'ICR di CIA #2 è DD0D16. Per leggere (restituire) il contenuto dell'ICR di CIA #1 all'accumulatore µP, digitare la seguente istruzione:
LDA$DC0D
Per leggere (restituire) il contenuto dell'ICR di CIA #2 all'accumulatore µP, digitare la seguente istruzione:
LDA$GG0D
5.13 Programma in background basato su interrupt
La tastiera normalmente interrompe il microprocessore ogni 1/60 di secondo. Immagina che un programma sia in esecuzione e raggiunga la posizione di attendere un tasto dalla tastiera prima di poter continuare con i segmenti di codice seguenti. Supponiamo che se non viene premuto alcun tasto dalla tastiera, il programma esegue solo un piccolo ciclo, in attesa di un tasto. Immagina che il programma sia in esecuzione e si aspetti semplicemente un tasto dalla tastiera subito dopo l'emissione dell'interruzione della tastiera. A quel punto, l'intero computer si ferma indirettamente e non sta facendo altro che il ciclo di attesa. Immagina che un tasto della tastiera venga premuto appena prima del prossimo numero della successiva interruzione della tastiera. Ciò significa che il computer non ha fatto nulla per circa un sessantesimo di secondo! È molto tempo perché un computer non faccia nulla, anche ai tempi del Commodore-64. Il computer avrebbe potuto fare qualcos'altro in quel lasso di tempo (durata). Ci sono molte di queste durate in un programma.
È possibile scrivere un secondo programma in modo che funzioni durante tali periodi di 'inattività'. Si dice che un programma di questo tipo operi sullo sfondo del programma principale (o primo). Un modo semplice per farlo è semplicemente forzare una gestione dell'interruzione BRK modificata quando è previsto un tasto dalla tastiera.
Puntatore per l'istruzione BRK
Nelle posizioni consecutive della RAM degli indirizzi $0316 e $0317 si trova il puntatore (vettore) per l'effettiva routine di istruzioni BRK. Il puntatore predefinito viene inserito in questa posizione quando il computer viene acceso dal sistema operativo nella ROM. Questo puntatore predefinito è un indirizzo che punta ancora al gestore di istruzioni BRK predefinito nella ROM del sistema operativo. Il puntatore è un indirizzo a 16 bit. Il byte più basso del puntatore viene inserito nella posizione del byte dell'indirizzo $0306, mentre il byte più alto del puntatore viene inserito nella posizione del byte $0317.
È possibile scrivere un secondo programma in modo tale che quando il sistema è “inattivo”, alcuni codici del secondo programma vengano eseguiti dal sistema. Ciò significa che il secondo programma deve essere composto da subroutine. Quando il sistema è “inattivo”, ovvero in attesa di un tasto dalla tastiera, viene eseguita una subroutine successiva per il secondo programma. L’interazione umana con il computer è lenta rispetto al funzionamento dell’unità di sistema.
È semplice risolvere questo problema: ogni volta che il computer deve attendere un tasto dalla tastiera, inserire un'istruzione BRK nel codice e sostituire il puntatore a $0316 (e $0317) con il puntatore della subroutine successiva del secondo ( personalizzato). In questo modo, entrambi i programmi verrebbero eseguiti per una durata non molto più lunga di quella del programma principale che viene eseguito da solo.
5.14 Assemblaggio e Compilazione
L'assemblatore sostituisce tutte le etichette con indirizzi. Un programma in linguaggio assembly viene normalmente scritto per iniziare da un indirizzo particolare. Il risultato dell'assemblatore (dopo l'assemblaggio) è chiamato 'codice oggetto' con tutto in binario. Il risultato è il file eseguibile se il file è un programma e non un documento. Un documento non è eseguibile.
Un'applicazione è composta da più di un programma (linguaggio assembly). Di solito c'è un programma principale. La situazione qui non deve essere confusa con la situazione dei programmi in background guidati da interruzioni. Tutti i programmi qui sono programmi in primo piano, ma esiste un primo programma o programma principale.
È necessario un compilatore al posto dell'assemblatore quando sono presenti più programmi in primo piano. Il compilatore assembla ciascuno dei programmi in un codice oggetto. Ci sarebbe però un problema: alcuni segmenti di codice si sovrapporrebbero perché probabilmente i programmi sono scritti da persone diverse. La soluzione del compilatore è spostare tutti i programmi sovrapposti tranne il primo nello spazio di memoria, in modo che i programmi non si sovrappongano. Ora, quando si tratta di memorizzare le variabili, alcuni indirizzi di variabili continuerebbero a sovrapporsi. La soluzione in questo caso è sostituire gli indirizzi sovrapposti con i nuovi indirizzi (ad eccezione del primo programma) in modo che non si sovrappongano più. In questo modo i diversi programmi entreranno nelle diverse porzioni (aree) della memoria.
Con tutto ciò, è possibile che una routine in un programma richiami una routine in un altro programma. Quindi, il compilatore esegue il collegamento. Il collegamento si riferisce all'avere l'indirizzo iniziale di una subroutine in un programma e quindi richiamarlo in un altro programma; entrambi fanno parte dell'applicazione. Entrambi i programmi devono utilizzare lo stesso indirizzo a questo scopo. Il risultato finale è un grande codice oggetto con tutto in binario (bit).
5.15 Salvataggio, caricamento ed esecuzione di un programma
Un linguaggio assembly è normalmente scritto in qualche programma editor (che può essere fornito con il programma assembler). Il programma editor indica dove inizia e finisce il programma nella memoria (RAM). La routine Kernal SAVE della OS ROM del Commodore-64 può salvare un programma in memoria sul disco. Scarica semplicemente la sezione (blocco) della memoria che può contenere la chiamata di istruzione sul disco. È consigliabile avere l'istruzione di chiamata a SAVE, separata dal programma che si sta salvando, in modo che quando il programma viene caricato in memoria dal disco, non si salvi nuovamente quando viene eseguito. Il caricamento di un programma in linguaggio assembly dal disco è un tipo di sfida diverso perché un programma non può caricarsi da solo.
Un programma non può caricarsi dal disco al punto in cui inizia e finisce nella RAM. Il Commodore-64 a quei tempi veniva normalmente fornito con un interprete BASIC per eseguire i programmi in linguaggio BASIC. Quando la macchina (computer) viene accesa, si sistema con il prompt dei comandi: PRONTO. Da lì, i comandi o le istruzioni BASIC possono essere digitati premendo il tasto 'Invio' dopo aver digitato. Il comando BASIC (istruzione) per caricare un file è:
CARICA “nome file”,8,1
Il comando inizia con la parola riservata BASIC che è LOAD. Questo è seguito da uno spazio e quindi dal nome del file tra virgolette doppie. Segue il numero del dispositivo 8, preceduto da una virgola. Viene seguito l'indirizzo secondario del disco che è 1, preceduto da una virgola. Con un file di questo tipo, l'indirizzo iniziale del programma in linguaggio assembly si trova nell'intestazione del file sul disco. Quando il BASIC termina di caricare il programma, viene restituito l'ultimo indirizzo RAM più 1 del programma. La parola 'restituito' qui significa che il byte più basso dell'ultimo indirizzo più 1 viene inserito nel registro µP X e il byte più alto dell'ultimo indirizzo più 1 viene inserito nel registro µP Y.
Dopo aver caricato il programma, è necessario eseguirlo (eseguirlo). L'utente del programma deve conoscere l'indirizzo iniziale per l'esecuzione in memoria. Anche in questo caso è necessario un altro programma BASIC. È il comando SYS. Dopo aver eseguito il comando SYS, il programma in linguaggio assembly verrà eseguito (e arrestato). Durante l'esecuzione, se è necessario un input dalla tastiera, il programma in linguaggio assembly dovrebbe indicarlo all'utente. Dopo che l'utente ha digitato i dati sulla tastiera e premuto il tasto 'Invio', il programma in linguaggio assembly continuerà a funzionare utilizzando l'immissione da tastiera senza interferenze da parte dell'interprete BASIC.
Supponendo che l'inizio dell'indirizzo RAM di esecuzione (in esecuzione) per il programma in linguaggio assembly sia C12316, C123 viene convertito in base dieci prima di utilizzarlo con il comando SYS. La conversione di C12316 in base dieci è la seguente:
Quindi, il comando BASIC SYS è:
SIST 49443
5.16 Avvio per Commodore-64
L'avvio del Commodore-64 consiste di due fasi: la fase di ripristino dell'hardware e la fase di inizializzazione del sistema operativo. Il sistema operativo è il Kernal nella ROM (e non in un disco). C'è una linea di ripristino (in realtà RES ) che si collega a un pin a 6502 µP e allo stesso nome pin in tutte le navi speciali come CIA 1, CIA 2 e VIC II. Nella fase di reset, grazie a questa linea, tutti i registri nel µP e nei chip speciali vengono resettati a 0 (reso zero per ogni bit). Successivamente, tramite l'hardware del microprocessore, allo stack pointer e al registro di stato del processore vengono assegnati i loro valori iniziali nel microprocessore. Al contatore del programma viene quindi assegnato il valore (indirizzo) nelle posizioni $FFFC e $FFFD. Ricordiamo che il contatore del programma contiene l'indirizzo dell'istruzione successiva. Il contenuto (indirizzo) conservato qui è per la subroutine che avvia l'inizializzazione del software. Tutto finora è fatto dall'hardware del microprocessore. In questa fase l'intera memoria non viene toccata. Inizia quindi la fase successiva di inizializzazione.
L'inizializzazione viene eseguita da alcune routine nel sistema operativo ROM. Inizializzare significa dare i valori iniziali o di default ad alcuni registri nei chip speciali. L'inizializzazione inizia dando i valori iniziali o di default ad alcuni registri negli appositi chip. IRQ , ad esempio, deve iniziare ad emettere ogni 1/60 di secondo. Pertanto, il timer corrispondente in CIA #1 deve essere impostato sul valore predefinito.
Successivamente, il Kernal esegue un test della RAM. Testa ogni posizione inviando un byte alla posizione e rileggendolo. Se c'è una differenza, almeno quella posizione è pessima. Kernal identifica inoltre la parte superiore e inferiore della memoria e imposta i puntatori corrispondenti nella pagina 2. Se la parte superiore della memoria è $DFFF, $FF viene inserito nella posizione $0283 e $DF viene inserito nella posizione byte $0284. Sia $ 0283 che $ 0284 hanno l'etichetta HIRAM. Se la parte inferiore della memoria è $0800, $00 viene inserito nella posizione $0281 e $08 viene inserito nella posizione $0282. Sia $ 0281 che $ 0282 hanno l'etichetta LORAM. Il test della RAM in realtà inizia da $ 0300 fino al limite massimo della memoria (RAM).
Infine, i vettori di ingresso/uscita (puntatori) vengono impostati sui valori predefiniti. Il test della RAM in realtà inizia da $ 0300 fino al limite massimo della memoria (RAM). Ciò significa che la pagina 0, la pagina 1 e la pagina 2 sono inizializzate. La pagina 0, in particolare, ha molti puntatori alla ROM del sistema operativo e la pagina 2 ha molti puntatori BASIC. Questi puntatori vengono definiti variabili. Ricorda che la pagina 1 è lo stack. I puntatori vengono definiti variabili perché hanno nomi (etichette). A questo punto la memoria dello schermo (monitor) viene cancellata. Ciò significa inviare il codice di $20 per lo spazio (che sembra essere lo stesso di ASCII $20) alle 1000 posizioni dello schermo RAM. Infine, il Kernal avvia l'interprete BASIC per visualizzare il prompt dei comandi BASIC che è PRONTO nella parte superiore del monitor (schermo).
5.17 Problemi
Si consiglia al lettore di risolvere tutti i problemi in un capitolo prima di passare al capitolo successivo.
- Scrivi un codice in linguaggio assembly che renda tutti i bit della porta A CIA n. 2 come output e la porta B CIA n. 2 come input.
- Scrivere un codice linguaggio assembly 6502 che attende un tasto della tastiera finché non viene premuto.
- Scrivere un programma in linguaggio assembly 6502 che invii il carattere 'E' allo schermo del Commodore-64.
- Scrivere un programma in linguaggio assembly 6502 che prenda un carattere dalla tastiera e lo invii allo schermo del Commodore-64, ignorando il codice chiave e la temporizzazione.
- Scrivere un programma in linguaggio assembly 6502 che riceva un byte dal dischetto Commodore-64.
- Scrivere un programma in linguaggio assembly 6502 che salvi un file sul dischetto del Commodore-64.
- Scrivere un programma in linguaggio assembly 6502 che carichi un file di programma dal dischetto del Commodore-64 e lo avvii.
- Scrivere un programma in linguaggio assembly 6502 che invii il byte 'E' (ASCII) al modem collegato alla porta utente RS-232 compatibile del Commodore-64.
- Spiegare come vengono eseguiti il conteggio e il cronometraggio nel computer Commodore-64.
- Spiegare come l'unità di sistema Commodore-64 può identificare 10 diverse fonti di richiesta di interruzione immediata comprese le richieste di interruzione non mascherabili.
- Spiegare come un programma in background può essere eseguito con un programma in primo piano nel computer Commodore-64.
- Spiegare brevemente come i programmi in linguaggio assembly possono essere compilati in un'unica applicazione per il computer Commodore-64.
- Spiegare brevemente il processo di avvio del computer Commodore-64.