Il multiprocessing è paragonabile al multithreading. Tuttavia, si differenzia in quanto possiamo eseguire solo un thread alla volta a causa del GIL utilizzato per il threading. Il multiprocessing è il processo di esecuzione di operazioni in sequenza su diversi core della CPU. I thread non possono essere gestiti in parallelo. Tuttavia, il multiprocessing ci consente di stabilire i processi ed eseguirli contemporaneamente su vari core della CPU. Il ciclo, come il ciclo for, è uno dei linguaggi di scripting più utilizzati. Ripeti lo stesso lavoro utilizzando vari dati fino a quando non viene raggiunto un criterio, come un numero predeterminato di iterazioni. Il ciclo esegue ogni iterazione una per una.
Esempio 1: utilizzo del ciclo For nel modulo di multielaborazione Python
In questo esempio, usiamo il ciclo for e il processo della classe del modulo multiprocessore Python. Iniziamo con un esempio molto semplice in modo che tu possa capire rapidamente come funziona il ciclo for multiprocessing di Python. Utilizzando un'interfaccia paragonabile al modulo threading, il multiprocessing impacchetta la creazione di processi.
Impiegando i sottoprocessi piuttosto che i thread, il pacchetto multiprocessing fornisce la concorrenza sia locale che distante, evitando così il Global Interpreter Lock. Usa un ciclo for, che può essere un oggetto stringa o una tupla, per scorrere continuamente una sequenza. Questo funziona meno come la parola chiave vista in altri linguaggi di programmazione e più come un metodo iteratore trovato in altri linguaggi di programmazione. Avviando una nuova multielaborazione, è possibile eseguire un ciclo for che esegue una procedura contemporaneamente.
Iniziamo implementando il codice per l'esecuzione del codice utilizzando lo strumento 'spyder'. Riteniamo che 'spyder' sia anche il migliore per eseguire Python. Importiamo un processo del modulo multiprocessing che il codice sta eseguendo. Il multiprocessing nel concetto Python definito 'classe di processo' crea un nuovo processo Python, gli fornisce un metodo per eseguire il codice e offre all'applicazione padre un modo per gestire l'esecuzione. La classe Process contiene le procedure start() e join(), entrambe cruciali.
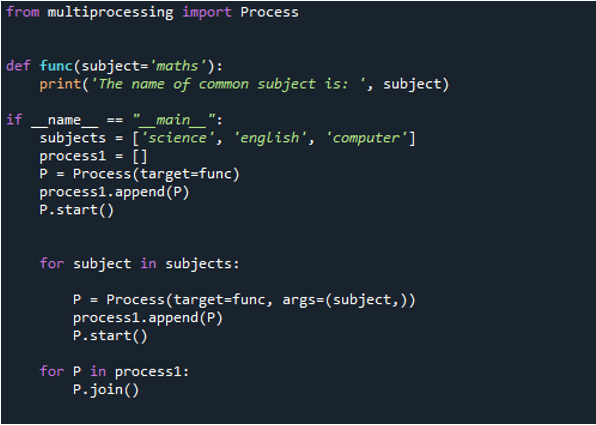
Successivamente, definiamo una funzione definita dall'utente chiamata 'func'. Poiché si tratta di una funzione definita dall'utente, le diamo un nome a nostra scelta. All'interno del corpo di questa funzione, passiamo la variabile “subject” come argomento e il valore “maths”. Successivamente, chiamiamo la funzione 'print()', passando l'istruzione 'Il nome del soggetto comune è' così come il suo argomento 'soggetto' che contiene il valore. Quindi, nel passaggio successivo, utilizziamo 'if name== _main_', che ti impedisce di eseguire il codice quando il file viene importato come modulo e ti consente di farlo solo quando il contenuto viene eseguito come script.
La sezione delle condizioni con cui inizi può essere considerata nella maggior parte dei casi come una posizione per fornire il contenuto che dovrebbe essere eseguito solo quando il tuo file viene eseguito come script. Quindi, usiamo il soggetto dell'argomento e memorizziamo alcuni valori in esso che sono 'scienza', 'inglese' e 'computer'. Al processo viene quindi assegnato il nome 'process1[]' nel passaggio successivo. Quindi, usiamo 'process(target=func)' per chiamare la funzione nel processo. Target viene utilizzato per chiamare la funzione e salviamo questo processo nella variabile 'P'.
Successivamente, usiamo 'process1' per chiamare la funzione 'append()' che aggiunge un elemento alla fine dell'elenco che abbiamo nella funzione 'func'. Poiché il processo è memorizzato nella variabile 'P', passiamo 'P' a questa funzione come suo argomento. Infine, usiamo la funzione 'start ()' con 'P' per avviare il processo. Successivamente, eseguiamo nuovamente il metodo fornendo l'argomento 'soggetto' e usiamo 'for' nell'oggetto. Quindi, utilizzando ancora una volta 'process1' e il metodo 'add ()', iniziamo il processo. Il processo quindi viene eseguito e viene restituito l'output. Alla procedura viene quindi detto di terminare utilizzando la tecnica 'join ()'. I processi che non chiamano la procedura 'join()' non verranno chiusi. Un punto cruciale è che il parametro della parola chiave 'args' deve essere utilizzato se si desidera fornire argomenti durante il processo.
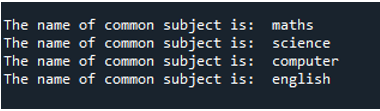
Ora, puoi vedere nell'output che l'istruzione viene visualizzata per prima passando il valore per l'oggetto 'matematica' che passiamo nella funzione 'func' perché prima lo chiamiamo usando la funzione 'process'. Quindi, usiamo il comando 'append ()' per avere valori che erano già nell'elenco che viene aggiunto alla fine. Quindi sono stati presentati 'scienza', 'computer' e 'inglese'. Ma, come puoi vedere, i valori non sono nella sequenza corretta. Questo perché lo fanno non appena la procedura è terminata e segnalano il loro messaggio.
Esempio 2: conversione di un ciclo For sequenziale in un ciclo For parallelo multielaborazione
In questo esempio, l'attività del ciclo multiprocessore viene eseguita in sequenza prima di essere convertita in un'attività del ciclo for parallela. Puoi scorrere sequenze come una raccolta o una stringa nell'ordine in cui si verificano utilizzando i cicli for.
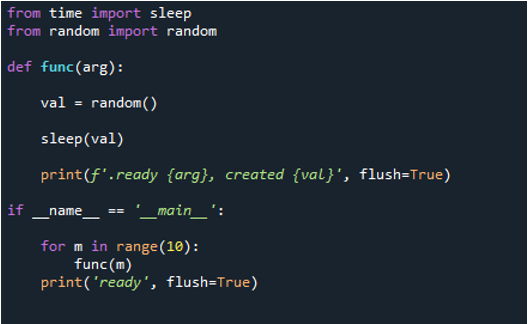
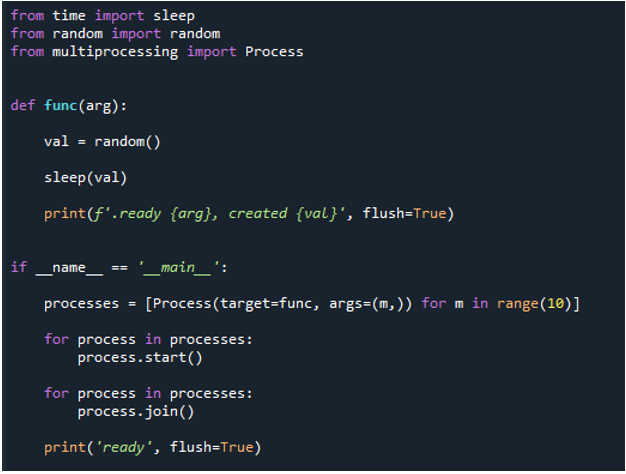
Ora, iniziamo a implementare il codice. Per prima cosa, importiamo 'sleep' dal modulo time. Utilizzando la procedura 'sleep()' nel modulo time, puoi sospendere l'esecuzione del thread chiamante per tutto il tempo che desideri. Quindi, usiamo 'random' dal modulo random, definiamo una funzione con il nome 'func' e passiamo la parola chiave 'argu'. Quindi, creiamo un valore casuale usando 'val' e lo impostiamo su 'random'. Quindi, blocchiamo per un breve periodo utilizzando il metodo 'sleep()' e passiamo 'val' come parametro. Quindi, per trasmettere un messaggio, eseguiamo il metodo 'print ()', passando le parole 'ready' e la parola chiave 'arg' come parametro, nonché 'created' e passiamo il valore utilizzando 'val'.
Infine, utilizziamo 'flush' e lo impostiamo su 'True'. L'utente può decidere se bufferizzare o meno l'output usando l'opzione flush nella funzione print di Python. Il valore predefinito di questo parametro, False, indica che l'output non verrà memorizzato nel buffer. L'output viene visualizzato come una serie di righe che si susseguono se lo si imposta su true. Quindi, usiamo 'if name== main' per proteggere i punti di ingresso. Successivamente, eseguiamo il lavoro in sequenza. Qui impostiamo l'intervallo su '10', il che significa che il ciclo termina dopo 10 iterazioni. Successivamente, chiamiamo la funzione 'print()', le passiamo l'istruzione di input 'ready' e usiamo l'opzione 'flush=True'.
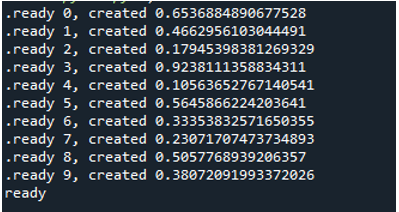
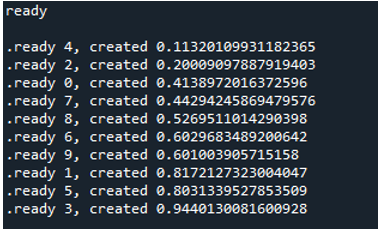
Ora puoi vedere che quando eseguiamo il codice, il ciclo fa sì che la funzione venga eseguita '10' volte. Itera 10 volte, partendo dall'indice zero e terminando con l'indice nove. Ogni messaggio contiene un numero di attività che è un numero di funzione che passiamo come 'arg' e un numero di creazione.
Questo ciclo sequenziale viene ora trasformato in un ciclo for parallelo multiprocessing. Usiamo lo stesso codice, ma andiamo ad alcune librerie e funzioni extra per il multiprocessing. Pertanto, dobbiamo importare il processo dal multiprocessing, proprio come abbiamo spiegato in precedenza. Successivamente, creiamo una funzione chiamata 'func' e passiamo la parola chiave 'arg' prima di utilizzare 'val=random' per ottenere un numero casuale.
Quindi, dopo aver invocato il metodo 'print()' per mostrare un messaggio e dato il parametro 'val' per ritardare un po' di tempo, utilizziamo la funzione 'if name= main' per proteggere i punti di ingresso. Dopodiché, creiamo un processo e chiamiamo la funzione nel processo usando 'process' e passiamo 'target=func'. Quindi, passiamo 'func', 'arg', passiamo il valore 'm' e passiamo l'intervallo '10', il che significa che il ciclo termina la funzione dopo '10' iterazioni. Quindi, avviamo il processo utilizzando il metodo 'start()' con 'process'. Quindi, chiamiamo il metodo 'join ()' per attendere l'esecuzione del processo e per completare tutto il processo successivo.
Pertanto, quando eseguiamo il codice, le funzioni chiamano il processo principale e iniziano la loro esecuzione. Tuttavia, vengono completati fino a quando tutti i compiti non vengono completati. Possiamo vederlo perché ogni attività viene eseguita contemporaneamente. Segnala il suo messaggio non appena è finito. Ciò significa che sebbene i messaggi siano fuori servizio, il ciclo termina dopo che tutte le '10' iterazioni sono state completate.
Conclusione
In questo articolo abbiamo coperto il ciclo for multiprocessing di Python. Abbiamo anche presentato due illustrazioni. La prima illustrazione mostra come utilizzare un ciclo for nella libreria multiprocessore di loop di Python. E la seconda illustrazione mostra come modificare un ciclo for sequenziale in un ciclo for multiprocessing parallelo. Prima di costruire lo script per il multiprocessing Python, dobbiamo importare il modulo multiprocessing.