In qualità di amministratori di database, dobbiamo essere ossessionati dagli strumenti e dai metodi per migliorare le prestazioni del database.
In PostgreSQL, abbiamo accesso al comando EXPLAIN ANALYZE che ci consente di analizzare il piano di esecuzione e le prestazioni di una determinata query del database. Il comando restituisce informazioni dettagliate su come il motore di database elabora la query. Ciò include la sequenza delle operazioni eseguite, i costi di query stimati, i tempi di esecuzione e altro ancora.
Possiamo quindi utilizzare queste informazioni per identificare le query del database, nonché identificare e correggere i potenziali colli di bottiglia delle prestazioni.
Questo tutorial illustra come utilizzare il comando EXPLAIN ANALYZE in PostgreSQL per visualizzare e ottimizzare le prestazioni delle query.
PostgreSQL SPIEGARE ANALIZZARE
Il comando è piuttosto semplice. Innanzitutto, dobbiamo anteporre il comando EXPLAIN ANALYZE all'inizio della query che desideriamo analizzare.
La sintassi del comando è la seguente:
SPIEGARE ANALIZZAUna volta eseguito il comando, PostgreSQL restituisce un output dettagliato sulla query fornita.
Comprensione dell'output della query EXPLAIN ANALYZE
Come accennato, una volta eseguito il comando EXPLAIN ANALYZE, PostgreSQL genera un report dettagliato del piano di query e delle statistiche di esecuzione.
L'output è costituito da una serie di colonne che contengono informazioni utili. Le colonne risultanti sono come mostrato con il loro rispettivo significato:
PIANO DI INTERROGAZIONE – Questa colonna visualizza il piano di esecuzione della query specificata. Il piano di esecuzione fa riferimento a una sequenza di operazioni eseguite dal motore di database per completare correttamente la query.
PIANO – La seconda colonna è la colonna PIANO. Contiene una rappresentazione testuale di ciascuna operazione o fase del piano di esecuzione. Anche in questo caso, ogni operazione è rientrata per indicare la gerarchia delle operazioni.
COSTO TOTALE – La colonna del costo totale rappresenta il costo totale stimato della query. Il costo si riferisce a una misura relativa che il pianificatore di query del database utilizza per determinare il piano di esecuzione ottimale.
RIGHE REALI – Questa colonna mostra il numero esatto di righe che vengono elaborate in ogni fase dell'esecuzione della query.
TEMPO REALE – Questa colonna mostra il tempo effettivo impiegato da ciascuna operazione che include sia il tempo di esecuzione dell'operazione sia il tempo speso per le risorse.
TEMPO DI PIANIFICAZIONE – Questa colonna mostra il tempo impiegato dal pianificatore di query per generare un piano di esecuzione. Ciò include il tempo totale dell'ottimizzazione della query e la generazione del piano.
TEMPO DI ESECUZIONE – Questa colonna mostra il tempo totale per eseguire la query. Ciò include anche il tempo impiegato per la pianificazione e il tempo di esecuzione delle query.
PostgreSQL SPIEGARE ANALIZZARE Esempio
Diamo un'occhiata ad alcuni esempi di base dell'utilizzo dell'istruzione EXPLAIN ANALYZE.
Esempio 1: Select Statement
Usiamo l'istruzione EXPLAIN ANALYZE per mostrare l'esecuzione di una semplice istruzione select in PostgreSQL.
Una volta eseguita l'istruzione precedente, dovremmo ottenere un output come segue:
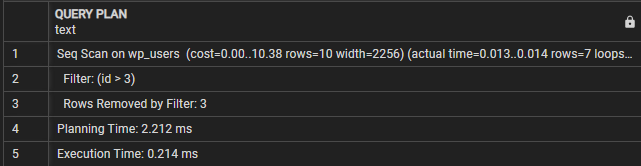
PIANO DI INTERROGAZIONE-------------------------------------------------- -----------------
Scansione sequenziale su wp_users (costo=0,00..10,38 righe=10 larghezza=2256) (tempo effettivo=0,009..0,010 righe=7 cicli=1)
Filtro: (id > 3)
Righe rimosse dal filtro: 3
Tempo di pianificazione: 0,995 ms
Tempo di esecuzione: 0,021 ms
(5 file)
In questo caso, possiamo vedere che la sezione Query plan indica che la query esegue una scansione sequenziale sulla tabella wp_users. La riga del filtro indica la condizione utilizzata per filtrare le righe risultanti.
Vediamo quindi 'Righe rimosse dal filtro' che mostra il numero di righe eliminate dalla condizione del filtro.
Infine, il tempo di esecuzione mostra il tempo totale di esecuzione della query. In questo caso, la query richiede 0,021 ms.
Esempio 2: analisi di un join
Prendiamo una query più complessa che coinvolge un join SQL. Per questo, utilizziamo il database di esempio Pagila. È possibile scaricare e installare il database di esempio sul computer a scopo dimostrativo.
Possiamo eseguire un semplice join come mostrato di seguito:
spiegare analizzare SELEZIONA f.titolo, c.nomeDAL film f
ISCRIVITI a film_category fc ON f.film_id = fc.film_id
UNISCITI alla categoria c ON fc.category_id = c.category_id;
Una volta eseguita la query data, dovremmo vedere l'output come segue:
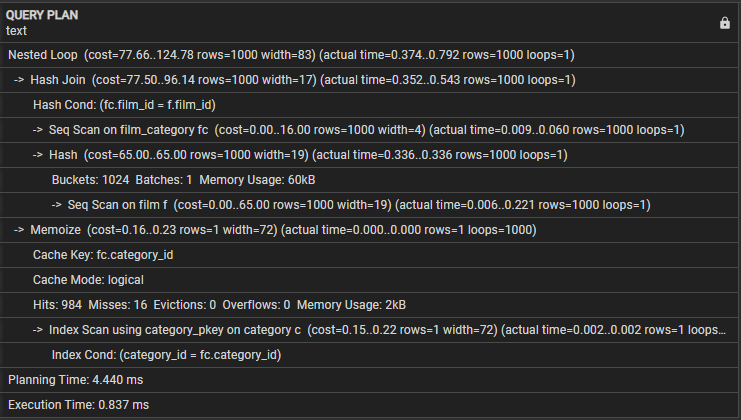
Esploriamo il seguente piano di query:
- Ciclo annidato: indica che il join utilizza una strategia di join a ciclo annidato.
- Hash Join: questa operazione unisce le tabelle film_category e film utilizzando un algoritmo Hash join. Questa operazione ha un costo di 77,50 e una stima di 1000 righe. Tuttavia, il tempo effettivo impiegato per questa operazione è compreso tra 0,254 e 0,439 millisecondi e recupera 1000 righe.
- Hash Cond: indica che la condizione di join utilizza un hash join per abbinare le colonne film_id e le colonne film_category nelle tabelle film.
- Seq Scan on film_category – Questa operazione esegue una scansione sequenziale sulla tabella film_category con un costo di 16.00 e una stima di 1000 righe. Il tempo effettivo impiegato per questa operazione è compreso tra 0,008 e 0,056 millisecondi e recupera 1000 righe.
- Scansione sequenziale su pellicola: la query esegue una scansione sequenziale sul tavolo della pellicola con i costi e le righe stimati ed effettivi risultanti in questa operazione.
- Memoize: questa operazione memorizza nella cache i risultati dell'unione tra le tabelle film_category e film per un uso successivo.
- Chiave cache: indica che la chiave cache utilizzata per la memoizzazione si basa sulla colonna category_id di film_category.
- Modalità cache: indica che la query utilizza la modalità cache logica.
- Hit, Misses, Evictions, Overflow: le tre righe forniscono statistiche sulla cache, il numero di hit, miss, espulsioni e overflow durante l'esecuzione. Questo blocco include anche l'utilizzo della memoria durante l'esecuzione della query.
- Index Scan using category_pkey: mostra l'operazione che esegue una scansione dell'indice sulla tabella delle categorie utilizzando l'indice della chiave primaria.
- Index Cond: mostra che la scansione dell'indice si basa sulla condizione che corrisponde alla colonna category_id nella tabella delle categorie.
- Tempo di pianificazione: questa riga mostra il tempo impiegato per la pianificazione della query, pari a 3,005 millisecondi.
- Tempo di esecuzione: infine, questa riga mostra il tempo di esecuzione totale della query che è di 0,745 millisecondi.
Ecco qua! Informazioni dettagliate sull'esecuzione di un semplice join in PostgreSQL.
Conclusione
Hai scoperto la potenza e l'utilizzo dell'istruzione EXPLAIN ANALYZE in PostgreSQL. L'istruzione EXPLAIN ANALYZE è un potente strumento per l'analisi e l'ottimizzazione delle query. Utilizza questo strumento per creare query efficienti e meno dispendiose in termini di risorse.