Come utilizzare la dichiarazione del caso Pandas?
Le istruzioni del caso possono essere create in diversi modi. La funzione NumPy where(), che utilizza la seguente sintassi fondamentale, è il modo più semplice per costruire un'istruzione case in un DataFrame Pandas:
df [ 'nome colonna' ] = np.dove ( condizione 1 , 'valore1',np.dove ( condizione Due , 'valore2',
np.dove ( condizione 3 , 'valore3', 'valore4' ) ) )
L'istruzione precedente verificherà ogni condizione per il valore e, se la condizione è soddisfatta, genererà l'output o restituirà il valore rispetto alla condizione.
Esempio n. 1: istruzione Pandas Case utilizzando la funzione where()
Creiamo prima un frame di dati in modo da poter utilizzare la nostra istruzione case. Per creare il frame di dati, importeremo prima i moduli numpy e pandas in modo da poter utilizzare le loro funzionalità. Il pd.Dataframe() verrà utilizzato per creare il nostro frame di dati.

Abbiamo creato il data frame 'df'. Un dizionario Python viene passato all'interno delle funzioni pd.DataFrame() come argomento con chiavi e valori. Useremo la funzione print() per vedere il nostro frame di dati.
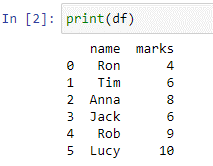
Nel data frame 'df' abbiamo due colonne “name” e “marks” con valori ['Ron', 'Tim', 'Anna', 'Jack', 'Rob', 'Lucy'] e [4, 6 , 8, 6, 9,10] rispettivamente. Supponiamo che il nome sia la colonna che memorizza i nomi degli studenti e la colonna 'voti' memorizza il punteggio di alcuni test recenti. Ora scriveremo un'istruzione case che aggiunge una nuova colonna denominata 'remarks' i cui valori sono basati sui valori da noi specificati, per ciascuna condizione.

Il metodo 'numpy.where()' fornisce gli indici degli elementi da un array, una colonna o un elenco di input che soddisfano la condizione specificata. Nel caso di switch sopra, la funzione np.where() controlla ogni elemento nelle colonne 'marks'. Se il valore è uguale o inferiore a 5, restituirà 'fallito' come output. Se il valore è inferiore o uguale a 7, restituirà soddisfacente e se il valore è inferiore o uguale a 9, restituirà 'ottimo'. Se non ce ne sono, il risultato sarà eccellente.
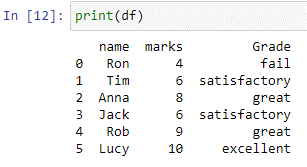
Come si può notare, la nuova colonna 'remarks' viene creata nel nostro data frame 'df', memorizzando i valori restituiti dall'istruzione case sopra.
Esempio n. 2:
Proviamo di nuovo l'istruzione case precedente con un frame di dati diverso. Supponiamo di dover valutare i giocatori in base ai loro goal totali nel torneo di calcio precedente. Quindi creiamo un frame di dati per memorizzare i record dei giocatori di football.
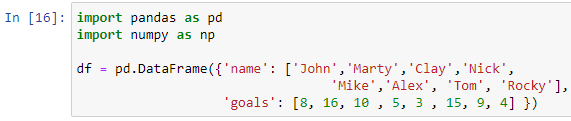
Abbiamo passato un dizionario con le chiavi 'nome' e 'obiettivi' all'interno della funzione pd.DataFrame() per creare il nostro frame di dati. Per stampare il nostro frame di dati, utilizzeremo la funzione di stampa.
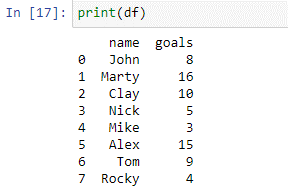
Come si può vedere nel frame di dati sopra, abbiamo due colonne: 'nome' e 'obiettivi'. Nel nome della colonna abbiamo i nomi dei giocatori ['John', 'Marty', 'Clay', 'Nick', 'Mike', 'Alex', 'Tom', 'Rocky']. Nella 'colonna' goal, abbiamo il numero totale di goal segnati da ciascun giocatore nel torneo precedente. Ora useremo la nostra dichiarazione del caso per valutare questi giocatori in base ai gol che hanno segnato.

Il caso precedente viene creato utilizzando la funzione where(). All'interno del caso, la funzione di istruzione controlla ogni elemento nelle colonne 'segni' rispetto alle condizioni. Se il valore nella colonna 'obiettivi' è uguale o inferiore a 5, restituirà 'C'. Se il valore nella colonna 'obiettivi' è uguale o inferiore a 9, restituirà 'B'. Restituirà una 'A' se il valore nella colonna 'obiettivi' è uguale o maggiore di 10. I valori restituiti dall'istruzione verranno archiviati nella nuova colonna 'valutazione'. Stampiamo il 'df' per vedere i risultati.
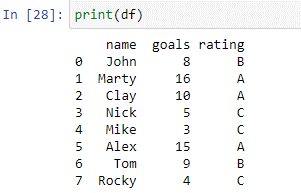
La nuova colonna 'rating' è stata creata correttamente utilizzando lo script sopra.
Esempio n. 3: Istruzione if-else di Pandas che utilizza la funzione apply()
L'asse di riga o colonna del frame di dati viene utilizzato dal metodo apply() per implementare una funzione. Possiamo creare la nostra funzione definita e usarla nel nostro frame di dati nei panda. Comprenderà le condizioni if-else. Creiamo prima il nostro frame di dati, quindi creeremo una funzione in cui useremo un'istruzione if-else per generare il risultato. Per creare il nostro data frame, importeremo prima il modulo dei panda, quindi passeremo un dizionario all'interno del metodo pd.DataFrame().
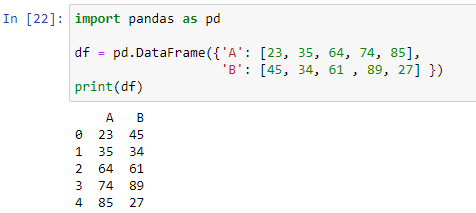
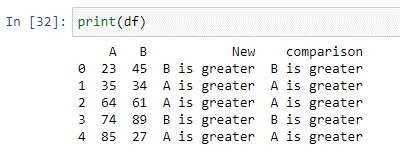
Come si può vedere, il nostro data frame è composto da due colonne 'A' che memorizzano valori numerici [23, 35, 64, 74, 85] e 'B' con valori [45, 34, 61, 89, 27]. Ora creeremo una funzione che determinerà quale valore è maggiore tra entrambe le colonne in ogni riga del nostro frame di dati.
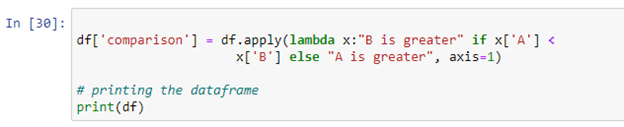
Puoi usare la funzione lambda di Python 'pandas. DataFrame.apply()' per eseguire un'espressione. In Python, una funzione lambda è una funzione anonima compatta che accetta un numero qualsiasi di argomenti ed esegue un'espressione. Nello script precedente, abbiamo creato un'istruzione di condizione che confronterà il valore di entrambe le colonne e memorizzerà il risultato nella nuova colonna 'confronto'. Se il valore della colonna 'A' è inferiore al valore della colonna 'B', restituirà 'B è maggiore'. Se la condizione non è soddisfatta restituirà 'A è maggiore'.
Esempio n. 4:
Proviamo un altro esempio usando l'istruzione if-else all'interno della funzione apply() con un altro frame di dati.
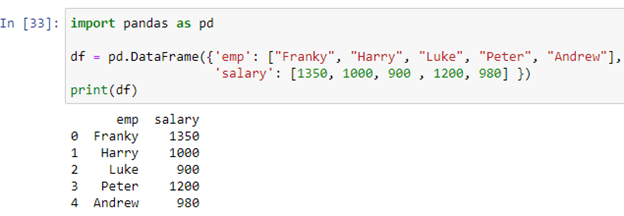
Supponiamo che il nostro data frame memorizzi i record dei dipendenti di qualche azienda. La colonna 'emp' memorizza i nomi dei dipendenti [“Franky”, “Harry”, “Luke”, “Peter”, “Andrew”], mentre la colonna 'stipendio' memorizza gli stipendi di ciascun dipendente [1350, 1000, 900 , 1200, 980] nel frame di dati 'df'. Ora creeremo la nostra istruzione if-else usando il metodo apply().

La condizione di cui sopra verificherà ogni valore nella colonna 'stipendio' e aggiungerà 200 agli stipendi dei dipendenti in cui il valore dello stipendio è inferiore o uguale a 1000. Abbiamo archiviato i valori restituiti dalla funzione apply() nella nuova colonna ' incremento'. Vediamo i risultati dello script sopra.
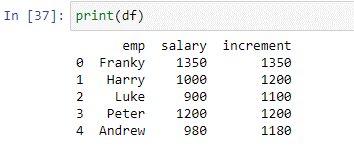
Come puoi vedere, la funzione ha aggiunto con successo 200 ai valori che erano inferiori o uguali a 100. I valori che erano maggiori di 1000 sono rimasti invariati.
Conclusione:
In questo tutorial, abbiamo visto che quando la condizione è soddisfatta, un'istruzione di questo tipo, chiamata istruzione case, restituisce un valore. Abbiamo visto come creare un'istruzione case per eseguire un'operazione o un'attività richiesta. In questo tutorial, abbiamo utilizzato la funzione np.where() e la funzione apply() per creare istruzioni case. Abbiamo implementato alcuni esempi per insegnarti come usare le istruzioni case dei panda usando la funzione where() e come usare la funzione apply() per creare le istruzioni case.