Ottimizzazione del codice Python con strumenti di profilazione
Configurando Google Colab per ottimizzare il codice Python con strumenti di profilazione, iniziamo configurando un ambiente Google Colab. Se siamo nuovi a Colab, si tratta di una piattaforma essenziale e potente basata su cloud che fornisce l'accesso ai notebook Jupyter e a una gamma di librerie Python. Accediamo a Colab visitando (https://colab.research.google.com/) e creando un nuovo notebook Python.
Importa le librerie di profilazione
La nostra ottimizzazione si basa sull'uso competente delle librerie di profilazione. Due librerie importanti in questo contesto sono cProfile e line_profiler.
importare cProfilo
importare line_profiler
La libreria “cProfile” è uno strumento Python integrato per la profilazione del codice, mentre “line_profiler” è un pacchetto esterno che ci permette di andare ancora più in profondità, analizzando il codice riga per riga.
In questo passaggio creiamo uno script Python di esempio per calcolare la sequenza di Fibonacci utilizzando una funzione ricorsiva. Analizziamo questo processo in modo più approfondito. La sequenza di Fibonacci è un insieme di numeri in cui ogni numero successivo è la somma dei due precedenti. Di solito inizia con 0 e 1, quindi la sequenza è 0, 1, 1, 2, 3, 5, 8, 13, 21 e così via. È una sequenza matematica che viene comunemente utilizzata come esempio nella programmazione a causa della sua natura ricorsiva.
Definiamo una funzione Python chiamata “Fibonacci” nella funzione ricorsiva di Fibonacci. Questa funzione prende come argomento un numero intero “n”, che rappresenta la posizione nella sequenza di Fibonacci che vogliamo calcolare. Vogliamo individuare il quinto numero nella sequenza di Fibonacci, ad esempio, se 'n' è uguale a 5.
def fibonacci ( N ) :
Successivamente, stabiliamo un caso base. Un caso base in ricorsione è uno scenario che termina le chiamate e restituisce un valore predeterminato. Nella sequenza di Fibonacci, quando “n” è 0 o 1, conosciamo già il risultato. Lo 0° e il 1° numero di Fibonacci sono rispettivamente 0 e 1.
Se N <= 1 :ritorno N
Questa istruzione 'if' determina se 'n' è minore o uguale a 1. Se lo è, restituiamo 'n' stesso, poiché non è necessaria ulteriore ricorsione.
Calcolo ricorsivo
Se “n” è maggiore di 1 si procede con il calcolo ricorsivo. In questo caso, dobbiamo trovare l’“n”-esimo numero di Fibonacci sommando i numeri di Fibonacci “(n-1)” e “(n-2)”esimo. Otteniamo questo risultato effettuando due chiamate ricorsive all'interno della funzione.
altro :ritorno fibonacci ( N - 1 ) + Fibonacci ( N - 2 )
Qui, “fibonacci(n – 1)” calcola il “(n-1)”esimo numero di Fibonacci e “fibonacci(n – 2)” calcola il “(n-2)”esimo numero di Fibonacci. Sommiamo questi due valori per ottenere il numero di Fibonacci desiderato nella posizione 'n'.
In sintesi, questa funzione “fibonacci” calcola ricorsivamente i numeri di Fibonacci suddividendo il problema in sottoproblemi più piccoli. Effettua chiamate ricorsive fino a raggiungere i casi base (0 o 1), restituendo valori noti. Per qualsiasi altro “n”, calcola il numero di Fibonacci sommando i risultati di due chiamate ricorsive per “(n-1)” e “(n-2)”.
Sebbene questa implementazione sia semplice per calcolare i numeri di Fibonacci, non è la più efficiente. Nei passaggi successivi, utilizzeremo gli strumenti di profilazione per identificare e ottimizzare le limitazioni prestazionali per tempi di esecuzione migliori.
Profilazione del codice con CProfile
Ora profiliamo la nostra funzione “fibonacci” utilizzando “cProfile”. Questo esercizio di profilazione fornisce informazioni dettagliate sul tempo impiegato da ciascuna chiamata di funzione.
cprofiler = cProfilo. Profilo ( )cprofiler. abilitare ( )
risultato = fibonacci ( 30 )
cprofiler. disattivare ( )
cprofiler. print_stats ( ordinare = 'cumulativo' )
In questo segmento inizializziamo un oggetto “cProfile”, attiviamo la profilazione, richiediamo la funzione “fibonacci” con “n=30”, disattiviamo la profilazione e visualizziamo le statistiche ordinate per tempo cumulativo. Questa profilazione iniziale ci offre una panoramica di alto livello di quali funzioni consumano più tempo.
! pip installa line_profilerimportare cProfilo
importare line_profiler
def fibonacci ( N ) :
Se N <= 1 :
ritorno N
altro :
ritorno fibonacci ( N - 1 ) + Fibonacci ( N - 2 )
cprofiler = cProfilo. Profilo ( )
cprofiler. abilitare ( )
risultato = fibonacci ( 30 )
cprofiler. disattivare ( )
cprofiler. print_stats ( ordinare = 'cumulativo' )
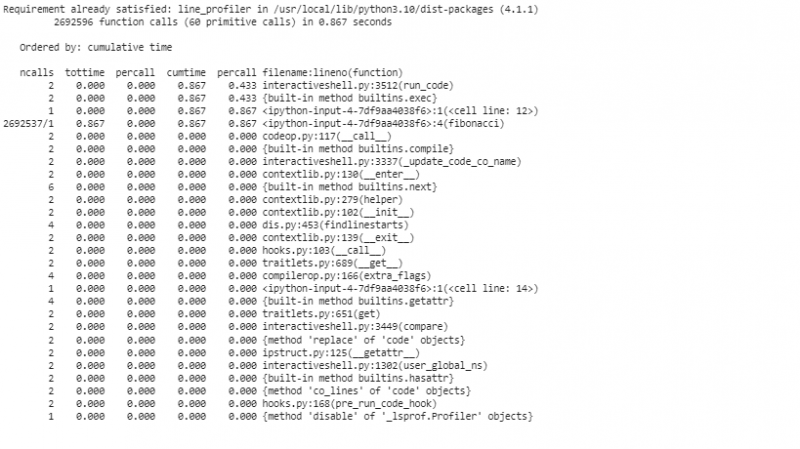
Per profilare il codice riga per riga con line_profiler per un'analisi più dettagliata, utilizziamo il “line_profiler” per segmentare il nostro codice riga per riga. Prima di utilizzare 'line_profiler', dobbiamo installare il pacchetto nel repository Colab.
! pip installa line_profilerOra che abbiamo il “line_profiler” pronto, possiamo applicarlo alla nostra funzione “fibonacci”:
%load_ext line_profilerdef fibonacci ( N ) :
Se N <= 1 :
ritorno N
altro :
ritorno fibonacci ( N - 1 ) + Fibonacci ( N - 2 )
%lprun -f fibonacci fibonacci ( 30 )
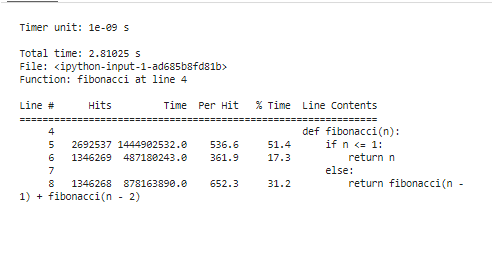
Questo snippet inizia caricando l'estensione “line_profiler”, definisce la nostra funzione “fibonacci” e infine utilizza “%lprun” per profilare la funzione “fibonacci” con “n=30”. Offre una segmentazione riga per riga dei tempi di esecuzione, chiarendo con precisione dove il nostro codice spende le sue risorse.
Dopo aver eseguito gli strumenti di profilazione per analizzare i risultati, verrà presentata una serie di statistiche che mostrano le caratteristiche prestazionali del nostro codice. Queste statistiche riguardano il tempo totale impiegato all'interno di ciascuna funzione e la durata di ciascuna riga di codice. Ad esempio, possiamo distinguere che la funzione Fibonacci investe un po' più di tempo ricalcolando più volte gli stessi valori. Questo è il calcolo ridondante ed è un'area chiara in cui è possibile applicare l'ottimizzazione, tramite la memorizzazione o impiegando algoritmi iterativi.
Ora effettuiamo ottimizzazioni laddove abbiamo identificato una potenziale ottimizzazione nella nostra funzione di Fibonacci. Abbiamo notato che la funzione ricalcola più volte gli stessi numeri di Fibonacci, con conseguente ridondanza non necessaria e tempi di esecuzione più lenti.
Per ottimizzare questo, implementiamo la memorizzazione. La memorizzazione è una tecnica di ottimizzazione che prevede la memorizzazione dei risultati calcolati in precedenza (in questo caso i numeri di Fibonacci) e il loro riutilizzo quando necessario invece di ricalcolarli. Ciò riduce i calcoli ridondanti e migliora le prestazioni, soprattutto per funzioni ricorsive come la sequenza di Fibonacci.
Per implementare la memorizzazione nella nostra funzione Fibonacci, scriviamo il seguente codice:
# Dizionario per memorizzare i numeri di Fibonacci calcolatifib_cache = { }
def fibonacci ( N ) :
Se N <= 1 :
ritorno N
# Controlla se il risultato è già memorizzato nella cache
Se N In fib_cache:
ritorno fib_cache [ N ]
altro :
# Calcola e memorizza nella cache il risultato
fib_cache [ N ] = fibonacci ( N - 1 ) + Fibonacci ( N - 2 )
ritorno fib_cache [ N ] ,
In questa versione modificata della funzione “fibonacci”, introduciamo un dizionario “fib_cache” per memorizzare i numeri di Fibonacci precedentemente calcolati. Prima di calcolare un numero di Fibonacci, controlliamo se è già nella cache. Se lo è, restituiamo il risultato memorizzato nella cache. In ogni altro caso, lo calcoliamo, lo teniamo nella cache e poi lo restituiamo.
Ripetendo la profilazione e l'ottimizzazione
Dopo aver implementato l'ottimizzazione (memoizzazione nel nostro caso), è fondamentale ripetere il processo di profilazione per conoscere l'impatto delle nostre modifiche e garantire di aver migliorato le prestazioni del codice.
Profilazione dopo l'ottimizzazione
Possiamo utilizzare gli stessi strumenti di profilazione, “cProfile” e “line_profiler”, per profilare la funzione di Fibonacci ottimizzata. Confrontando i risultati della nuova profilazione con quelli precedenti, possiamo misurare l'efficacia della nostra ottimizzazione.
Ecco come possiamo profilare la funzione “fibonacci” ottimizzata utilizzando “cProfile”:
cprofiler = cProfilo. Profilo ( )cprofiler. abilitare ( )
risultato = fibonacci ( 30 )
cprofiler. disattivare ( )
cprofiler. print_stats ( ordinare = 'cumulativo' )
Utilizzando il “line_profiler”, lo profiliamo riga per riga:
%lprun -f fibonacci fibonacci ( 30 )Codice:
# Dizionario per memorizzare i numeri di Fibonacci calcolatifib_cache = { }
def fibonacci ( N ) :
Se N <= 1 :
ritorno N
# Controlla se il risultato è già memorizzato nella cache
Se N In fib_cache:
ritorno fib_cache [ N ]
altro :
# Calcola e memorizza nella cache il risultato
fib_cache [ N ] = fibonacci ( N - 1 ) + Fibonacci ( N - 2 )
ritorno fib_cache [ N ]
cprofiler = cProfilo. Profilo ( )
cprofiler. abilitare ( )
risultato = fibonacci ( 30 )
cprofiler. disattivare ( )
cprofiler. print_stats ( ordinare = 'cumulativo' )
%lprun -f fibonacci fibonacci ( 30 )
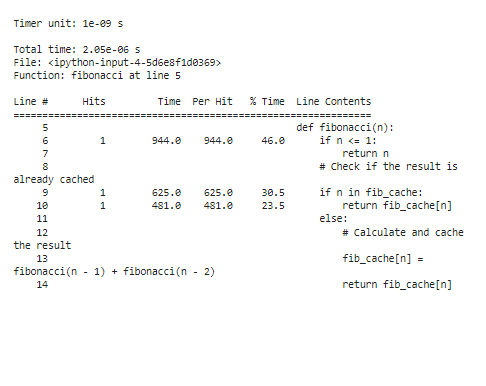
Per analizzare i risultati della profilazione post-ottimizzazione, i tempi di esecuzione saranno significativamente ridotti, soprattutto per valori “n” grandi. Grazie alla memorizzazione, osserviamo che la funzione ora impiega molto meno tempo a ricalcolare i numeri di Fibonacci.
Questi passaggi sono essenziali nel processo di ottimizzazione. L'ottimizzazione implica apportare modifiche informate al nostro codice in base alle osservazioni ottenute dalla profilazione, mentre la ripetizione della profilazione garantisce che le nostre ottimizzazioni producano i miglioramenti delle prestazioni attesi. Attraverso la profilazione, l'ottimizzazione e la convalida iterative, possiamo mettere a punto il nostro codice Python per offrire prestazioni migliori e migliorare l'esperienza utente delle nostre applicazioni.
Conclusione
In questo articolo abbiamo discusso l'esempio in cui abbiamo ottimizzato il codice Python utilizzando strumenti di profilazione all'interno dell'ambiente Google Colab. Abbiamo inizializzato l'esempio con il setup, importato le librerie di profilazione essenziali, scritto i codici di esempio, profilato utilizzando sia 'cProfile' che 'line_profiler', calcolato i risultati, applicato le ottimizzazioni e perfezionato in modo iterativo le prestazioni del codice.