Questo articolo fornisce istruzioni per l'implementazione del tiering intelligente per ottimizzare i costi nel bucket S3.
Cos'è il tiering intelligente nel bucket S3?
I dati stanno crescendo in modo esponenziale in tutto il mondo. Ad alcuni di questi dati si accede quotidianamente mentre il resto è richiesto solo occasionalmente. Poiché S3 è uno dei servizi più popolari di AWS per l'archiviazione dei dati, AWS ha introdotto una classe di archiviazione nota come “Tiering intelligente” per tagliare la spesa di S3 a causa dell'archiviazione dei dati. Scopri di più sulle diverse classi di storage dei bucket S3 facendo riferimento a questo articolo: 'Una panoramica delle diverse classi di storage su S3' .
Intelligent-Tiering può ottimizzare la spesa S3 monitorando i modelli di accesso ai dati. Questa funzionalità è sufficientemente efficiente per determinare a quali dati si accede frequentemente o occasionalmente. Sulla base di questi modelli, li identifica e li colloca automaticamente nel livello più conveniente senza costi operativi o riduzioni delle prestazioni.
Come ottimizzare i costi di archiviazione dei dati in Amazon S3 con il tiering intelligente?
A seconda dei modelli di accesso ai dati, gli oggetti a cui si accede raramente verranno inseriti nel file livello di accesso a costo inferiore a fini di costo ottimale. Se l'utente accede all'oggetto, verrà automaticamente e immediatamente spostato nuovamente nel file Livello di accesso frequente per disponibilità senza costi aggiuntivi:
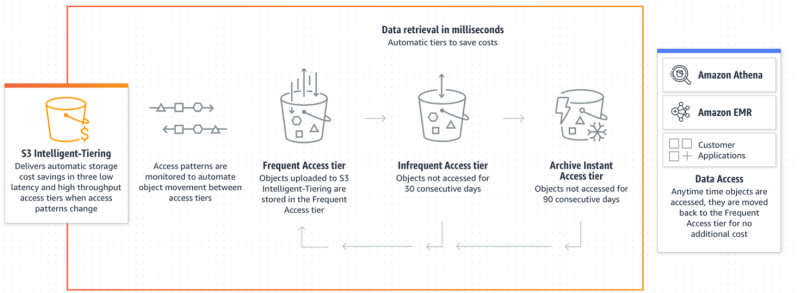
Il tiering intelligente è una scelta fattibile e ideale per gli utenti quando si tratta di ottimizzare i costi per modelli di accesso ai dati imprevedibili. Di seguito sono riportati i passaggi in cui possiamo implementare la classe di storage a tiering intelligente per l'efficienza dei costi:
Passaggio 1: dashboard S3
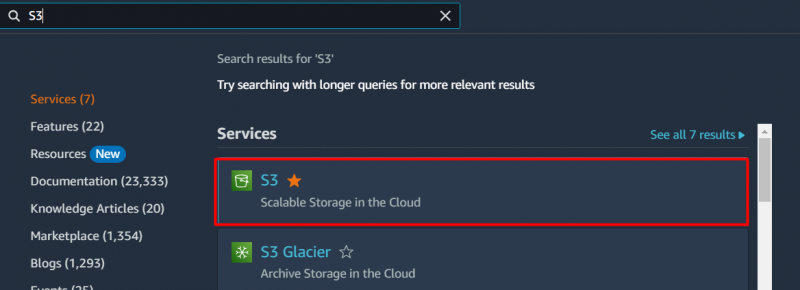
Per ottenere una soluzione economicamente vantaggiosa per l'archiviazione dei dati con il bucket S3, cerca il file 'S3' servizio nella barra di ricerca AWS e fai clic su di esso dai risultati visualizzati:
Passaggio 2: crea il bucket
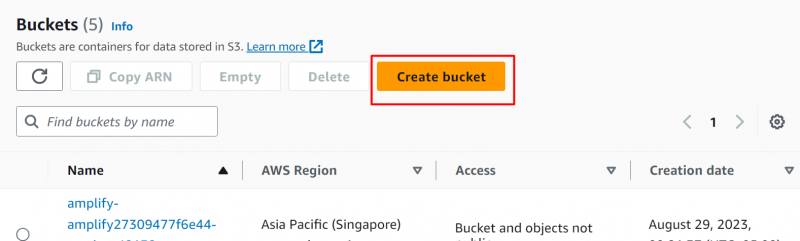
Clicca sul 'Crea secchio' pulsante sul Consolle S3 :
Passaggio 3: configurazioni generali
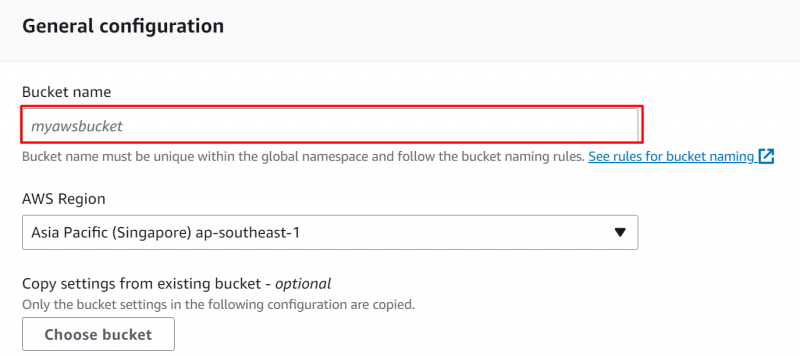
Dall'interfaccia visualizzata, fornire a identificativo unico per il bucket S3 nel file “Configurazioni generali” sezione:
Passaggio 4: tocca il pulsante 'Crea bucket'.
Mantenendo le impostazioni predefinite, fare clic su 'Crea secchio' pulsante situato nella parte inferiore dell'interfaccia:
Il bucket è stato creato correttamente. Successivamente, caricheremo un file in questo bucket. Fai clic sul nome del bucket per accedere all'interfaccia di caricamento del file:
Passaggio 5: carica i file
Clicca il 'Caricamento' pulsante sull'interfaccia visualizzata:
Per scegliere i file, fare clic su 'Aggiungere i file' pulsante e quindi seleziona i file/cartelle dal tuo dispositivo. Il file è stato caricato nel bucket S3:
Passare a 'Proprietà' bloccare e selezionare il pulsante ' Tiering intelligente” opzione da Classe di archiviazione sezione :
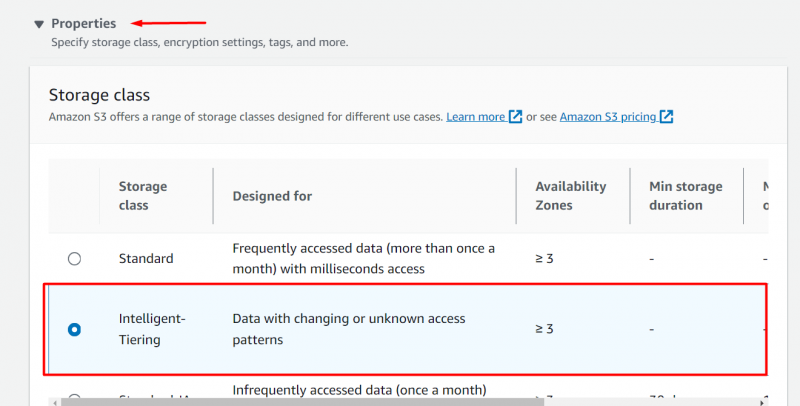
Mantenendo il resto del impostazioni invariate , clicca sul 'Caricamento' pulsante situato nella parte inferiore dell'interfaccia:
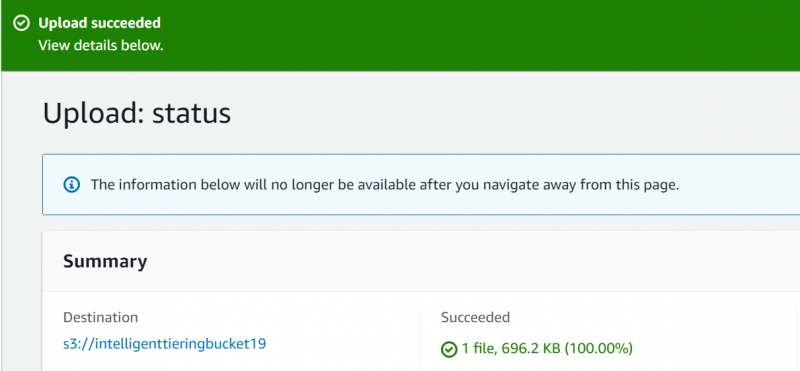
AWS visualizzerà un file messaggio di conferma che indica che il file è stato caricato con successo:
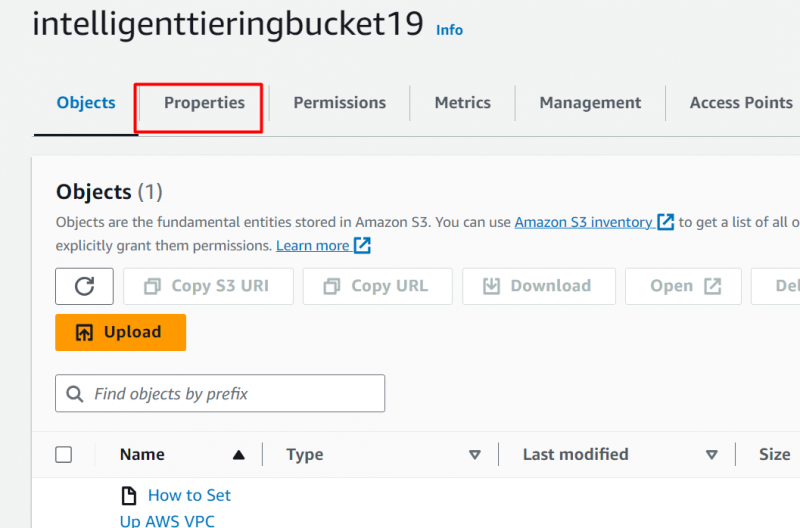
Passaggio 6: tocca la scheda 'Proprietà'.
Dopo aver caricato il file, fare clic su 'Proprietà' scheda:
Passaggio 7: configurazioni dell'archivio con suddivisione intelligente
Dal Proprietà interfaccia, scorrere verso il basso fino a 'Configurazioni di archiviazione con suddivisione intelligente' sezione e fare clic su “Crea configurazioni” pulsante:
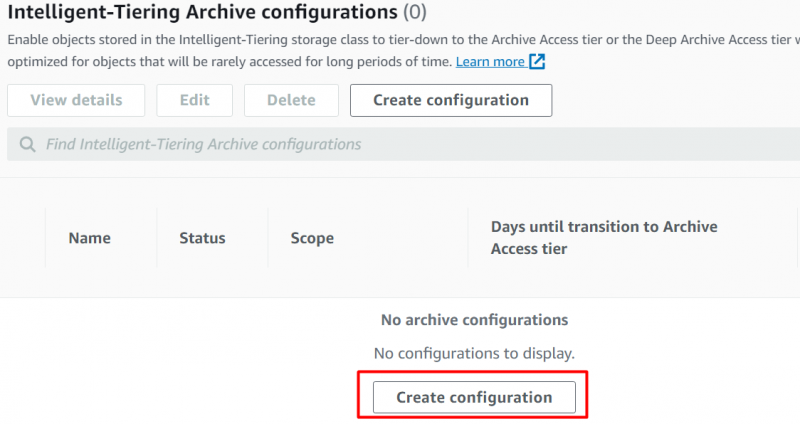
Fornire il 'Nome' e il 'Prefisso' per le configurazioni sulla successiva interfaccia visualizzata:
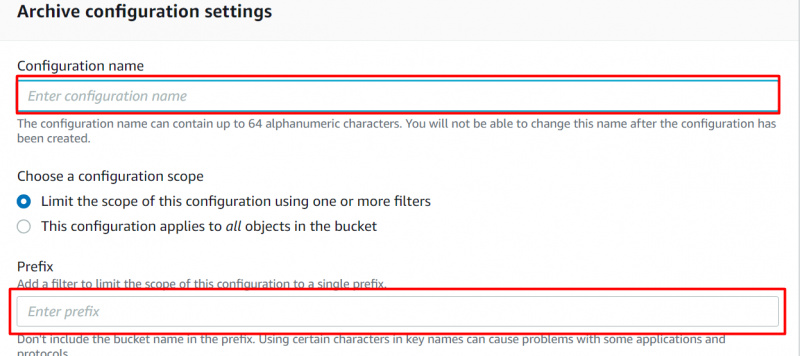
Passaggio 8: livello di accesso all'archivio
Passare a 'Azioni delle regole di archiviazione' sezione per configurare quando gli oggetti devono essere spostati. Abilita la seguente opzione e fornisci un numero di giorni consecutivi dopo i quali desideri spostare gli oggetti nel file “Livello di accesso all'archivio” :
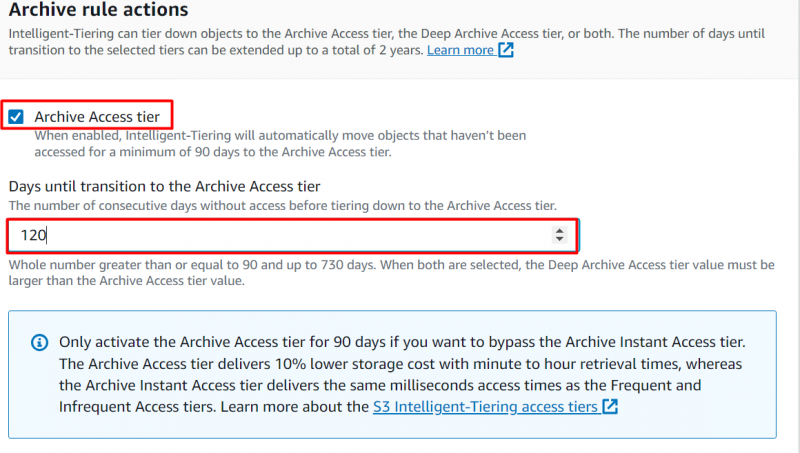
Nota : Se non si accede a un oggetto per un minimo di 90 giorni, l'oggetto verrà automaticamente spostato al livello di accesso all'archivio. Gli utenti possono estendere questo periodo a massimo Di 730 giorni.
Passaggio 9: livello di accesso all'archivio approfondito
Come il livello di accesso all'archivio, l'utente può anche configurare il livello di accesso all'archivio approfondito. Abilitando la seguente opzione, fornisci il numero di giorni dopo i quali l'oggetto dovrà essere spostato al livello di accesso Deep Archive. Dopo aver fornito il numero di giorni, fare clic su 'Creare' pulsante:
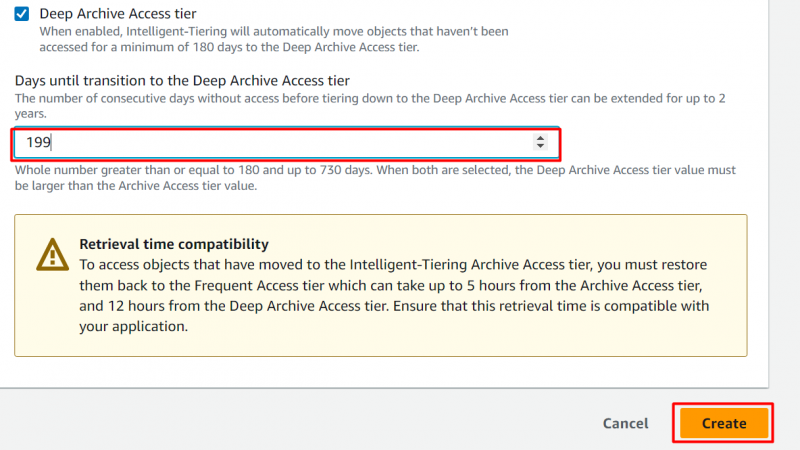
Nota : nel livello di accesso Deep Archive, gli oggetti a cui non è stato effettuato l'accesso per a minimo di 180 giorni vengono spostati in questo livello. Gli utenti possono personalizzare questo numero di giorni in a massimo di 730 giorni .
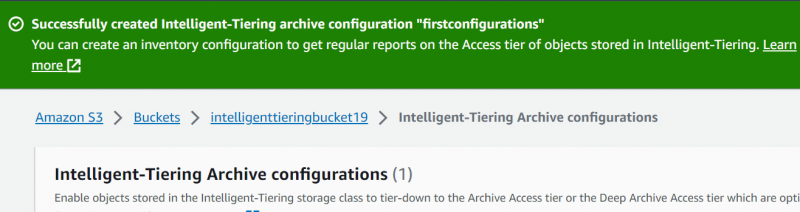
Le configurazioni vengono effettuate con successo. Ora, quando l'utente non accede agli oggetti caricati per il tempo specificato, i dati verranno automaticamente spostati su livelli diversi per ridurre al minimo la spesa:
Questo è tutto da questa guida.
Conclusione
Per l'ottimizzazione dei costi con il bucket S3, seleziona Classe di tiering intelligente durante il caricamento dei file e quindi fornire l'ora per i rispettivi livelli. Il tiering intelligente consente di risparmiare sui costi determinando gli oggetti a cui si accede frequentemente e raramente nei rispettivi livelli. Questo articolo fornisce istruzioni dettagliate per ottenere la soluzione economicamente ottimale con un bucket S3.