In questo articolo parleremo di come allocare DIVERSO memoria tramite il “ pytorch_cuda_alloc_conf ' metodo.
Qual è il metodo 'pytorch_cuda_alloc_conf' in PyTorch?
Fondamentalmente il “ pytorch_cuda_alloc_conf ' è una variabile d'ambiente all'interno del framework PyTorch. Questa variabile consente la gestione efficiente delle risorse di elaborazione disponibili, il che significa che i modelli vengono eseguiti e producono risultati nel minor tempo possibile. Se non eseguito correttamente, il “ DIVERSO La piattaforma di calcolo visualizzerà il messaggio ' fuori dalla memoria ' errore e influiscono sul runtime. Modelli che devono essere addestrati su grandi volumi di dati o che hanno grandi “ dimensioni dei lotti ' può produrre errori di runtime perché le impostazioni predefinite potrebbero non essere sufficienti per loro.
IL ' pytorch_cuda_alloc_conf La variabile 'utilizza il seguente' opzioni ' per gestire l'allocazione delle risorse:
- nativo : questa opzione utilizza le impostazioni già disponibili in PyTorch per allocare memoria al modello in corso.
- max_split_size_mb : Garantisce che qualsiasi blocco di codice più grande della dimensione specificata non venga suddiviso. Questo è un potente strumento per prevenire” frammentazione ”. Utilizzeremo questa opzione per la dimostrazione in questo articolo.
- roundup_power2_divisions : questa opzione arrotonda la dimensione dell'allocazione al ' potenza di 2 ' divisione in megabyte (MB).
- roundup_bypass_threshold_mb: Può arrotondare per eccesso la dimensione dell'allocazione per qualsiasi richiesta che elenca più della soglia specificata.
- soglia_raccolta_rifiuti : Previene la latenza utilizzando la memoria disponibile dalla GPU in tempo reale per garantire che il protocollo Reclaim-All non venga avviato.
Come allocare memoria utilizzando il metodo 'pytorch_cuda_alloc_conf'?
Qualsiasi modello con un set di dati di dimensioni considerevoli richiede un'allocazione di memoria aggiuntiva maggiore di quella impostata per impostazione predefinita. L'allocazione personalizzata deve essere specificata tenendo in considerazione i requisiti del modello e le risorse hardware disponibili.
Seguire i passaggi indicati di seguito per utilizzare ' pytorch_cuda_alloc_conf ' nell'IDE di Google Colab per allocare più memoria a un modello di apprendimento automatico complesso:
Passaggio 1: apri Google Colab
Cerca Google Collaborativo nel browser e creare un ' Nuovo taccuino ' per iniziare a lavorare:
Passaggio 2: imposta un modello PyTorch personalizzato
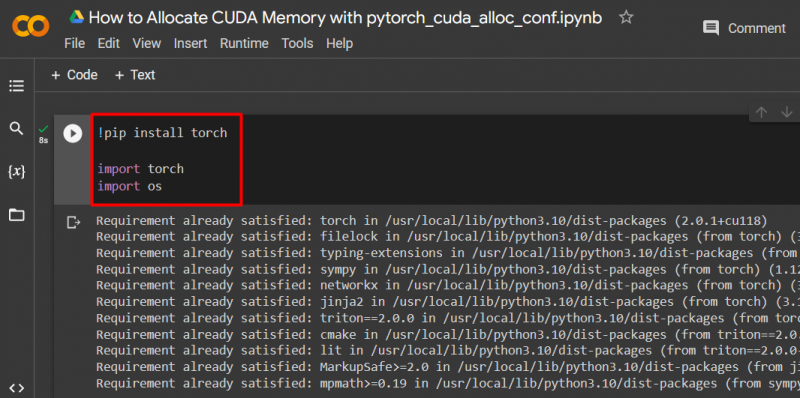
Configura un modello PyTorch utilizzando il pulsante ' !pip pacchetto di installazione per installare il ' torcia ” biblioteca e il “ importare “comando per importare” torcia ' E ' Voi ” librerie nel progetto:
torcia di importazione
importaci
Per questo progetto sono necessarie le seguenti librerie:
- Torcia – Questa è la libreria fondamentale su cui si basa PyTorch.
- VOI - IL ' sistema operativo La libreria ' viene utilizzata per gestire attività relative alle variabili di ambiente come ' pytorch_cuda_alloc_conf ' così come la directory di sistema e i permessi dei file:
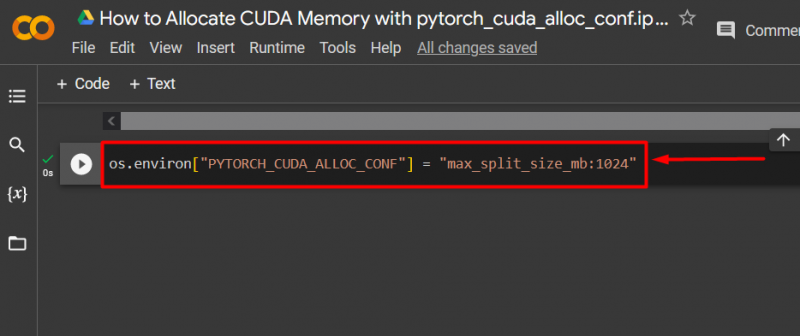
Passaggio 3: allocare memoria CUDA
Usa il ' pytorch_cuda_alloc_conf ' Metodo per specificare la dimensione massima di divisione utilizzando ' max_split_size_mb ':
Passaggio 4: continua con il tuo progetto PyTorch
Dopo aver specificato “ DIVERSO ” allocazione dello spazio con il “ max_split_size_mb ', continua a lavorare sul progetto PyTorch normalmente senza timore del ' fuori dalla memoria 'errore.
Nota : puoi accedere al nostro blocco note Google Colab da qui collegamento .
Suggerimento professionale
Come accennato in precedenza, il “ pytorch_cuda_alloc_conf ' Il metodo può accettare una qualsiasi delle opzioni sopra fornite. Usali in base ai requisiti specifici dei tuoi progetti di deep learning.
Successo! Abbiamo appena dimostrato come utilizzare il ' pytorch_cuda_alloc_conf ' Metodo per specificare un ' max_split_size_mb ' per un progetto PyTorch.
Conclusione
Usa il ' pytorch_cuda_alloc_conf ' per allocare la memoria CUDA utilizzando una qualsiasi delle opzioni disponibili in base ai requisiti del modello. Ognuna di queste opzioni ha lo scopo di alleviare un particolare problema di elaborazione all'interno dei progetti PyTorch per tempi di esecuzione migliori e operazioni più fluide. In questo articolo, abbiamo mostrato la sintassi per utilizzare il ' max_split_size_mb ' opzione per definire la dimensione massima della divisione.