Capitolo 4: Tutorial sul linguaggio assembly del microprocessore 6502
4.1 Introduzione
Il microprocessore 6502 è stato rilasciato nel 1975. È stato utilizzato come microprocessore per alcuni personal computer come Apple II, Commodore 64 e BBC Micro.
Il microprocessore 6502 viene prodotto ancora oggi in gran numero. Oggi non è più un'unità di elaborazione centrale utilizzata nei personal computer (laptop), ma viene ancora prodotta in grandi quantità e utilizzata negli apparecchi elettronici ed elettrici. Per comprendere le architetture dei computer più moderni, è molto utile esaminare un microprocessore più vecchio ma di discreto successo come il 6502.
Poiché è semplice da capire e programmare, è uno dei migliori (se non il migliore) microprocessore da utilizzare per insegnare il linguaggio assembly. Il linguaggio assembly è un linguaggio di basso livello che può essere utilizzato per programmare un computer. Si noti che il linguaggio assembly di un microprocessore è diverso dal linguaggio assembly di un altro microprocessore. In questo capitolo viene insegnato il linguaggio assembly del microprocessore 6502. Più precisamente, è il 65C02 che viene insegnato, ma viene chiamato semplicemente 6502.
Un famoso computer del passato si chiamava commodore_64. Il 6502 è un microprocessore della famiglia 6500. Il computer commodore_64 utilizza il microprocessore 6510. Il microprocessore 6510 è da 6500 µP. Il set di istruzioni del 6502 µP comprende quasi tutte le istruzioni del 6510 µP. La conoscenza di questo capitolo e del successivo si basa sul computer commodore_64. Questa conoscenza viene utilizzata come base per spiegare le moderne architetture informatiche e i moderni sistemi operativi in questa parte del corso di carriera online.
L'architettura del computer si riferisce ai componenti della scheda madre del computer e alla spiegazione di come i dati fluiscono all'interno di ciascun componente, in particolare nel microprocessore, di come i dati fluiscono tra i componenti e anche di come interagiscono i dati. Il singolare dei dati è datum. Un modo efficace per studiare l'architettura informatica di un computer è studiare il linguaggio assembly della scheda madre.
Si dice che il computer commodore_64 sia un computer con parola informatica a 8 bit. Ciò significa che le informazioni vengono archiviate, trasferite e manipolate sotto forma di codici binari a otto bit.
Diagramma a blocchi della scheda madre del Commodore 64
Lo schema a blocchi della scheda madre del Commodore 64 è:
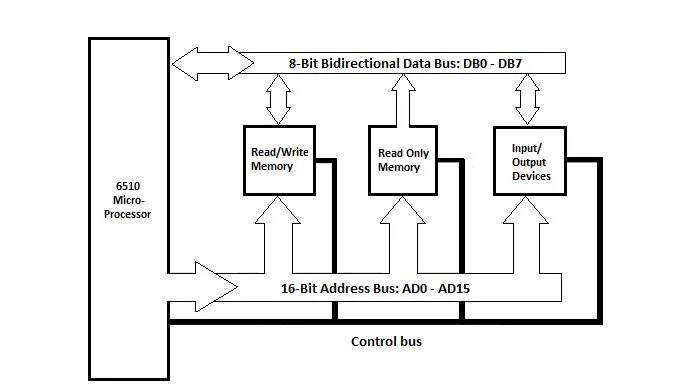
Fig 4.1 Diagramma a blocchi dell'unità di sistema Commodore_64
Immagina il microprocessore 6510 come il microprocessore 6502. La memoria totale è una serie di byte (8 bit per byte). C'è la memoria ad accesso casuale (lettura/scrittura) in cui i byte possono essere scritti o cancellati. Quando il computer viene spento, tutte le informazioni nella memoria ad accesso casuale (RAM) vengono cancellate. C'è anche la memoria di sola lettura (ROM). Quando si spegne il computer, le informazioni nella ROM rimangono (non vengono cancellate).
È presente la porta (circuito) di ingresso/uscita a cui ci si riferisce come dispositivi di ingresso/uscita nel diagramma. Questa porta non deve essere confusa con le porte visibili sulle superfici verticali sinistra e destra o davanti e dietro dell'unità di sistema del computer. Queste sono due cose diverse. I collegamenti da questa porta interna alle periferiche come il disco rigido (o floppy disk), la tastiera e il monitor non sono mostrati nello schema.
Nello schema sono presenti tre bus (gruppi di conduttori elettrici molto piccoli). Ogni filo può trasferire un bit 1 o un bit 0. Il bus dati, per il trasferimento di otto bit alla volta (un impulso di clock) alla RAM e alla porta di ingresso/uscita (dispositivi di ingresso/uscita) è bidirezionale. Il bus dati è largo otto bit.
Tutti i componenti sono collegati al bus indirizzi. Il bus degli indirizzi è unidirezionale dal microprocessore. Ci sono sedici conduttori per il bus degli indirizzi e ciascuno porta un bit (1 o 0). In un impulso di clock vengono inviati sedici bit.
C'è il bus di controllo. Alcuni conduttori del bus di controllo trasferirebbero ciascuno un bit dal microprocessore agli altri componenti. Alcune linee di controllo trasportano i bit dalla porta di ingresso/uscita (IO) al microprocessore.
Memoria del computer
La RAM e la ROM sono considerate come un unico gruppo di memoria. Questo assieme è rappresentato schematicamente come segue dove i numeri esadecimali hanno il prefisso “$”:
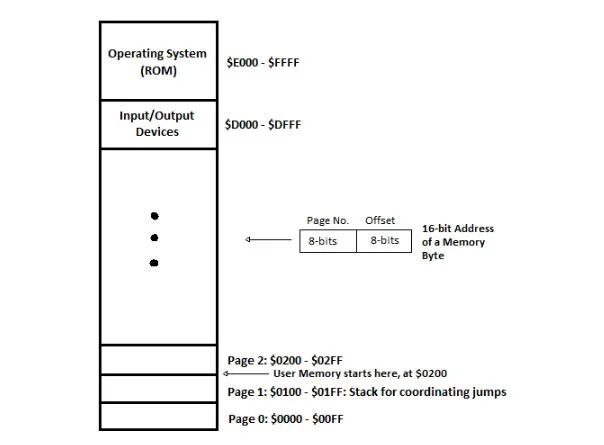
Fig 4.11 Layout della memoria per il computer Commodore 64
La RAM è da 0000 16 al DFFF 16 che è scritto da $ 0000 a $ DFFF. Con il linguaggio assembly 6502 µP, un numero esadecimale ha il prefisso '$' e non ha come suffisso (indice) 16 o H o esadecimale. Tutte le informazioni nella RAM scompaiono quando il computer è spento. La ROM inizia da $E000 a $FFFF. Ha subroutine che non si spengono quando il computer è spento. Queste subroutine sono le routine comunemente usate che aiutano nella programmazione. Il programma utente li richiama (vedi capitolo successivo).
Lo spazio (byte) da $0200 a $D000 è riservato ai programmi utente. Lo spazio da $D000 a $DFFF è riservato alle informazioni direttamente correlate alle periferiche (dispositivi di input/output). Questo fa parte del sistema operativo. Quindi, il sistema operativo del computer commodore-64 è composto da due parti principali: la parte nella ROM che non si spegne mai e la parte da $D000 a $DFFF che si spegne quando si spegne l'alimentazione. Questi dati IO (input/output) devono essere caricati da un disco ogni volta che il computer viene acceso. Oggi tali dati sono chiamati driver periferici. Le periferiche partono dalla porta Input/Output Device attraverso le connessioni presenti sulla scheda madre fino alle porte identificabili sulle superfici verticali del computer a cui sono collegati monitor, tastiera, ecc. e alle periferiche stesse (monitor, tastiera, ecc.) .).
La memoria è composta da 2 16 = posizioni da 65.536 byte. In forma esadecimale, sono 10000 16 = 10000 H = 10000 esadecimale = $ 10.000 località. In informatica, il conteggio in base due, base dieci, base sedici, ecc. inizia da 0 e non da 1. Quindi, la prima posizione è in realtà il numero di posizione di 0000000000000000 2 = 0 10 = 0000 16 = $ 0000. Nel linguaggio assembly 6502 µP, l'identificazione della posizione di un indirizzo è preceduta da $ e non vi è alcun suffisso o pedice. L'ultima posizione è il numero di posizione di 1111111111111111 2 = 65.535 10 =FFFF 16 = $FFFF e non 10000000000000000 2 o 65.536 10 o 10000 16 o $ 10.000. Il 10000000000000000 2 , 65.536 10 , 10000 16 , o $10000 fornisce il numero totale di posizioni di byte.
Ecco, 2 16 = 65.536 = 64 x 1024 = 64 x 2 10 = 64 Kbyte (kilobyte). Il suffisso 64 nel nome Commodore-64 significa 64KB di memoria totale (RAM e ROM). Un byte è composto da 8 bit e gli 8 bit andranno in una posizione di byte nella memoria.
I 64 Kbyte di memoria sono divisi in pagine. Ogni pagina ha 0100 16 = 256 10 posizioni dei byte. I primi 256 10 = primo 0100 16 posizioni è la pagina 0. La seconda è la pagina 1, la terza è la pagina 2 e così via.
Per indirizzare le 65.536 locazioni sono necessari 16 bit per ogni locazione (indirizzo). Quindi, il bus degli indirizzi dal microprocessore alla memoria è composto da 16 linee; una riga per un po'. Un bit è 1 o 0.
I registri 6502 µP
Un registro è come le celle di byte per una posizione di memoria di byte. Il 6502 µP ha sei registri: cinque registri da 8 bit e un registro da 16 bit. Il registro a 16 bit è chiamato Program Counter, abbreviato in PC. Contiene l'indirizzo di memoria per l'istruzione successiva. Un programma in linguaggio assembly è costituito da istruzioni che vengono inserite in memoria. Sono necessari sedici (16) bit diversi per indirizzare una particolare posizione di byte nella memoria. Ad un particolare impulso di clock, questi bit vengono inviati alle linee di indirizzo a 16 bit del bus indirizzi per la lettura di un'istruzione. Tutti i registri del 6502 µP sono rappresentati come segue:
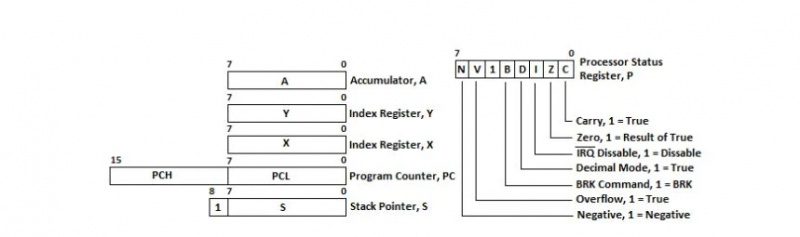
Fig. 4.12 Registri 6502 µP
Il Program Counter o PC può essere visto come un registro a 16 bit nel diagramma. Gli otto bit meno significativi sono etichettati come PCL per Program Counter Low. Gli otto bit significativi più alti sono etichettati come PCH per Program Counter High. Un'istruzione in memoria per il Commodore-64 può consistere di uno, due o tre byte. I 16 bit nel PC puntano alla successiva istruzione da eseguire, in memoria. Tra i circuiti del microprocessore, due di essi sono chiamati Unità Logica Aritmetica e Decodificatore di Istruzioni. Se l'istruzione corrente che viene elaborata nel µP (microprocessore) è lunga un byte, questi due circuiti aumentano il PC per l'istruzione successiva di 1 unità. Se l'istruzione corrente che viene elaborata nel µP è lunga due byte, ovvero occupa due byte consecutivi in memoria, questi due circuiti incrementano di 2 unità il PC per l'istruzione successiva. Se l'istruzione corrente che viene elaborata nel µP è lunga tre byte, ovvero occupa tre byte consecutivi in memoria, questi due circuiti incrementano di 3 unità il PC per l'istruzione successiva.
L'accumulatore 'A' è un registro di uso generale a otto bit che memorizza il risultato della maggior parte delle operazioni aritmetiche e logiche.
I registri “X” e “Y” vengono utilizzati ciascuno per contare i passaggi del programma. Il conteggio nella programmazione inizia da 0. Quindi vengono chiamati registri indice. Hanno alcuni altri scopi.
Sebbene il registro Stack Pointer, 'S' abbia 9 bit che è considerato un registro a otto bit. Il suo contenuto punta a una posizione in byte nella pagina 1 della memoria ad accesso casuale (RAM). La pagina 1 inizia dal byte $0100 (256 10 ) nel byte $01FF (511 10 ). Quando un programma è in esecuzione, si sposta da un'istruzione all'istruzione successiva consecutiva nella memoria. Tuttavia, questo non è sempre così. Ci sono momenti in cui salta da un'area di memoria a un'altra area di memoria per continuare a eseguire le istruzioni lì, consecutivamente. La pagina 1 in RAM viene utilizzata come stack. Lo stack è una grande area di memoria RAM che contiene gli indirizzi successivi per la continuazione del codice da cui avviene il salto. I codici con istruzioni di salto non sono nello stack; Sono altrove nella memoria. Tuttavia, dopo l'esecuzione delle istruzioni di salto, gli indirizzi di continuazione (non i segmenti di codice) si trovano nello stack. Sono stati spinti lì a seguito delle istruzioni di salto o di salto.
Il registro di stato del processore a otto bit di P è un tipo speciale di registro. I singoli bit non sono correlati o collegati tra loro. Ogni parte è chiamata bandiera ed è apprezzato indipendentemente dagli altri. I significati delle bandiere sono indicati nel seguente bisogno.
Il primo e l'ultimo bit indice per ciascun registro sono indicati sopra ciascun registro nel diagramma precedente. L'indice Bit (posizione) il conteggio in un registro inizia da 0 a destra.
Pagine di memoria in binario, esadecimale e decimale
La tabella seguente mostra l'inizio delle pagine di memoria in binario, esadecimale e decimale:

Ogni pagina ha 1.0000.0000 2 Numero di byte che è uguale a 100 H Numero di byte che è uguale a 256 10 numero di byte. Nello schema memoria precedente le pagine sono indicate salendo dalla pagina 0 e non scendendo come indicato in tabella.
Le colonne binarie, esadecimali e decimali di questa tabella forniscono indirizzi di posizione del byte di memoria nelle loro diverse basi. Si noti che per la pagina zero, è necessario digitare solo i bit per il byte inferiore durante la codifica. I bit per il byte più alto possono essere omessi poiché sono sempre zeri (per pagina zero). Per il resto delle pagine devono essere utilizzati i bit del byte più alto.
Il resto di questo capitolo spiega il linguaggio assembly del 6502 µP utilizzando tutte le informazioni precedenti. Per comprendere rapidamente la lingua, il lettore deve aggiungere e sottrarre in base sedici anziché in base dieci. In realtà dovrebbe essere in base due, ma il calcolo in base due è complicato. Ricorda che quando si sommano due numeri in base due, un riporto è ancora 1 come in base dieci. Ma quando si sottraggono due numeri in base due, il prestito è due e non dieci come in base dieci. Quando si sommano due numeri in base sedici, un riporto è ancora 1 come in base dieci. Ma quando si sottraggono due numeri in base sedici, il prestito è sedici e non dieci come in base dieci.
4.2 Istruzioni di trasferimento dei dati
Prendi in considerazione la seguente tabella delle istruzioni di trasferimento dei dati del linguaggio assembly per 6502 µp:
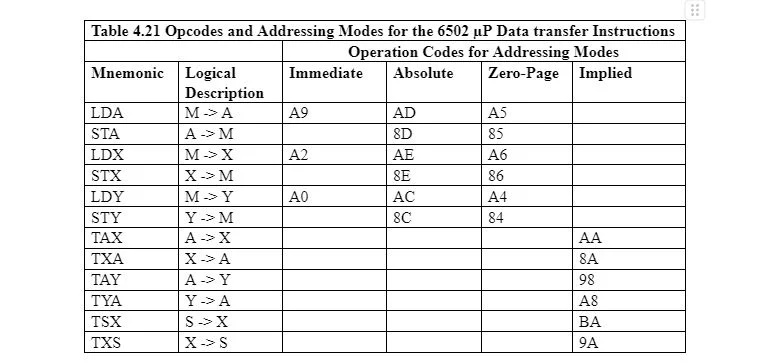
Quando un byte (8 bit) viene copiato da una posizione di byte di memoria nel registro dell'accumulatore, nel registro X o nel registro Y, è in corso il caricamento. Quando un byte viene copiato da uno qualsiasi di questi registri in una posizione di byte di memoria, si verifica un trasferimento. Quando un byte viene copiato da un registro a un altro, è ancora in fase di trasferimento. Nella seconda colonna della tabella la freccia indica la direzione della copia di un byte. Le restanti quattro colonne mostrano diverse modalità di indirizzamento.
Una voce nella colonna della modalità di indirizzamento è il codice byte effettivo per la parte mnemonica corrispondente dell'istruzione in esadecimale. AE, ad esempio, è l'effettivo codice byte per LDX che consiste nel caricare un byte dalla memoria al registro X in modalità di indirizzamento assoluto come AE 16 = 10101110 2 . Pertanto, i bit per LDX in una posizione di byte di memoria sono 10101110.
Si noti che per la parte mnemonica LDX dell'istruzione, ci sono tre possibili byte che sono A2, AE e A6 e ognuno è per una particolare modalità di indirizzamento. Quando il byte che si carica nel registro X non deve essere copiato da una posizione di byte di memoria, il valore deve essere digitato (subito dopo) il mnemonico LDX nell'istruzione in esadecimale o decimale. In questo capitolo tali valori vengono digitati in formato esadecimale. Questo è un indirizzamento immediato, quindi il byte effettivo in memoria per rappresentare LDX è A2 16 = 10100010 2 e non AE 16 che è uguale a 10101110 2 .
Nella tabella, tutti i byte sotto le intestazioni della modalità di indirizzamento sono chiamati Operation Codes, abbreviati in opcodes. Può esserci più di un codice operativo per un mnemonico, a seconda della modalità di indirizzamento.
Nota: La parola 'carico' nell'unità del sistema informatico può avere due significati: può fare riferimento al caricamento di un file da un disco alla memoria del computer o può fare riferimento al trasferimento di un byte da una posizione di byte di memoria a un registro a microprocessore .
Esistono più modalità di indirizzamento rispetto alle quattro nella tabella per il 6502 µP.
Salvo diversa indicazione, tutti i codici di programmazione utente contenuti in questo capitolo iniziano dall'indirizzo 0200 16 che è l'inizio dell'area utente nella memoria.
Memoria M e Accumulator a
Dalla memoria all'accumulatore
Indirizzamento immediato
La seguente istruzione memorizza il numero FF 16 = 255 10 nell'accumulatore:
LDA #$FF
Il “$” non viene utilizzato solo per identificare un indirizzo di memoria. In generale, viene utilizzato per indicare che il numero successivo che segue è esadecimale. In questo caso $FF non è l'indirizzo di alcuna posizione di byte di memoria. È il numero 255 10 in esadecimale. La base 16 o qualsiasi altro suo pedice equivalente non deve essere scritto nelle istruzioni del linguaggio assembly. Il “#” indica che quello che segue è il valore da inserire nel registro dell'accumulatore. Il valore può anche essere scritto in base dieci, ma ciò non viene fatto in questo capitolo. Il “#” significa indirizzamento immediato.
Un mnemonico ha qualche somiglianza con la sua corrispondente frase inglese. “LDA #$FF” significa caricare il numero 255 10 nell'accumulatore A. Poiché questo è un indirizzamento immediato dalla tabella precedente, LDA è A9 e non AD o A5. A9 in binario è 101010001. Quindi, se A9 per LDA è nell'indirizzo $ 0200 in memoria, $FF è nell'indirizzo $ 0301 = 0300 + 1. Il #$FF è precisamente l'operando per il mnemonico LDA.
Indirizzamento assoluto
Se il valore di $FF è nella posizione $0333 nella memoria, l'istruzione precedente è:
LDA $ 0333
Da notare l'assenza di #. In questo caso l'assenza di # significa che quello che segue è un indirizzo di memoria e non il valore di interesse (non il valore da inserire nell'accumulatore). Quindi, il codice operativo per LDA, questa volta, è AD e non A9 o A5. L'operando per LDA qui è l'indirizzo $0333 e non il valore $FF. $FF si trova nella posizione $ 0333, che è piuttosto lontana. L'istruzione “LDA $0333” occupa tre locazioni consecutive nella memoria e non due, come nell'illustrazione precedente. 'AD' per LDA si trova nella posizione $ 0200. Il byte inferiore di 0333 che è 33 si trova nella posizione $0301. Il byte più alto di $0333 che è 03 si trova nella posizione $0302. Questo è little endianness utilizzato dal linguaggio assembly 6502. I linguaggi assembly dei diversi microprocessori sono diversi.
Questo è un esempio di indirizzamento assoluto. $ 0333 è l'indirizzo della posizione che ha $ FF. L'istruzione è composta da tre byte consecutivi e non include $FF o la sua effettiva posizione in byte.
Indirizzamento a pagina zero
Supponiamo che il valore $FF sia nella posizione di memoria $0050 nella pagina zero. Le posizioni dei byte per la pagina zero iniziano da $0000 e terminano a $00FF. Questi sono 256 10 posizioni in totale. Ogni pagina della memoria del Commodore-64 è 256 10 lungo. Si noti che il byte più alto è zero per tutte le possibili posizioni nello spazio di pagina zero in memoria. La modalità di indirizzamento a pagina zero è uguale alla modalità di indirizzamento assoluto, ma il byte più alto di 00 non viene digitato nell'istruzione. Quindi, per caricare $FF dalla posizione $0050 nell'accumulatore, l'istruzione della modalità di indirizzamento a pagina zero è:
LDA$50
Con LDA che è A5 e non A9 o AD, A5 16 = 10100101 2 . Ricordatevi che ogni byte della memoria è composto da 8 celle, ed ogni cella ospita un bit. L'istruzione qui è composta da due byte consecutivi. A5 per LDA è nella posizione di memoria $0200 e l'indirizzo $50, senza il byte più alto di 00, è nella posizione $0301. L'assenza di 00, che avrebbe consumato un byte nella memoria totale di 64 KB, economizza lo spazio di memoria.
Accumulatore in memoria
Indirizzamento assoluto
La seguente istruzione copia un valore in byte, qualunque esso sia, dall'accumulatore alla posizione di memoria di $1444:
SONO $ 1444
Si dice che questo venga trasferito dall'accumulatore alla memoria. Non si sta caricando. Il caricamento è l'opposto. Il byte del codice operativo per STA è 8D 16 = 10001101 2 . Questa istruzione è composta da tre byte consecutivi nella memoria. L'8D 16 si trova nella posizione $ 0200. Il 44 16 dell'indirizzo $ 1444 si trova nella posizione $ 0201. E 14 16 si trova nella posizione $ 0202 – little endianness. Il byte effettivo che viene copiato non fa parte dell'istruzione. Per STA qui viene utilizzato 8D e non 85 per l'indirizzamento a pagina zero (nella tabella).
Indirizzamento a zero pagine
La seguente istruzione copia un valore di byte, qualunque esso sia, dall'accumulatore alla posizione di memoria di $0050 a pagina zero:
ST$0050
Il byte del codice operativo per STA qui è 85 16 = 10000101 2 . Questa istruzione è composta da due byte consecutivi in memoria. L'85 16 si trova nella posizione $ 0200. I 50 16 dell'indirizzo $0050 si trova nella posizione $0201. Il problema dell'endianness non si pone qui perché l'indirizzo ha solo un byte che è il byte più basso. Il byte effettivo che viene copiato non fa parte dell'istruzione. Per STA qui viene utilizzato 85 e non 8D per l'indirizzamento a pagina zero.
Non ha senso utilizzare l'indirizzamento immediato per trasferire un byte dall'accumulatore ad una locazione di memoria. Questo perché il valore effettivo come $FF deve essere citato nell'istruzione nell'indirizzamento immediato. Pertanto, non è possibile un indirizzamento immediato per il trasferimento di un valore in byte da un registro nel µP a qualsiasi posizione di memoria.
Mnemonici LDX, STX, LDY e STY
LDX e STX sono simili rispettivamente a LDA e STA. Ma qui viene utilizzato il registro X e non il registro A (accumulatore). LDY e STY sono simili rispettivamente a LDA e STA. Ma qui viene utilizzato il registro Y e non il registro A. Fare riferimento alla Tabella 4.21 per ciascun codice operativo in esadecimale che corrisponde a un particolare mnemonico e a una particolare modalità di indirizzamento.
Trasferimenti da registro a registro
I due gruppi di istruzioni precedenti nella Tabella 4.21 riguardano la copia di memoria/registro del microprocessore (trasferimento) e la copia di registro/registro (trasferimento). Le istruzioni TAX, TXA, TAY, TYA, TSX e TXS eseguono la copia (trasferimento) dal registro del microprocessore ad un altro registro dello stesso microprocessore.
Per copiare il byte da A a X, l'istruzione è:
IMPOSTA
Per copiare il byte da X ad A, l'istruzione è:
Texas
Per copiare il byte da A a Y, l'istruzione è:
MANO
Per copiare il byte da Y ad A, l'istruzione è:
TYA
Per il computer Commodore 64, lo stack è la pagina 1 subito dopo la pagina 0 nella memoria. Come ogni altra pagina, è composta da 25610 10 posizioni di byte, da $ 0100 a $ 01FF. Normalmente, un programma viene eseguito da un'istruzione all'istruzione successiva consecutiva nella memoria. Di tanto in tanto si passa a un altro segmento di codice di memoria (insieme di istruzioni). L'area dello stack in memoria (RAM) ha gli indirizzi delle istruzioni successive da dove si sono interrotti i salti (o i rami) per la continuazione del programma.
Lo stack pointer “S” è un registro a 9 bit nel 6502 µP. Il primo bit (più a sinistra) è sempre 1. Tutti gli indirizzi di posizione dei byte nella prima pagina iniziano con 1 seguito da 8 bit diversi per i 256 10 posizioni. Il puntatore dello stack ha l'indirizzo della posizione nella pagina 1 che ha l'indirizzo dell'istruzione successiva che il programma deve restituire e con cui continuare dopo aver eseguito il segmento di codice corrente (a cui si è passati). Poiché il primo bit di tutti gli indirizzi dello stack (pagina uno) inizia con 1, il registro del puntatore dello stack deve contenere solo i restanti otto bit. Dopotutto, il suo primo bit, che è il bit più a sinistra (il nono bit contando da destra), è sempre 1.
Per copiare il byte da S a X, l'istruzione è:
TSX
Per copiare il byte da X a S, l'istruzione è:
TXT
Le istruzioni da registro a registro non accettano alcun operando. Consistono solo nel mnemonico. Ogni mnemonico ha il suo codice operativo in esadecimale. Questa è la modalità di indirizzamento implicito poiché non è presente alcun operando (nessun indirizzo di memoria, nessun valore).
Nota: Non è previsto il trasferimento da X a Y o da Y a X (copia).
4.3 Operazioni aritmetiche
Il circuito, l'unità logico-aritmetica del 6502 µP, può aggiungere solo due numeri da otto bit alla volta. Non sottrae, non moltiplica e non divide. La tabella seguente mostra i codici operativi e le modalità di indirizzamento per le operazioni aritmetiche:
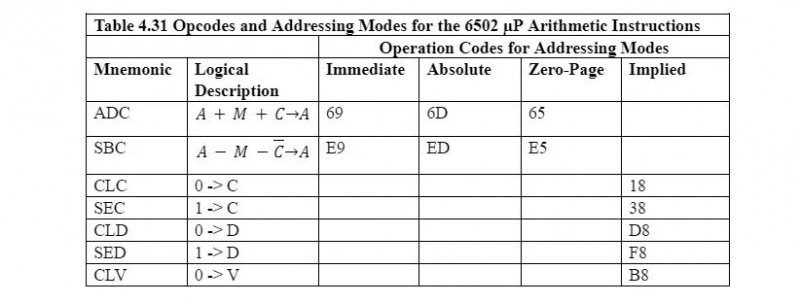
Nota: Tutti i mnemonici per le operazioni aritmetiche e altri tipi di operazioni (cioè tutti i mnemonici 6502) accettano un byte di codice operazione (op). Se esiste più di una modalità di indirizzamento per il mnemonico, ci sarebbero diversi codici operativi per lo stesso mnemonico: uno per modalità di indirizzamento. C, D e V nella tabella sono i flag del registro di stato. Il loro significato verrà spiegato in seguito quando se ne presenterà la necessità.
Aggiunta di numeri senza segno
Con il 6502 µP, i numeri con segno sono numeri in complemento a due. I numeri senza segno sono numeri positivi ordinari che iniziano da zero. Quindi, per un byte di otto bit, il numero senza segno più piccolo è 00000000 2 = 0 10 = 00 16 e il numero senza segno più grande è 11111111 2 = 255 10 =FF 16 . Per due numeri senza segno, l'addizione è:
A+M+C→A
Ciò significa che il contenuto di 8 bit dell'accumulatore viene aggiunto dall'unità logica aritmetica a un byte (8 bit) dalla memoria. Dopo l'aggiunta di A e M, il riporto al nono bit va alla cella del flag di riporto nel registro di stato. Anche qualsiasi bit di riporto precedente di un'addizione precedente che si trova ancora nella cella del flag di riporto nel registro di stato viene aggiunto alla somma di A e M, formando A+M+C→A. Il risultato viene rimesso nell'accumulatore.
Se l'aggiunta di interessi è:
A+M
E non è necessario aggiungere alcun riporto precedente, è necessario cancellare il flag di riporto che viene reso 0, in modo che l'addizione sia:
A+M+0→A uguale a A+M→A
Nota: Se M viene aggiunto ad A e si verifica un riporto di 1 perché il risultato è maggiore di 255 10 = 11111111 2 =FF 16 , questo è un nuovo riporto. Questo nuovo riporto di 1 viene inviato automaticamente alla cella del flag di riporto nel caso in cui sia necessario che la successiva coppia di otto bit venga sommata (un altro A + M).
Codice per aggiungere due otto bit senza segno
00111111 2 +00010101 2 è uguale a 3F 16 +15 16 che è uguale a 63 10 +21 10 . Il risultato è 010101002 2 che è uguale a 54 16 e 84 10 . Il risultato non supera il numero massimo di otto bit che è 255 10 = 11111111 2 =FF 16 . Quindi, non vi è alcun riporto risultante di 1. Per dirla in altro modo, il riporto risultante è 0. Prima dell'addizione, non esiste alcun riporto precedente di 1. In altre parole, il riporto precedente è 0. Il codice per eseguire questa addizione può essere:
CLC
LDA#$3F
ADC #$15
Nota: Durante la digitazione in linguaggio assembly, alla fine di ogni istruzione viene premuto il tasto “Invio” della tastiera. Ci sono tre istruzioni in questo codice. La prima istruzione (CLC) cancella il flag di riporto nel caso in cui una precedente aggiunta abbia 1. CLC può essere eseguito solo in modalità di indirizzamento implicito. Il mnemonico per la modalità di indirizzamento implicito non accetta operandi. Ciò cancella la cella di riporto del registro di stato di P. Cancellare significa dare il bit pari a 0 alla cella del flag di riporto. Le due istruzioni successive nel codice utilizzano la modalità di indirizzamento immediato. Con l'indirizzamento immediato, c'è un solo operando per il mnemonico che è un numero (e né un indirizzo di memoria né di registro). Pertanto, il numero deve essere preceduto da “#”. Il “$” significa che il numero che segue è esadecimale.
La seconda istruzione carica il numero 3F 16 nell'accumulatore. Per la terza istruzione, il circuito dell'unità logica aritmetica del µP prende il precedente riporto (azzerato) di 0 (forzato a 0) della cella carry flag, del registro di stato e lo somma a 15 16 nonché al valore già presente nel 3F 16 accumulatore e reinserisce il risultato completo nell'accumulatore. In questo caso, vi è un riporto risultante pari a 0. L'ALU (Arithmetic Logic Unit) invia (mette) 0 nella cella del flag di riporto del registro di stato. Il registro di stato del processore e il registro di stato significano la stessa cosa. Se risulta un carry di 1, l'ALU invia 1 al flag di carry del registro di stato.
Le tre righe del codice precedente devono essere in memoria prima di essere eseguite. Il codice operativo 1816 per CLC (indirizzamento implicito) si trova nella posizione byte $0200. Il codice operativo A9 16 per LDA (indirizzamento immediato) si trova nella posizione byte $0201. Il numero 3F 10 si trova nella posizione byte $ 0202. Il codice operativo 69 16 per LDA (indirizzamento immediato) si trova nella posizione byte $0203. Il numero 15 10 si trova nella posizione byte $ 0204.
Nota: LDA è un'istruzione di trasferimento (caricamento) e non un'istruzione aritmetica (mnemonica).
Codice per aggiungere due sedici bit senza segno
Tutti i registri del 6502 µP sono essenzialmente registri a otto bit, tranne il PC (Program Counter) che è a 16 bit. Anche il registro di stato è largo 8 bit, sebbene i suoi otto bit non funzionino insieme. In questa sezione viene considerata la somma di due 16 bit senza segno, con un riporto dalla prima coppia di otto bit alla seconda coppia di otto bit. Il riporto che interessa qui è il riporto dalla posizione dell'ottavo bit alla posizione del nono bit.
Lascia che i numeri siano 0010101010111111 2 = 2ABF16 16 = 10.943 10 e 0010101010010101 2 = 2A95 16 = 10.901 10 . La somma è 0101010101010100 2 = 5554 16 = 21.844 10 .
La somma di questi due numeri senza segno in base due è la seguente:

La tabella seguente mostra la stessa addizione con il riporto di 1 dalla posizione dell'ottavo bit alla posizione del nono bit, iniziando da destra:
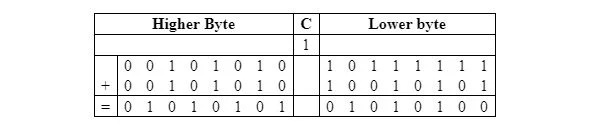
Nella codifica, i due byte inferiori vengono aggiunti per primi. Quindi, l'ALU (Arithmetic Logic Unit) invia il riporto di 1 dalla posizione dell'ottavo bit alla posizione del nono bit, alla cella del flag di riporto nel registro di stato. Il risultato di 0 1 0 1 0 1 0 0 senza riporto va all'accumulatore. Quindi, la seconda coppia di byte viene aggiunta con il riporto. Il mnemonico ADC significa aggiungere automaticamente al riporto precedente. In questo caso il riporto precedente, che è 1, non deve essere modificato prima della seconda addizione. Per la prima aggiunta, poiché qualsiasi riporto precedente non fa parte di questa aggiunta completa, deve essere cancellato (reso 0).
Per la somma completa delle due coppie di byte, la prima somma è:
A+M+0 -> A
La seconda aggiunta è:
A+M+1 -> A
Pertanto, il flag di riporto deve essere cancellato (dato il valore 0) appena prima della prima aggiunta. Il seguente programma di cui si rimanda alla spiegazione che segue utilizza per questa somma la modalità di indirizzamento assoluto:
CLC
LDA $ 0213
ADC $ 0215
; nessuna cancellazione perché è necessario il valore del flag di riporto
ST$0217
LDA $ 0214
ADC $ 0216
ST$0218
Si noti che con il linguaggio assembly 6502, un punto e virgola inizia un commento. Ciò significa che nell'esecuzione del programma il punto e virgola e tutto ciò che si trova alla sua destra viene ignorato. Il programma precedentemente scritto è in un file di testo che viene salvato con il nome scelto dal programmatore e con estensione “.asm”. Il programma precedente non è esattamente il programma che va in memoria per l'esecuzione. Il programma corrispondente nella memoria è chiamato programma tradotto in cui i mnemonici vengono sostituiti con i codici operativi (byte). Qualsiasi commento rimane nel file di testo in linguaggio assembly e viene rimosso prima che il programma tradotto raggiunga la memoria. Infatti, ci sono due file che oggi vengono salvati sul disco: il file “.asm” e il file “.exe”. Il file “.asm” è quello nell'illustrazione precedente. Il file '.exe' è il file '.asm' con tutti i commenti rimossi e tutti i mnemonici sostituiti dai relativi codici operativi. Quando viene aperto in un editor di testo, il file '.exe' è irriconoscibile. Se non diversamente specificato, ai fini di questo capitolo, il file “.exe” viene copiato in memoria a partire dalla posizione $0200. Questo è l'altro significato di caricamento.
I due numeri a 16 bit da sommare occupano quattro byte nella memoria per l'indirizzamento assoluto: due byte per numero (la memoria è una sequenza di byte). Con l'indirizzamento assoluto, l'operando del codice operativo è in memoria. Il risultato della somma è largo due byte e anch'esso deve essere inserito in memoria. Questo dà un totale di 6 10 = 6 16 byte per ingressi e uscite. Gli input non provengono dalla tastiera e l'output non proviene dal monitor o dalla stampante. Gli ingressi sono nella memoria (RAM) e l'uscita (risultato della somma) ritorna nella memoria (RAM) in questa situazione.
Prima che un programma venga eseguito, la versione tradotta deve essere presente in memoria. Osservando il codice del programma precedente si vede che le istruzioni senza commento sono 19 10 = 13 16 byte. Quindi, il programma prende dalla posizione di byte $ 0200 nella memoria a $ 0200 + $ 13 - $ 1 = $ 0212 posizioni di byte (iniziando da $ 0200 e non $ 0201 che implica - $ 1). Aggiungendo i 6 byte per i numeri di input e output, l'intero programma termina a $0212 + $6 = $0218. La durata totale del programma è di 19 16 = 25 10 .
Il byte più basso dello stesso augend dovrebbe trovarsi nell'indirizzo $ 0213, e il byte più alto dello stesso augend dovrebbe trovarsi nell'indirizzo $ 0214 – little endianness. Allo stesso modo, il byte più basso dell'addendo dovrebbe essere nell'indirizzo $ 0215, e il byte più alto dello stesso addendo dovrebbe essere nell'indirizzo $ 0216 – little endianness. Il byte più basso del risultato (somma) dovrebbe essere nell'indirizzo $ 0217, e il byte più alto dello stesso risultato dovrebbe essere nell'indirizzo $ 0218 – little endianness.
Il codice operativo 18 16 per CLC (indirizzamento implicito) si trova nella posizione in byte di $0200. Il codice operativo per “LDA $0213”, ovvero AD 16 per LDA (indirizzamento assoluto), si trova nella posizione in byte di $0201. Il byte inferiore dell'augend che è 10111111 si trova nella posizione del byte di memoria di $ 0213. Ricorda che ogni codice operativo occupa un byte. L'indirizzo '$0213' di 'LDA $0213' si trova nelle posizioni byte di $0202 e $0203. L'istruzione “LDA $0213” carica il byte inferiore dell'augend nell'accumulatore.
Il codice operativo per 'ADC $0215', ovvero 6D 16 per ADC (indirizzamento assoluto), si trova nella posizione in byte di $ 0204. Il byte inferiore dell'addendo che è 10010101 si trova nella posizione del byte $0215. L'indirizzo '$0215' di 'ADC $0215' si trova nelle posizioni byte di $0205 e $0206. L'istruzione “ADC $0215” aggiunge il byte inferiore dell'addendo al byte inferiore dell'augend che è già nell'accumulatore. Il risultato viene rimesso nell'accumulatore. Qualsiasi riporto dopo l'ottavo bit viene inviato al flag di riporto del registro di stato. La cella del flag di riporto non deve essere cancellata prima della seconda aggiunta dei byte più alti. Questo riporto viene aggiunto automaticamente alla somma dei byte più alti. Infatti, all'inizio viene aggiunto automaticamente un riporto pari a 0 alla somma dei byte inferiori (equivalente a non aggiungere alcun riporto) a causa del CLC.
Il commento richiede i successivi 48 10 = 30 16 byte. Questo però rimane solo nel file di testo “.asm”. Non raggiunge la memoria. Viene rimosso dalla traduzione effettuata dall'assemblatore (un programma).
Per l'istruzione successiva che è 'STA $0217', il codice operativo di STA è 8D 16 (indirizzamento assoluto) si trova nella posizione in byte di $0207. L'indirizzo “$0217” di “STA $0217” si trova nelle posizioni di memoria di $0208 e $0209. L'istruzione “STA $0217” copia il contenuto di otto bit dell'accumulatore nella posizione di memoria di $0217.
Il byte più alto dell'addendo che è 00101010 è nella posizione di memoria di $0214, e il byte più alto dell'addendo che è 00101010 è nella posizione del byte di $02 16 . Il codice operativo per 'LDA $0214', che è AD16 per LDA (indirizzamento assoluto), si trova nella posizione byte di $020A. L'indirizzo '$0214' di 'LDA $0214' si trova nelle posizioni $020B e $020C. L'istruzione “LDA $0214” carica il byte più alto dell'augend nell'accumulatore, cancellando tutto ciò che è nell'accumulatore.
Il codice operativo per 'ADC $0216' che è 6D 16 per ADC (indirizzamento assoluto) si trova nella posizione in byte di $020D. L'indirizzo '$0216' di 'ADC 0216' si trova nelle posizioni byte di $020E e $020F. L'istruzione “ADC $0216” aggiunge il byte più alto dell'addendo al byte più alto dell'augend che è già nell'accumulatore. Il risultato viene rimesso nell'accumulatore. Se c'è un carry pari a 1, per questa seconda aggiunta, viene automaticamente inserito nella cella carry del registro di stato. Sebbene il riporto oltre il sedicesimo bit (a sinistra) non sia richiesto per questo problema, è utile verificare se si è verificato un riporto di 1 controllando se il flag di riporto è diventato 1.
Per la successiva e ultima istruzione che è “STA $0218”, il codice operativo di STA che è 8D16 (indirizzamento assoluto) si trova nella posizione in byte di $0210. L'indirizzo “$0218” di “STA $0218” si trova nelle posizioni di memoria di $0211 e $0212. L'istruzione “STA $0218” copia il contenuto a otto bit dell'accumulatore nella posizione di memoria di $0218. Il risultato della somma dei due numeri a sedici bit è 0101010101010100, con il byte inferiore di 01010100 nella posizione di memoria di $ 0217 e il byte più alto di 01010101 nella posizione di memoria di $ 0218 – little endianness.
Sottrazione
Con il 6502 µP, i numeri con segno sono numeri in complemento a due. Il numero in complemento a due può essere di otto bit, sedici bit o qualsiasi multiplo di otto bit. Con il complemento a due, il primo bit da sinistra è il bit del segno. Per un numero positivo, questo primo bit è 0 per indicare il segno. Il resto dei bit forma il numero normalmente. Per ottenere il complemento a due di un numero negativo, invertire tutti i bit del numero positivo corrispondente, quindi aggiungere 1 al risultato dall'estremità destra.
Per sottrarre un numero positivo da un altro numero positivo, il sottraendo viene convertito in un numero negativo in complemento a due. Quindi si sommano normalmente il minuendo e il nuovo numero negativo. Quindi, la sottrazione di otto bit diventa:
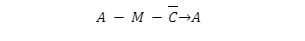
Dove il riporto è assunto come 1. Il risultato nell'accumulatore è la differenza nel complemento a due. Quindi, per sottrarre due numeri, è necessario impostare il flag di riporto (portato a 1).
Quando si sottraggono due numeri a sedici bit, la sottrazione viene eseguita due volte come con l'addizione di due numeri a sedici bit. Poiché la sottrazione è una forma di addizione con il 6502 µP, quando si sottraggono due numeri a sedici bit, il flag di riporto viene impostato solo una volta per la prima sottrazione. Per la seconda sottrazione, qualsiasi impostazione del flag di riporto viene eseguita automaticamente.
La programmazione della sottrazione per i numeri a otto bit o per i numeri a sedici bit viene eseguita in modo simile alla programmazione dell'addizione. Tuttavia, il carry flag deve essere impostato proprio all'inizio. Lo mnemonico per farlo è: 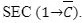
Sottrazione con numeri positivi a sedici bit
Considera la sottrazione con i seguenti numeri:

Questa sottrazione non implica il complemento a due. Poiché la sottrazione in 6502 µP viene eseguita in complemento a due, la sottrazione in base due viene eseguita come segue:
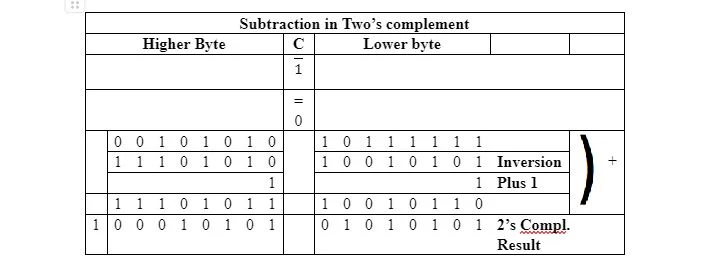
Il risultato del complemento a due è lo stesso risultato ottenuto dalla sottrazione ordinaria. Tuttavia, si noti che l'1 che va alla diciassettesima posizione di bit da destra viene ignorato. Il minuendo e il sottraendo sono divisi ciascuno in due bit da otto. Il complemento a due di 10010110 del byte inferiore del sottraendo è determinato indipendentemente dal byte superiore e da qualsiasi riporto. Il complemento a due di 11101011 del byte più alto del sottraendo è determinato indipendentemente dal byte più basso e da qualsiasi riporto.
I 16 bit del minuendo sono già in complemento a due, iniziando con 0 da sinistra. Quindi, non necessita di alcuna regolazione in bit. Con il 6502 µP, il byte inferiore del minuendo senza alcuna modifica viene aggiunto al byte inferiore del complemento a due del sottraendo. Il byte inferiore del minuendo non viene convertito in complemento a due perché i sedici bit dell'intero minuendo devono essere già in complemento a due (con uno 0 come primo bit a sinistra). In questa prima aggiunta, viene aggiunto un riporto obbligatorio di 1 a causa dell'istruzione 1=0 SEC.
Nella sottrazione effettiva corrente, c'è un riporto di 1 (dell'addizione) dall'ottavo bit al nono bit (da destra). Poiché si tratta effettivamente di una sottrazione, qualunque bit che dovrebbe essere nel flag di riporto nel registro di stato viene complementato (invertito). Quindi, il riporto di 1 diventa 0 nel flag C. Nella seconda operazione, il byte più alto del minuendo viene aggiunto al byte del complemento a due più alto del sottraendo. Viene aggiunto (ai byte più alti) anche il bit del flag di riporto automaticamente complementato del registro di stato (in questo caso è 0). Qualsiasi 1 che va oltre il sedicesimo bit da destra viene ignorato.
La prossima cosa è semplicemente codificare tutto quello schema come segue:
SEZ
LDA $ 0213
SBC $ 0215
; nessuna cancellazione perché è necessario il valore del flag di riporto invertito
ST$0217
LDA $ 0214
SBC $ 0216
ST$0218
Si ricorda che con il linguaggio assembly 6502 il punto e virgola inizia un commento che non è presente in memoria nella versione del programma tradotto. I due numeri a 16 bit per la sottrazione occupano quattro byte di memoria con indirizzamento assoluto; due per numero (la memoria è una serie di byte). Questi input non provengono dalla tastiera. Il risultato della somma è di due byte e deve essere anch'esso collocato in memoria in un posto diverso. Questo output non va al monitor o alla stampante; va alla memoria. Questo dà un totale di 6 10 = 6 16 byte per ingressi e uscite da posizionare nella memoria (RAM).
Prima che un programma venga eseguito, deve essere prima nella memoria. Osservando il codice del programma si vede che le istruzioni senza commento sono 19 10 = 13 16 byte. Poiché tutti i programmi in questo capitolo iniziano dalla posizione di memoria di $0200, il programma prende dalla posizione di byte $0200 nella memoria alla posizione di byte $0200 + $13 – $1 = $0212 (iniziando da $0200 e non $0201). Questo intervallo non include la regione per i byte di input e output. I due numeri di ingresso occupano 4 byte e il numero di uscita occupa 2 byte. Aggiungendo i 6 byte per i numeri di input e output si ottiene l'intervallo del programma che termina con $0212 + $6 = $0218. La durata totale del programma è di 19 16 = 25 10 .
Il byte più basso del minuendo dovrebbe essere nell'indirizzo $ 0213, e il byte più alto dello stesso minuendo dovrebbe essere nell'indirizzo $ 0214 – little endianness. Allo stesso modo, il byte più basso del sottraendo dovrebbe essere nell’indirizzo $ 0215, e il byte più alto dello stesso sottraendo dovrebbe essere nell’indirizzo $ 0216 – little endianness. Il byte più basso del risultato (differenza) dovrebbe essere nell'indirizzo $ 0217, e il byte più alto dello stesso risultato dovrebbe essere nell'indirizzo $ 0218 – little endianness.
Il codice operativo di 38 16 per SEC (indirizzamento implicito) è nell'indirizzo $ 0200. Si presuppone che tutti i programmi in questo capitolo inizino nella posizione di memoria $0200, annullando qualsiasi programma che sarebbe stato lì; salvo diversa indicazione. Il codice operativo per “LDA $0213”, ovvero AD 16 , per LDA (indirizzamento assoluto) si trova nella posizione byte $0201. Il byte inferiore del minuendo che è 10111111 si trova nella posizione del byte di memoria $0213. Ricorda che ogni codice operativo occupa un byte. L'indirizzo '$0213' di 'LDA $0213' si trova nelle posizioni byte di $0202 e $0203. L'istruzione “LDA $0213” carica il byte inferiore del minuendo nell'accumulatore.
Il codice operativo per 'SBC $0215', ovvero ED 16 , per SBC (indirizzamento assoluto) si trova nella posizione byte $0204. Il byte inferiore del sottraendo che è 01101010 si trova nella posizione del byte $ 0215. L'indirizzo '$0215' di 'ADC $0215' si trova nelle posizioni byte di $0205 e $0206. L'istruzione “SBC $0215” sottrae il byte inferiore del sottraendo dal byte inferiore del minuendo già presente nell'accumulatore. Questa è la sottrazione del complemento a due. Il risultato viene rimesso nell'accumulatore. Il complemento (inversione) di qualsiasi riporto dopo l'ottavo bit viene inviato al flag di riporto del registro di stato. Questo flag di riporto non deve essere cancellato prima della seconda sottrazione con i byte più alti. Questo riporto viene aggiunto automaticamente alla sottrazione dei byte più alti.
Il commento prende i successivi 57 10 = 3916 16 byte. Questo però rimane solo nel file di testo “.asm”. Non raggiunge la memoria. Viene rimosso dalla traduzione effettuata dall'assemblatore (un programma).
Per l'istruzione successiva che è “STA $0217”, il codice operativo di STA, ovvero 8D 16 (indirizzamento assoluto), si trova nella posizione byte $0207. L'indirizzo “$0217” di “STA $0217” si trova nelle posizioni di memoria di $0208 e $0209. L'istruzione “STA $0217” copia il contenuto di otto bit dell'accumulatore nella posizione di memoria di $0217.
Il byte più alto del minuendo che è 00101010 è nella posizione di memoria di $0214, e il byte più alto del sottraendo che è 00010101 è nella posizione di byte di $0216. Il codice operativo per “LDA $0214”, ovvero AD 16 per LDA (indirizzamento assoluto), si trova nella posizione byte $020A. L'indirizzo '$0214' di 'LDA $0214' si trova nelle posizioni $020B e $020C. L'istruzione “LDA $0214” carica il byte più alto del minuendo nell'accumulatore, cancellando tutto ciò che è nell'accumulatore.
Il codice operativo per 'SBC $0216', ovvero ED 16 per SBC (indirizzamento assoluto), si trova nella posizione byte $020D. L'indirizzo '$0216' di 'SBC $0216' si trova nelle posizioni byte di $020E e $020F. L’istruzione “SBC $0216” sottrae il byte più alto del sottraendo dal byte più alto del minuendo (complemento a due) che è già nell’accumulatore. Il risultato viene rimesso nell'accumulatore. Se c'è un carry pari a 1 per questa seconda sottrazione, il suo complemento viene inserito automaticamente nella cella carry del registro di stato. Sebbene il riporto oltre il sedicesimo bit (a sinistra) non sia richiesto per questo problema, è utile verificare se si verifica il riporto del complemento controllando il flag di riporto.
Per la successiva e ultima istruzione che è “STA $0218”, il codice operativo di STA, ovvero 8D 16 (indirizzamento assoluto), si trova nella posizione byte $0210. L'indirizzo “$0218” di “STA $0218” si trova nelle posizioni di memoria di $0211 e $0212. L'istruzione “STA $0218” copia il contenuto a otto bit dell'accumulatore nella posizione di memoria di $0218. Il risultato della sottrazione con i due numeri a sedici bit è 0001010101010101 con il byte inferiore di 01010101 nella posizione di memoria di $ 0217 e il byte più alto di 00010101 nella posizione di memoria di $ 0218 – little endianness.
Il 6502 µP è dotato di circuiti solo per l'addizione e indirettamente per la sottrazione del complemento a due. Non ha circuiti per la moltiplicazione e la divisione. Per eseguire la moltiplicazione e la divisione, dovrebbe essere scritto un programma in linguaggio assembly con i dettagli, incluso lo spostamento dei prodotti parziali e dei dividendi parziali.
4.4 Operazioni logiche
Nel 6502 µP, il mnemonico per OR è ORA e il mnemonico per OR esclusivo è EOR. Si noti che le operazioni logiche non hanno l'indirizzamento implicito. L'indirizzamento implicito non richiede operandi. Ciascuno degli operatori logici deve accettare due operandi. Il primo è nell'accumulatore e il secondo è nella memoria o nell'istruzione. Il risultato (8 bit) ritorna nell'accumulatore. Il primo nell'accumulatore o viene inserito con un'istruzione immediata oppure viene copiato dalla memoria con indirizzamento assoluto. In questa sezione viene utilizzato solo l'indirizzamento a pagina zero a scopo illustrativo. Questi operatori logici sono tutti operatori bit a bit.
E
La tabella seguente illustra l'AND bit a bit in formato binario, esadecimale e decimale:
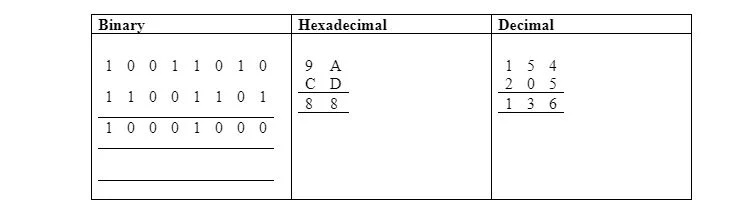
Tutti i programmi in questo capitolo dovrebbero iniziare dalla posizione del byte di memoria $0200. Tuttavia i programmi di questa sezione sono a pagina zero, con lo scopo di illustrare l'uso della pagina zero senza il byte più alto di 00000000 2 . Il precedente AND può essere codificato come segue:
LDA #$9A ; non dalla memoria – indirizzamento immediato
AND #$CD ; non dalla memoria – indirizzamento immediato
ST$30; memorizza $88 a $0030 in base zero
O
La tabella seguente illustra l'OR bit a bit in formato binario, esadecimale e decimale:
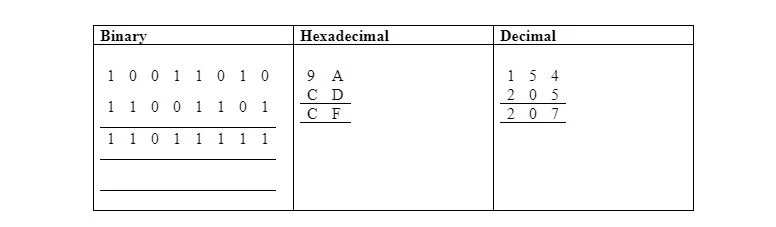
LDA #$9A ; non dalla memoria – indirizzamento immediato
ORA #$CD ; non dalla memoria – indirizzamento immediato
ST$30; memorizza $CF a $0030 in base zero
GRATUITO
La tabella seguente illustra lo XOR bit a bit in formato binario, esadecimale e decimale:

LDA #$9A ; non dalla memoria – indirizzamento immediato
EOR #$CD ; non dalla memoria – indirizzamento immediato
ST$30; memorizza $ 57 a $ 0030 in base zero
4.5 Operazioni di spostamento e rotazione
I mnemonici e i codici operativi per gli operatori di spostamento e rotazione sono:
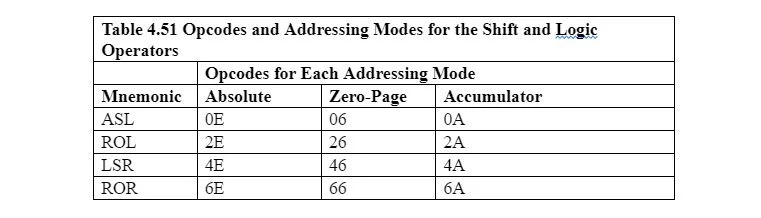
ASL: sposta a sinistra un bit dell'accumulatore o della posizione di memoria, inserendo 0 nella cella libera più a destra.
LSR: sposta a destra un bit dell'accumulatore o della posizione di memoria, inserendo 0 nella cella libera più a sinistra.
ROL: ruota un bit a sinistra dell'accumulatore o della posizione di memoria, inserendo il bit eliminato a sinistra nella cella libera più a destra.
ROR: ruota di un bit a destra dell'accumulatore o della posizione di memoria, inserendo il bit eliminato a destra nella cella libera più a sinistra.
Per eseguire uno spostamento o una rotazione con l'accumulatore, l'istruzione è più o meno questa:
LSR A
Questo utilizza un'altra modalità di indirizzamento chiamata modalità di indirizzamento dell'accumulatore.
Per eseguire uno spostamento o una rotazione con una posizione di memoria di byte, l'istruzione è simile a questa:
ROR$2BCD
Dove 2BCD è la posizione di memoria.
Si noti che non esiste una modalità di indirizzamento immediata o implicita per lo spostamento o la rotazione. Non esiste una modalità di indirizzamento immediato perché non ha senso spostare o ruotare un numero che rimane solo nell'istruzione. Non esiste una modalità di indirizzamento implicita poiché i progettisti del 6502 µP desiderano che venga spostato o ruotato solo il contenuto dell'accumulatore (registro A) o la posizione di un byte di memoria.
4.6 Modalità di indirizzamento relativo
Il microprocessore incrementa sempre (di 1, 2 o 3 unità) il Program Counter (PC) per puntare alla successiva istruzione da eseguire. Il 6502 µP ha un'istruzione il cui mnemonico è BVS che significa Branch on Overflow Set. Il PC è composto da due byte. Questa istruzione fa sì che il PC abbia un indirizzo di memoria diverso per l'istruzione successiva da eseguire non risultante da un incremento normale. Lo fa aggiungendo o sottraendo un valore, chiamato offset, al contenuto del PC. E così, il PC punta quindi a una posizione di memoria diversa (ramificata) affinché il computer possa continuare l'esecuzione da lì. L'offset è un numero intero compreso tra -128 10 a +127 10 (complemento a due). Quindi, l'offset può far avanzare il salto nella memoria. Se è positivo o indietro nella memoria, oppure se è negativo.
L'istruzione BVS accetta solo un operando che è l'offset. BVS utilizza l'indirizzamento relativo. Considera le seguenti istruzioni:
BVS $ 7F
In base due, 7F H è 01111111 2 = 127 10 . Supponiamo che il contenuto nel PC per l'istruzione successiva sia $ 0300. L’istruzione BVS fa sì che $7F (un numero positivo già in complemento a due) venga aggiunto a $0300 per dare $037F. Quindi, invece che l'istruzione successiva da eseguire nella posizione di memoria di $0300, questa sarà nella posizione di memoria di $037F (circa mezza pagina di differenza).
Esistono altre istruzioni di diramazione, ma BVS è ottima da utilizzare per illustrare l'indirizzamento relativo. L'indirizzamento relativo riguarda le istruzioni di salto.
4.7 Indirizzamento indicizzato e indirizzamento indiretto separatamente
Queste modalità di indirizzamento consentono al 6502 µP di gestire enormi quantità di dati in brevi periodi di tempo con un numero ridotto di istruzioni. Ci sono posizioni da 64KB per l'intera memoria del Comodore-64. Quindi, per accedere a qualsiasi posizione di byte, di 16 bit, sono necessari due byte. L'unica eccezione alla necessità di due byte è per la pagina zero dove il byte più alto di $00 viene omesso per risparmiare lo spazio occupato dall'istruzione in memoria. Con una modalità di indirizzamento diversa da zero di pagina, sia i byte più alti che quelli più bassi dell'indirizzo di memoria a 16 bit vengono per lo più indicati in qualche modo.
Indirizzamento indicizzato di base
Indirizzamento dell'indice assoluto
Ricorda che il registro X o Y è chiamato registro indice. Considera le seguenti istruzioni:
LDA$C453,X
Supponiamo che il valore di 6 H è nel registro X. Si noti che 6 non è digitato da nessuna parte nell'istruzione. Questa istruzione aggiunge il valore di 6H a C453 H che fa parte dell'istruzione digitata nel file di testo ancora da assemblare – C453 H +6 H = C459 H . LDA significa caricare un byte nell'accumulatore. Il byte da caricare nell'accumulatore proviene dall'indirizzo $C459. Il $C459 che è la somma di $C453 digitato con l'istruzione e 6 H che si trova nel registro X diventa l'effettivo indirizzo da cui proviene il byte da caricare nell'accumulatore. Se 6 H era nel registro Y, Y viene digitato al posto di X nell'istruzione.
Nell'istruzione digitata, $C453 è noto come indirizzo di base e 6 H nel registro X o Y è nota come parte di conteggio o indice per l'indirizzo effettivo. L'indirizzo di base può fare riferimento a qualsiasi indirizzo di byte nella memoria e ai successivi 256 10 è possibile accedere agli indirizzi presupponendo che l'indice (o conteggio) iniziale nel registro X o Y sia 0. Ricordare che un byte può fornire un intervallo continuo fino a 256 10 numeri (ad esempio 00000000 2 a 11111111 2 ).
Quindi l'indirizzamento assoluto somma quello che è già stato messo (è stato messo da un'altra istruzione) nel registro X o Y ai 16 indirizzi che vengono digitati con l'istruzione per ottenere l'indirizzo effettivo. Nell'istruzione tipizzata, i due registri indice sono distinti da X o Y che vengono digitati dopo una virgola. Viene digitato X o Y; non entrambi.
Dopo che tutto il programma è stato digitato in un editor di testo e salvato con il nome file con estensione “.asm”, l'assemblatore, che è un altro programma, deve tradurre il programma digitato in ciò che è (caricato) nella memoria. L'istruzione precedente, che è “LDA $C453,X”, occupa tre posizioni di byte nella memoria e non cinque.
Ricorda che un mnemonico come LDA può avere più di un codice operativo (byte diversi). Il codice operativo per l'istruzione che utilizza il registro X è diverso dal codice operativo che utilizza il registro Y. L'assemblatore sa quale codice operativo utilizzare in base all'istruzione digitata. Il codice operativo da un byte per “LDA $C453,X” è diverso dal codice operativo da un byte per “LDA $C453,Y”. Infatti, il codice operativo per LDA in “LDA $C453,X” è BD e il codice operativo per LDA in “LDA $C453,9” è BD.
Se il codice operativo per LDA si trova nella posizione byte $ 0200. Quindi, l'indirizzo a 16 bit di $C453 occupa le successive posizioni di byte nella memoria che sono $0201 e $0202. Il particolare byte del codice operativo indica se è coinvolto il registro X o il registro Y. E così, l'istruzione di linguaggio assemblata che è “LDA $C453,X” o “LDA $C453,Y” occupa tre byte consecutivi in memoria, e non quattro o cinque.
Indirizzamento indicizzato a pagina zero
L'indirizzamento dell'indice a pagina zero è come l'indirizzamento dell'indice assoluto descritto in precedenza, ma il byte di destinazione deve trovarsi solo sulla pagina zero (da $0000 a $00FF). Ora, quando si ha a che fare con la pagina zero, il byte più alto è sempre 00 H per le locazioni di memoria viene solitamente evitato. Quindi, normalmente si dice che la pagina zero inizia da $ 00 a FF. E quindi, l’istruzione precedente di “LDA $C453,X” è:
LDA $ 53,X
$C4, un byte più alto che si riferisce a una pagina sopra la pagina zero, non può essere utilizzato in questa istruzione poiché inserisce il byte di destinazione previsto da caricare nel byte accumulato all'esterno e sopra la pagina zero.
Quando il valore digitato nell'istruzione viene aggiunto al valore nel registro indice, la somma non deve dare un risultato superiore allo zero di pagina (FF H ). Quindi è fuori questione avere un’istruzione come “LDA $FF, X” e un valore come FF H nel registro indice perché FF H +FF H = 200 H che è la posizione del primo byte ($0200) della pagina 2 (terza pagina) nella memoria, è molto distante dalla pagina 0. Pertanto, con l'indirizzamento indicizzato a pagina zero, l'indirizzo effettivo deve trovarsi nella pagina zero.
Indirizzamento indiretto
Salta indirizzamento assoluto
Prima di discutere dell'indirizzamento indiretto assoluto, è bene esaminare l'indirizzamento assoluto di JMP. Supponiamo che l'indirizzo con il valore di interesse (byte di destinazione) sia $8765. Si tratta di 16 bit costituiti da due byte: il byte più alto che è 87 H e il byte inferiore che è 65 H . Quindi, i due byte per $8765 vengono inseriti nel PC (contatore del programma) per l'istruzione successiva. Ciò che viene digitato nel programma in linguaggio assembly (file) è:
JMP$8765
Il programma in esecuzione nella memoria salta da qualunque indirizzo abbia avuto accesso a $8765. Il mnemonico JMP ha tre codici operativi che sono 4C, 6C e 7C. Il codice operativo per questo indirizzamento assoluto è 4C. Il codice operativo per l'indirizzamento indiretto assoluto di JMP è 6C (fare riferimento alle illustrazioni seguenti).
Indirizzamento indiretto assoluto
Viene utilizzato solo con l'istruzione di salto (JMP). Supponiamo che l'indirizzo che contiene il byte di interesse (byte di destinazione) sia $8765. Si tratta di 16 bit costituiti da due byte: il byte più alto che è 87 H e il byte inferiore che è 65 H . Con l'indirizzamento indiretto assoluto, questi due byte si trovano effettivamente in due posizioni di byte consecutive altrove nella memoria.
Supponiamo che si trovino nelle posizioni di memoria $0210 e $0211. Quindi, il byte inferiore dell'indirizzo di interesse che è 65 H si trova nell'indirizzo $ 0210 e il byte più alto è 87 H si trova nell'indirizzo $ 0211. Ciò significa che il byte di memoria di interesse più basso va all’indirizzo consecutivo più basso, e il byte di memoria di interesse più alto va all’indirizzo consecutivo più alto – piccolo endianness.
L'indirizzo a 16 bit può riferirsi a due indirizzi consecutivi nella memoria. Alla luce di ciò, l'indirizzo $ 0210 si riferisce agli indirizzi di $ 0210 e $ 0211. La coppia di indirizzi $0210 e $0211 contiene l'indirizzo finale (16 bit di due byte) del byte di destinazione, con il byte inferiore di 65 H in $ 0210 e il byte più alto di 87 H a $ 0211. Quindi, l'istruzione di salto digitata è:
JMP ($ 0210)
Il mnemonico JMP ha tre codici operativi che sono 4C, 6C e 7C. Il codice operativo per l'indirizzamento indiretto assoluto è 6C. Ciò che viene digitato nel file di testo è “JMP ($0210)”. A causa delle parentesi, l'assemblatore (traduttore) utilizza il codice operativo 6C per JMP e non 4C o 7C.
Con l'indirizzamento indiretto assoluto ci sono in realtà tre regioni di memoria. La prima regione può essere costituita dalle posizioni dei byte $0200, $0201 e $0202. Questo contiene i tre byte per l'istruzione “JMP ($0210)”. La seconda regione, che non è necessariamente vicina alla prima, è costituita dalle due posizioni consecutive dei byte $0210 e $0211. È il byte più basso qui ($0210) che viene digitato nell'istruzione del programma in linguaggio assembly. Se l'indirizzo di interesse è $8765, il byte inferiore è 65 H si trova nella posizione del byte $0210 e il byte più alto è 87 H si trova nella posizione byte $0211. La terza regione è costituita da una sola posizione di byte. Si tratta dell'indirizzo $8765 per il byte di destinazione (ultimo byte di interesse). La coppia di indirizzi consecutivi, $0210 e $0211, contiene il puntatore $8765 che è l'indirizzo di interesse. Dopo l'interpretazione computazionale, sono $8765 che entrano nel PC (Program Counter) per accedere al byte di destinazione.
Indirizzamento indiretto a zero pagine
Questo indirizzamento è uguale all'indirizzamento indiretto assoluto, ma il puntatore deve trovarsi nella pagina zero. L'indirizzo del byte inferiore della regione del puntatore è ciò che si trova nell'istruzione digitata come segue:
JMP ($50)
Il byte più alto del puntatore si trova nella posizione $51 byte. L'indirizzo effettivo (puntato) non deve essere nella pagina zero.
Pertanto, con l'indirizzamento tramite indice, il valore in un registro indice viene aggiunto all'indirizzo di base fornito nell'istruzione per ottenere l'indirizzo effettivo. L'indirizzamento indiretto utilizza un puntatore.
4.8 Indirizzamento indiretto indicizzato
Indirizzamento indiretto indicizzato assoluto
Questa modalità di indirizzamento viene utilizzata solo con l'istruzione JMP.
Nell'indirizzamento indiretto assoluto si trova il valore puntato (byte) con i propri due indirizzi di byte consecutivi. Questi due indirizzi consecutivi formano il puntatore per trovarsi nella regione del puntatore di due byte consecutivi nella memoria. Il byte inferiore della regione del puntatore è ciò che viene digitato nell'istruzione tra parentesi. Il puntatore è l'indirizzo del valore puntato. Nella situazione precedente, $8765 è l'indirizzo del valore indicato. $0210 (seguito da $0211) è l'indirizzo il cui contenuto è $8765 che è il puntatore. Con la modalità di indirizzamento indiretto assoluto, nel programma (file di testo) viene digitato ($0210), comprese le parentesi.
D'altro canto, con la modalità di indirizzamento indiretto indicizzato assoluto, il byte di indirizzo inferiore per la regione del puntatore viene formato aggiungendo il valore nel registro X all'indirizzo digitato. Ad esempio, se il puntatore si trova nella posizione dell'indirizzo $ 0210, l'istruzione digitata potrebbe essere simile a questa:
JMP ($020A,X)
Dove il registro X ha valore 6 H . 020A H +6 H = 0210 H . Il registro Y non viene utilizzato con questa modalità di indirizzamento.
Indirizzamento indiretto indicizzato a pagina zero
Questa modalità di indirizzamento utilizza il registro X e non il registro Y. Con questa modalità di indirizzamento, sono ancora presenti il valore puntato e il puntatore nella relativa regione del puntatore dell'indirizzo a due byte. Devono esserci due byte consecutivi nella pagina zero per il puntatore. L'indirizzo digitato nell'istruzione è un indirizzo da un byte. Questo valore viene aggiunto al valore nel registro X e qualsiasi riporto viene scartato. Il risultato punta all'area del puntatore nella pagina 0. Ad esempio, se l'indirizzo di interesse (puntato) è $8765 e si trova nelle posizioni byte di $50 e $51 della pagina 0 e il valore nel registro X è $30, il l'istruzione digitata è qualcosa del genere:
LDA ($ 20,X)
Perché $ 20 + $ 30 = $ 50.
Indirizzamento indicizzato indiretto
Questa modalità di indirizzamento utilizza il registro Y e non il registro X. Con questa modalità di indirizzamento sono ancora presenti il valore puntato e la zona del puntatore, ma il contenuto della zona del puntatore funziona in modo diverso. Devono essere presenti due byte consecutivi nella pagina zero per la regione del puntatore. L'indirizzo inferiore della regione del puntatore viene digitato nell'istruzione. Questo numero (coppia di byte) contenuto nella regione del puntatore viene aggiunto al valore nel registro Y per ottenere il puntatore reale. Ad esempio, supponiamo che l'indirizzo di interesse (puntato) sia $8765, che il valore di 6H sia nel registro Y e che il numero (due byte) sia all'indirizzo di 50 H e 51 H . I due byte insieme valgono $875F poiché $875F + $6 = $8765. L'istruzione digitata è qualcosa del genere:
LDA ($50),Y
4.9 Istruzioni di incremento, decremento e test-BIT
La tabella seguente mostra le operazioni delle istruzioni di incremento e decremento:
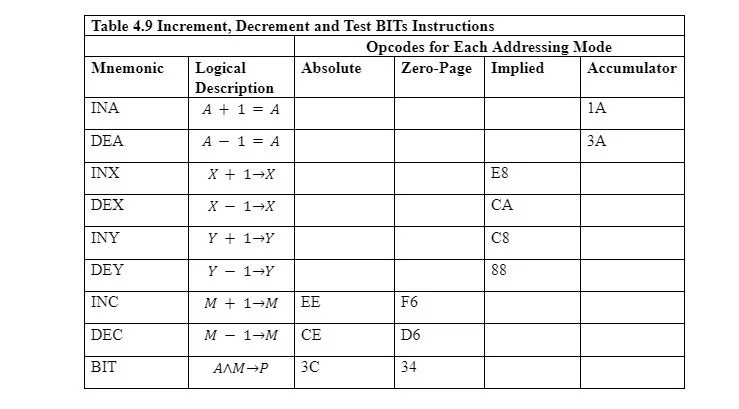
INA e DEA rispettivamente incrementano e decrementano l'accumulatore. Questo si chiama indirizzamento dell'accumulatore. INX, DEX, INY e DEY sono rispettivamente per i registri X e Y. Non accettano alcun operando. Pertanto, utilizzano la modalità di indirizzamento implicita. Incremento significa aggiungere 1 al registro o al byte di memoria. Decremento significa sottrarre 1 dal registro o dal byte di memoria.
INC e DEC incrementano e decrementano rispettivamente un byte di memoria (e non un registro). L'uso dell'indirizzamento a pagina zero invece dell'indirizzamento assoluto serve a risparmiare memoria per l'istruzione. L'indirizzamento a pagina zero è un byte in meno rispetto all'indirizzamento assoluto dell'istruzione in memoria. Tuttavia, la modalità di indirizzamento della pagina zero influisce solo sulla pagina zero.
L'istruzione BIT verifica i bit di un byte nella memoria con gli 8 bit nell'accumulatore, ma non modifica nessuno dei due. Sono impostati solo alcuni flag del Processor Status Register “P”. I bit della posizione di memoria specificata vengono collegati logicamente con quelli dell'accumulatore. Quindi vengono impostati i seguenti bit di stato:
- N che è il bit 7 e l'ultimo bit (a sinistra) del registro di stato, riceve il bit 7 della posizione di memoria prima dell'AND.
- V che è il bit 6 del registro di stato riceve il bit 6 della posizione di memoria prima dell'AND.
- Il flag Z del registro di stato viene impostato (reso 1) se il risultato dell'AND è zero (00000000 2 ). Altrimenti viene cancellato (reso 0).
4.10 Confronta le istruzioni
I mnemonici delle istruzioni di confronto per il 6502 µP sono CMP, CPX e CPY. Dopo ogni confronto, vengono influenzati i flag N, Z e C del registro di stato del processore “P”. Il flag N viene impostato (reso 1) quando il risultato è un numero negativo. Il flag Z viene impostato (reso 1) quando il risultato è zero (000000002). Il flag C viene impostato (reso 1) quando c'è un riporto dall'ottavo al nono bit. La tabella seguente fornisce un'illustrazione dettagliata
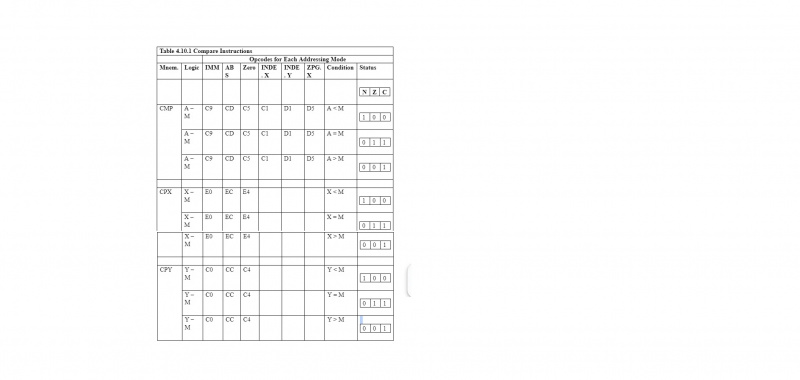
Il significato è “maggiore di”. Detto questo, la tabella di confronto dovrebbe essere autoesplicativa.
4.11 Istruzioni di salto e salto
La tabella seguente riassume le istruzioni di salto e diramazione:
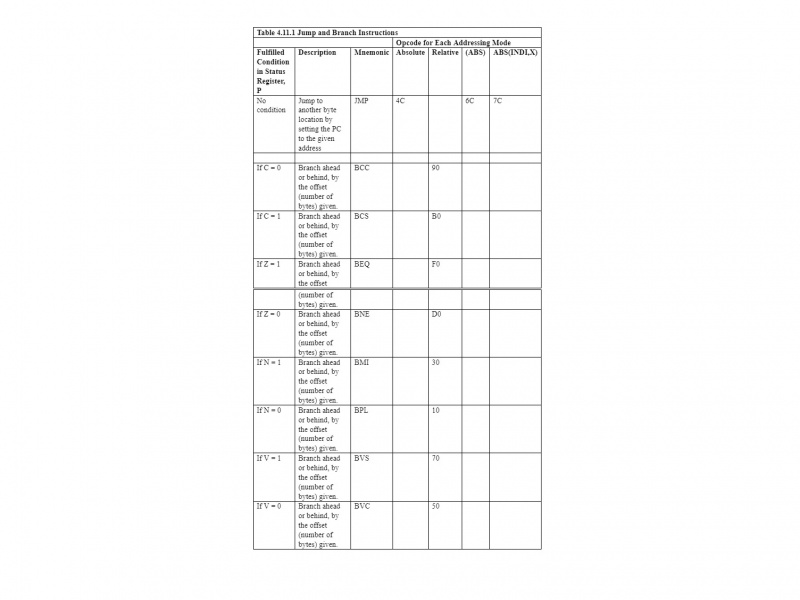
L'istruzione JMP utilizza l'indirizzamento assoluto e indiretto. Il resto delle istruzioni nella tabella sono istruzioni di salto. Con il 6502 µP utilizzano solo l'indirizzamento relativo. In questo modo la tabella diventa autoesplicativa se letta da sinistra a destra e dall'alto verso il basso.
Tieni presente che i rami possono essere applicati solo agli indirizzi compresi tra -128 e +127 byte dall'indirizzo specificato. Questo è un indirizzamento relativo. Sia per le istruzioni JMP che per quelle di salto, il Program Counter (PC) è direttamente interessato. Il 6502 µP non consente diramazioni ad indirizzo assoluto, anche se il salto può effettuare l'indirizzamento assoluto. L'istruzione JMP non è un'istruzione di salto.
Nota: L'indirizzamento relativo viene utilizzato solo con le istruzioni di salto.
4.12 L'area della pila
Una subroutine è come uno dei precedenti programmi brevi per aggiungere o sottrarre due numeri. L'area dello stack nella memoria inizia da $0100 a $01FF inclusi. Quest'area è chiamata semplicemente pila. Quando il microprocessore esegue un salto all'istruzione della subroutine (JSR – fare riferimento alla discussione seguente), deve sapere dove tornare una volta terminato. Il 6502 µP mantiene queste informazioni (indirizzo di ritorno) nella memoria bassa da $0100 a $01FF (l'area dello stack) e utilizza il contenuto del registro del puntatore dello stack che è 'S' nel microprocessore come puntatore (9 bit) all'ultimo indirizzo restituito che viene memorizzato nella pagina 1 (da $0100 a $01FF) della memoria. Lo stack diminuisce da $01FF e rende possibile annidare le subroutine fino a 128 livelli di profondità.
Un altro utilizzo dello stack pointer è gestire gli interrupt. Il 6502 µP ha i pin etichettati come IRQ e NMI. È possibile che alcuni piccoli segnali elettrici vengano applicati a questi pin e facciano sì che il 6502 µP interrompa l'esecuzione di un programma e ne inizi l'esecuzione di un altro. In questo caso il primo programma viene interrotto. Come le subroutine, i segmenti di codice di interruzione possono essere annidati. L'elaborazione degli interrupt viene discussa nel capitolo successivo.
Nota : Il puntatore dello stack ha 8 bit per l'indirizzo del byte inferiore nell'indirizzare le posizioni da $0100 a $01FF. Il byte più alto di 00000001 2 è assunto.
La tabella seguente fornisce le istruzioni che mettono in relazione il puntatore dello stack 'S' con i registri A, X, Y e P all'area dello stack nella memoria:
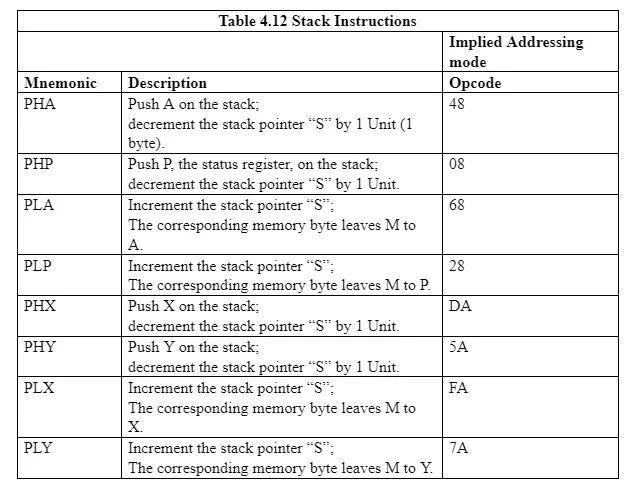
4.13 Chiamata e ritorno della subroutine
Una subroutine è un insieme di istruzioni che raggiungono un particolare obiettivo. Il precedente programma di addizione o sottrazione è una subroutine molto breve. Le subroutine sono talvolta chiamate semplicemente routine. L'istruzione per chiamare una subroutine è:
JSR: Passa alla subroutine
L'istruzione per ritornare da una subroutine è:
RTS: Ritorno dalla subroutine
Il microprocessore ha la tendenza ad eseguire continuamente le istruzioni presenti in memoria, una dopo l'altra. Supponiamo che il microprocessore stia attualmente eseguendo un segmento di codice e incontri un'istruzione di salto (JMP) per andare ad eseguire un segmento di codice che è codificato dietro il quale potrebbe già essere eseguito. Esegue quel segmento di codice dietro e continua a eseguire tutti i segmenti di codice (istruzioni) successivi al segmento di codice dietro, finché non riesegue nuovamente il segmento di codice corrente e continua di seguito. JMP non inserisce l'istruzione successiva nello stack.
A differenza di JMP, JSR inserisce nello stack l'indirizzo dell'istruzione successiva dal PC (contatore del programma). La posizione dello stack di questo indirizzo è posta nel puntatore dello stack 'S'. Quando un'istruzione RTS viene incontrata (eseguita) nella subroutine, l'indirizzo che viene inserito nello stack viene rimosso dallo stack e il programma riprende a quell'indirizzo estratto che è l'indirizzo dell'istruzione successiva appena prima della chiamata della subroutine. L'ultimo indirizzo rimosso dallo stack viene inviato al contatore del programma. Nella tabella seguente sono riportati i dettagli tecnici delle istruzioni JSR e RTS:

Vedere la seguente illustrazione per gli usi di JSR e RTS:
4.14 Esempio di ciclo di conto alla rovescia
La seguente subroutine conta alla rovescia da $FF a $00 (totale di 256 10 conta):
avvia LDX #$FF ; carica X con $FF = 255
ciclo DEX; X = X – 1
Ciclo BNE; se X non è zero, vai al ciclo
RTS; ritorno
Ogni riga ha un commento. I commenti non entrano mai nella memoria per l'esecuzione. L'assemblatore (traduttore) che converte un programma in quello che è nella memoria per l'esecuzione (in esecuzione) elimina sempre i commenti. Un commento inizia con “;” . L''inizio' e il 'ciclo' in questo programma sono chiamati etichette. Un'etichetta identifica (il nome) l'indirizzo dell'istruzione. Se l'istruzione è un'istruzione a byte singolo (indirizzamento implicito), l'etichetta è l'indirizzo di tale istruzione. Se l'istruzione è un'istruzione multibyte, l'etichetta identifica il primo byte dell'istruzione multibyte. La prima istruzione per questo programma è composta da due byte. Supponendo che inizi all'indirizzo $ 0300, l'indirizzo $ 0300 può essere sostituito con 'start' in basso nel programma. La seconda istruzione (DEX) è un'istruzione a byte singolo e dovrebbe trovarsi all'indirizzo $ 0302. Ciò significa che l'indirizzo $0302 può essere sostituito con “loop”, più in basso nel programma, cosa che in realtà è così nel “loop BNE”.
'Loop BNE' indica il passaggio all'indirizzo specificato quando il flag Z del registro di stato è 0. Quando il valore nel registro A o X o Y è 00000000 2 , a causa dell'ultima operazione, il flag Z è 1 (impostato). Quindi, anche se è 0 (non 1), la seconda e la terza istruzione del programma vengono ripetute in quest'ordine. In ogni sequenza ripetuta, il valore (numero intero) nel registro X viene diminuito di 1. DEX significa X = X – 1. Quando il valore nel registro X è $00 = 00000000 2 , Z diventa 1. A quel punto non vi è più ripetizione delle due istruzioni. L'ultima istruzione RTS nel programma, che è un'istruzione a byte singolo (indirizzamento implicito), ritorna dalla subroutine. L'effetto di questa istruzione è di inserire nello stack l'indirizzo del contatore del programma per il codice che deve essere eseguito prima della chiamata della subroutine e di tornare al contatore del programma (PC). Questo indirizzo è l'indirizzo dell'istruzione che deve essere eseguita prima che venga richiamata la subroutine.
Nota: Quando si scrive un programma in linguaggio assembly per il 6502 µP, solo un'etichetta deve iniziare all'inizio di una riga; eventuali altri codici di linea dovranno essere spostati di almeno uno spazio a destra.
Chiamare una subroutine
Ignorando lo spazio di memoria occupato dalle etichette precedenti, il programma occupa 6 byte di locazioni consecutive nella memoria (RAM) da $ 0300 a $ 0305. In questo caso il programma è:
LDX #$FF ; carica X con $FF = 255
DES ; X = X – 1
BNE$0302; se X non è zero, vai al ciclo
RTS; ritorno
A partire dall'indirizzo $0200 in memoria può avvenire la chiamata alla subroutine. L'istruzione di chiamata è:
Inizio JSR; l'inizio è l'indirizzo $ 0300, ovvero JSR $ 0300
La subroutine e la sua chiamata scritte correttamente nel file dell'editor di testo sono:
avvia LDX #$FF; carica X con $FF = 255
ciclo DEX; X = X – 1
Ciclo BNE; se X non è zero, vai al ciclo
RTS; ritorno
Inizio JSR: passa alla routine a partire da $ 0300
Ora, possono esserci molte subroutine in un lungo programma. Non tutti possono avere il nome “inizio”. Dovrebbero avere nomi diversi. In effetti, nessuno di loro potrebbe avere il nome “inizio”. “Start” viene utilizzato qui per ragioni didattiche.
4.15 Traduzione di un programma
Tradurre un programma o assemblarlo significa la stessa cosa. Consideriamo il seguente programma:
avvia LDX #$FF : carica X con $FF = 255
ciclo DEX: X = X – 1
Ciclo BNE: se X non è zero, vai al ciclo
RTS: ritorno
Inizio JSR: passa alla routine a partire da $ 0300
Questo è il programma scritto in precedenza. Consiste nella subroutine, nell'avvio e nella chiamata alla subroutine. Il programma conta alla rovescia da 255 10 a 0 10 . Il programma inizia all'indirizzo iniziale dell'utente di $ 0200 (RAM). Il programma viene digitato in un editor di testo e salvato sul disco. Ha un nome del tipo “sample.asm” dove “sample” è il nome scelto dal programmatore ma al nome del file deve essere associata l’estensione “.asm” per il linguaggio assembly.
Il programma assemblato è prodotto da un altro programma chiamato assemblatore. L'assemblatore è fornito dal produttore del 6502 µP o da terzi. L'assembler riproduce il programma in modo tale che sia nella memoria (RAM) mentre viene eseguito (run).
Supponiamo che l'istruzione JSR inizi all'indirizzo $ 0200 e che la subroutine inizi all'indirizzo $ 0300. L'assemblatore rimuove tutti i commenti e gli spazi bianchi. I commenti e gli spazi bianchi sprecano la memoria che è sempre scarsa. Una possibile riga vuota tra il segmento di codice della subroutine precedente e la chiamata della subroutine è un esempio di spazio bianco. Il file assemblato è ancora salvato sul disco e ha un nome simile a 'sample.exe'. Il “sample” è il nome scelto dal programmatore, ma dovrebbe esserci l’estensione “.exe” per indicare che si tratta di un file eseguibile.
Il programma assemblato può essere documentato come segue:
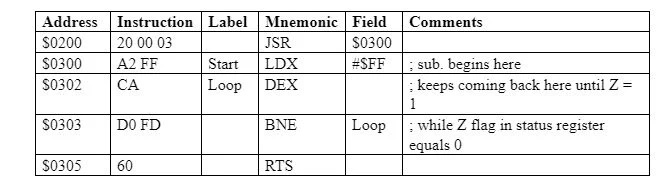
Si dice che produrre un documento come questo significhi assemblarlo a mano. Da notare che i commenti contenuti in questo documento non appaiono in memoria (per l'esecuzione). La colonna degli indirizzi nella tabella indica gli indirizzi iniziali delle istruzioni in memoria. Si noti che 'JSR start' ovvero 'JSR $0300', che dovrebbe essere codificato come '20 03 00', è in realtà codificato come '20 00 03' con l'indirizzo del byte di memoria inferiore che prende il byte inferiore nella memoria e il indirizzo di byte di memoria più alto che prende il byte più alto in memoria – piccolo endianness. Il codice operativo per JSR è 20 16 .
Si noti che l’offset di un’istruzione di salto come BNE è un numero in complemento a due compreso tra 128 10 a +127 10 . Quindi, “loop BNE” significa “BNE -1 10 ” che in realtà è “D0 FF” nella forma in codice di FF 16 è -1 in complemento a due che si scrive = 11111111 in base due. Il programma assembler sostituisce le etichette e i campi con i numeri esadecimali effettivi (i numeri esadecimali sono numeri binari raggruppati in quattro bit). Gli indirizzi effettivi in cui inizia ciascuna istruzione sono effettivamente inclusi.
Nota: L'istruzione “JSR start” è sostituita da istruzioni più brevi che inviano il contenuto corrente (byte alti e bassi) del program counter allo stack con il puntatore dello stack che viene decrementato due volte (una volta per il byte alto e una volta per il byte basso) e quindi ricarica il PC con l'indirizzo $0300. Lo stack pointer ora punta a $00FD, presupponendo che sia inizializzato a $01FF.
Inoltre, l'istruzione RTS è sostituita da una serie di istruzioni più brevi che incrementano il puntatore dello stack 'S' due volte (una volta per il byte basso e una volta per il byte alto) e prelevano i due byte di indirizzo corrispondenti dal puntatore dello stack al PC per l'istruzione successiva.
Nota: Il testo di un'etichetta non deve contenere più di 8 caratteri.
“Loop BNE” utilizza il relativo indirizzamento. Significa aggiungere -3 10 al contenuto del contatore del programma successivo di $ 0305. I byte per 'loop BNE' sono 'D0 FD' dove FD è il complemento a due di -3 10 .
Nota: questo capitolo non presenta tutte le istruzioni per il 6502 µP. Tutte le istruzioni ed i relativi dettagli sono reperibili nel documento intitolato “Famiglia di microprocessori a 8 bit SY6500”. Per questo documento esiste un file PDF con il nome “6502.pdf” che è liberamente disponibile in Internet. Il 6502 µP descritto in questo documento è 65C02.
4.16 Interruzioni
I segnali di qualsiasi dispositivo collegato alle porte esterne (superficie verticale) del Commodore 64 devono passare attraverso i circuiti CIA 1 o CIA 2 (IC) prima di raggiungere il microprocessore 6502. I segnali provenienti dal bus dati del 6502 µP devono passare attraverso il chip CIA 1 o CIA 2 prima di raggiungere qualsiasi dispositivo esterno. CIA sta per Complex Interface Adapter. Nella Fig 4.1 “Diagramma a blocchi della scheda madre Commodore_64”, i dispositivi di ingresso/uscita del blocco rappresentano CIA 1 e CIA 2. Quando un programma è in esecuzione, può essere interrotto per eseguire qualche altro pezzo di codice prima di continuare. C'è un'interruzione dell'hardware e un'interruzione del software. Per l'interruzione dell'hardware, sono presenti due pin del segnale di ingresso nel 6502 µP. I nomi di questi pin sono IRQ E NMI . Queste non sono linee dati µP. Le linee dati per il µP sono D7, D6, D5, D4, D3, D2, D1 e D0; con D0 per il bit meno significativo e D7 per il bit più significativo.
IRQ sta per Interrupt ReQuest “attivo” basso. Questa linea di ingresso al µP è normalmente alta, a circa 5 volt. Quando scende a circa 0 volt, si tratta di una richiesta di interruzione che segnala il µP. Non appena la richiesta viene accolta la linea torna alta. Concedere la richiesta di interruzione significa che µP si dirama al codice (subroutine) che gestisce l'interruzione.
NMI sta per Interrupt non mascherabile “attivo” basso. Mentre il codice per IRQ viene eseguito NMI può scendere. In questo caso, NMI viene gestito (viene eseguito il proprio codice). Successivamente, il codice per IRQ continua. Dopo il codice per IRQ termina, il codice del programma principale continua. Questo è, NMI interrompe il IRQ gestore. Il segnale per NMI può ancora essere dato al µP anche quando il µP è inattivo e non sta gestendo nulla o non sta eseguendo un programma principale.
Nota: In realtà è il passaggio dall'alto al basso, di NMI , questo è il NMI segnale – ne parleremo più avanti. IRQ normalmente proviene dalla CIA 1 e NMI normalmente proviene dalla CIA 2. NMI , che sta per Non-Maskable Interrupt, può essere considerato un'interruzione non-arrestabile.
Gestione degli interrupt
Se la richiesta proviene da IRQ O NMI , l'istruzione corrente deve essere completata. Il 6502 ha solo i registri A, X e Y. Mentre una subroutine è in funzione, potrebbe utilizzare questi tre registri insieme. Un gestore di interruzioni è ancora una subroutine, sebbene non vista come tale. Una volta completata l'istruzione corrente, il contenuto dei registri A, X e Y per il 65C02 µP viene salvato nello stack. Allo stack viene inviato anche l'indirizzo della successiva istruzione del Program Counter. Il µP quindi si ramifica al codice per l'interruzione. Successivamente, il contenuto dei registri A, X e Y viene ripristinato dallo stack nell'ordine inverso a cui è stato inviato.
Esempio di codifica per un interrupt
Per semplicità, supponiamo che la routine per µP IRQ l'interruzione consiste semplicemente nell'aggiungere i numeri $01 e $02 e salvare il risultato di $03 nell'indirizzo di memoria di $0400. Il codice è:
ISR PHA
PHX
FIS
;
LDA #$01
ADC #$02
COSTANO $ 0400
;
PLY
PLX
PLA
RTI
ISR è un'etichetta e identifica l'indirizzo di memoria in cui si trova l'istruzione PHA. ISR significa Interrupt Service Routine. PHA, PHX e PHY inviano il contenuto dei registri A, X e Y allo stack con la speranza che siano necessari a qualunque codice (programma) sia in esecuzione appena prima dell'interruzione. Le tre istruzioni successive costituiscono il nucleo del gestore degli interrupt. Le istruzioni PLY, PLX e PLA devono essere in quest'ordine e riportano il contenuto dei registri Y, X e A. L'ultima istruzione, che è RTI, (senza operando) restituisce la continuazione dell'esecuzione a qualunque codice (programma) sia in esecuzione prima dell'interruzione. RTI recupera l'indirizzo della successiva istruzione del codice in esecuzione dallo stack al contatore del programma. RTI significa Ritorno dall'interruzione. Con ciò la gestione degli interrupt (subroutine) è terminata.
Interruzione del software
Il modo principale per avere un interrupt software per il 6502 µP è utilizzare l'istruzione di indirizzo implicito BRK. Supponiamo che il programma principale sia in esecuzione e incontri l'istruzione BRK. Da quel momento, l'indirizzo dell'istruzione successiva nel PC dovrebbe essere inviato allo stack man mano che l'istruzione corrente viene completata. Una subroutine per gestire l'istruzione del software dovrebbe essere chiamata 'successivo'. Questa subroutine di interrupt dovrebbe spingere i contenuti dei registri A, X e Y nello stack. Dopo che il nucleo della subroutine è stato eseguito, il contenuto dei registri A, X e Y dovrebbe essere riportato dallo stack ai rispettivi registri dal completamento della subroutine. L'ultima istruzione nella routine è RTI. Anche il contenuto del PC viene ritirato automaticamente dallo stack al PC grazie a RTI.
Confronto e contrasto tra subroutine e routine di servizio di interruzione
La seguente tabella confronta e contrappone la subroutine e la routine del servizio di interruzione:

4.17 Riepilogo delle modalità di indirizzamento principali del 6502
Ogni istruzione per il 6502 è un byte, seguita da zero o più operandi.
Modalità di indirizzamento immediato
Con la modalità di indirizzamento immediato, dopo l'operando, c'è il valore e non un indirizzo di memoria. Il valore deve essere preceduto da #. Se il valore è in esadecimale il “#” deve essere seguito da “$”. Le istruzioni di indirizzamento immediate per il 65C02 sono: ADC, AND, BIT, CMP, CPX, CPY, EOR, LDA, LDX, LDY, ORA, SBC. Il lettore dovrebbe consultare la documentazione del 65C02 µP per sapere come utilizzare le istruzioni qui elencate che non sono spiegate in questo capitolo. Un'istruzione di esempio è:
LDA #$77
Modalità di indirizzamento assoluto
Nella modalità di indirizzamento assoluto è presente un solo operando. Questo operando è l'indirizzo del valore in memoria (solitamente in formato esadecimale o etichetta). Ci sono 64K 10 = 65.536 10 indirizzi di memoria per il 6502 µP. In genere, il valore di un byte si trova in uno di questi indirizzi. Le istruzioni di indirizzamento assoluto per il 65C02 sono: ADC, AND, ASL, BIT, CMP, CPX, CPY, DEC, EOR, INC, JMP, JSR, LDA, LDX, LDY, LSR, ORA, ROL, ROR, SBC, STA , STX, STY, STZ, TRB, TSB. Il lettore dovrebbe consultare la documentazione del 65C02 µP per sapere come utilizzare le istruzioni qui elencate, così come per le altre modalità di indirizzamento che non sono spiegate in questo capitolo. Un'istruzione di esempio è:
SONO $ 1234
Modalità di indirizzamento implicita
Nella modalità di indirizzamento implicito non è presente alcun operando. Qualsiasi registro µP coinvolto è implicito nell'istruzione. Le istruzioni di indirizzamento implicite per il 65C02 sono: BRK, CLC, CLD, CLI, CLV, DEX, DEY, INX, INY, NOP, PHA, PHP, PHX, PHY, PLA, PLP, PLX, PLY, RTI, RTS, SEC , SED, SEI, IMPOSTA, TAY, TSX, TXA, TXS, TYA. Un'istruzione di esempio è:
DEX: decrementa il registro X di una unità.
Modalità di indirizzamento relativo
La modalità di indirizzamento relativo si occupa solo delle istruzioni di salto. Nella modalità di indirizzamento relativo è presente un solo operando. È un valore compreso tra -128 10 a +127 10 . Questo valore è chiamato offset. In base al segno, questo valore viene aggiunto o sottratto dalla successiva istruzione del Program Counter per ottenere l'indirizzo dell'istruzione successiva prevista. Le relative istruzioni di modalità indirizzo sono: BCC, BCS, BEQ, BMI, BNE, BPL, BRA, BVC, BVS. Gli esempi di istruzioni sono:
BNE $7F: (diramazione se Z = 0 nel registro di stato, P)
Che aggiunge 127 al contatore del programma corrente (indirizzo da eseguire) e inizia l'esecuzione dell'istruzione a quell'indirizzo. Allo stesso modo:
BEQ $F9 : (diramazione se Z = : nel registro di stato, P)
Che aggiunge un -7 al contatore del programma corrente e avvia l'esecuzione al nuovo indirizzo del contatore del programma. L’operando è un numero in complemento a due.
Indirizzamento indicizzato assoluto
Nell'indirizzamento con indice assoluto, il contenuto del registro X o Y viene aggiunto all'indirizzo assoluto fornito (da $0000 a $FFFF, ovvero da 0 10 a 65536 10 ) per avere l'indirizzo reale. Questo dato indirizzo assoluto è chiamato indirizzo di base. Se viene utilizzato il registro X, l'istruzione di assembly è simile a questa:
LDA$C453,X
Se viene utilizzato il registro Y, è qualcosa del tipo:
LDA$C453,Y
Il valore per il registro X o Y è chiamato valore di conteggio o indice e può essere qualsiasi valore compreso tra $ 00 (0 10 ) a $FF (250 10 ). Non si chiama offset.
Le istruzioni di indirizzamento dell'indice assoluto sono: ADC, AND, ASL (solo X), BIT (con accumulatore e memoria, solo con X), CMP, DEC (solo memoria e X), EOR, INC (solo memoria e X), LDA , LDX, LDY, LSR (solo X), ORA, ROL (solo X), ROR (solo X), SBC, STA, STZ (solo X).
Indirizzamento indiretto assoluto
Viene utilizzato solo con l'istruzione di salto. In questo modo l'indirizzo assoluto indicato ha un indirizzo puntatore. L'indirizzo del puntatore è composto da due byte. Il puntatore a due byte punta al (è l'indirizzo del) valore del byte di destinazione nella memoria. Quindi, l'istruzione in linguaggio assembly è:
JMP ($3456)
Con le parentesi, $13 è nella posizione dell'indirizzo di $3456 mentre $EB è nella posizione dell'indirizzo di $3457 (= $3456 + 1). Quindi, l'indirizzo di destinazione è $13EB e $13EB è il puntatore. Il valore assoluto $ 3456 è tra parentesi nell'istruzione dove 34 è il byte più basso e 56 è il byte più alto.
4.18 Creazione di una stringa con il linguaggio assembly 6502 µP
Come dimostrato nel capitolo successivo, dopo aver creato un file in memoria, il file può essere salvato su disco. È necessario assegnare un nome al file. Il nome è un esempio di stringa. Ci sono molti altri esempi di stringhe nella programmazione.
Esistono due modi principali per creare una stringa di codici ASCII. In entrambi i modi, tutti i codici ASCII (caratteri) occupano posizioni di byte consecutive in memoria. In uno dei modi, questa sequenza di byte è preceduta da un byte intero che rappresenta la lunghezza (numero di caratteri) nella sequenza (stringa). Nell'altro modo, la sequenza di caratteri è seguita (immediatamente seguita) dal byte Null che è 00 16 , ovvero $ 00. La lunghezza della stringa (numero di caratteri) non viene indicata in questo altro modo. Il carattere Null non viene utilizzato nel primo modo.
Ad esempio, considera il messaggio 'Ti amo!' stringa senza virgolette. La lunghezza qui è 11; uno spazio conta come un byte ASCII (carattere). Supponiamo che la stringa debba essere inserita in memoria con il primo carattere all'indirizzo $0300.
La tabella seguente mostra l'impostazione della memoria della stringa quando il primo byte è 11 10 = 0B 16 :
La tabella seguente mostra l'impostazione della memoria della stringa quando il primo byte è 'I' e l'ultimo byte è Null ($00):
È possibile utilizzare la seguente istruzione per iniziare a creare la stringa:
COSTANO $ 0300
Supponiamo che il primo byte sia nell'accumulatore che deve essere inviato all'indirizzo $0300. Questa istruzione è vera in entrambi i casi (entrambi i tipi di stringhe).
Dopo aver inserito tutti i caratteri nelle celle di memoria, uno per uno, la stringa può essere letta utilizzando un loop. Nel primo caso viene letto il numero di caratteri dopo la lunghezza. Nel secondo caso, i caratteri vengono letti da “I” finché non viene incontrato il carattere Null che è “Null”.
4.19 Creazione di un array con il linguaggio assembly 6502 µP
Un array di numeri interi a byte singolo è costituito da posizioni consecutive di byte di memoria con i numeri interi. Quindi, c'è un puntatore che punta alla posizione del primo numero intero. Quindi un array di numeri interi è composto da due parti: il puntatore e la serie di posizioni.
Per un array di stringhe, ciascuna stringa può trovarsi in una posizione diversa nella memoria. Quindi, ci sono posizioni di memoria consecutive con puntatori in cui ciascun puntatore punta alla prima posizione di ciascuna stringa. Un puntatore in questo caso è composto da due byte. Se una stringa inizia con la sua lunghezza, il puntatore corrispondente punta alla posizione di quella lunghezza. Se una stringa non inizia con la sua lunghezza ma termina con un carattere nullo, il puntatore corrispondente punta alla posizione del primo carattere della stringa. E c'è un puntatore che punta all'indirizzo del byte inferiore del primo puntatore di puntatori consecutivi. Quindi, un array di stringhe è composto da tre parti: le stringhe in punti diversi della memoria, i puntatori consecutivi corrispondenti e il puntatore al primo puntatore dei puntatori consecutivi.
4.20 Problemi
Si consiglia al lettore di risolvere tutti i problemi in un capitolo prima di passare al capitolo successivo.
- Scrivere un programma in linguaggio assembly che inizi da $0200 per 6502 µP e aggiunga i numeri senza segno di 2A94 H (aggiungere) a 2ABF H (augud). Lascia che gli input e l'output siano nella memoria. Inoltre, produrre manualmente il documento del programma assemblato.
- Scrivere un programma in linguaggio assembly che inizi da $0200 per 6502 µP e sottragga i numeri senza segno di 1569 H (sottraendo) da 2ABF H (minuendo). Lascia che gli input e gli output siano nella memoria. Inoltre, produrre manualmente il documento del programma assemblato.
- Scrivere un programma in linguaggio assembly per il 6502 µP che conti da $00 a $09 utilizzando un ciclo. Il programma dovrebbe iniziare a $ 0200. Inoltre, produrre manualmente il documento del programma assemblato.
- Scrivere un programma in linguaggio assembly che inizi a $ 0200 per il 6502 µP. Il programma ha due subroutine. La prima subroutine aggiunge i numeri senza segno di 0203 H (augend) e 0102H (add). La seconda subroutine aggiunge la somma della prima subroutine che è 0305H a 0006 H (augud). Il risultato finale viene archiviato nella memoria. Chiama la prima subroutine che è FSTSUB e la seconda subroutine che è SECSUB. Lascia che gli input e gli output siano nella memoria. Inoltre, produrre manualmente il documento di programma assemblato per l'intero programma.
- Dato che un IRQ il gestore aggiunge $ 02 a $ 01 all'accumulatore come gestione principale mentre NMI viene rilasciato e la gestione principale per NMI aggiunge $ 05 a $ 04 all'accumulatore, scrivi un linguaggio assembly per entrambi i gestori comprese le loro chiamate. La chiamata al IRQ il gestore dovrebbe trovarsi all'indirizzo $ 0200. IL IRQ il gestore dovrebbe iniziare all'indirizzo $ 0300. IL NMI il gestore dovrebbe iniziare all'indirizzo $ 0400. Il risultato del IRQ handler dovrebbe essere inserito all'indirizzo $0500 e il risultato del file NMI il gestore dovrebbe essere inserito all'indirizzo $ 0501.
- Spiegare brevemente come viene utilizzata l'istruzione BRK per produrre l'interruzione software in un computer 65C02.
- Produrre una tabella che confronti e contrasti una normale subroutine con una routine di servizio di interruzione.
- Spiegare brevemente le principali modalità di indirizzamento del 65C02 µP utilizzando gli esempi di istruzioni in linguaggio assembly.
- a) Scrivere un programma in linguaggio macchina 6502 per inserire la frase “Ti amo!” stringa di codici ASCII presenti in memoria, a partire dall'indirizzo $0300 con la lunghezza della stringa. Il programma dovrebbe iniziare all'indirizzo $ 0200. Ottieni ciascun carattere dall'accumulatore uno per uno, supponendo che vengano inviati lì, da qualche subroutine. Inoltre, assemblare il programma a mano. (Se hai bisogno di conoscere i codici ASCII del “ti amo!”. Eccoli: ‘I’:49 16 , spazio: 20 16 , ‘l’: 6C 16 , 'o':6F 16 , 'in':76 16 , 'e':65, 'y':79 16 , 'in':75 16 , e ‘!’:21 16 (Nota: ogni codice occupa 1 byte).
b) Scrivere un programma in linguaggio macchina 6502 per inserire la frase 'Ti amo!' stringa di codici ASCII presenti in memoria, a partire dall'indirizzo $0300 senza la lunghezza della stringa ma terminante con 00 16 . Il programma dovrebbe iniziare all'indirizzo $ 0200. Ottieni ciascun carattere dall'accumulatore, supponendo che vengano inviati lì, uno per uno, da qualche subroutine. Inoltre, assemblare il programma a mano.